


[ad_1]
The Dynamic Retrieval Augmented Technology (RAG) paradigm goals to enhance the efficiency of LLMs by figuring out when to retrieve exterior data and what to retrieve throughout textual content era. Present strategies usually depend on static guidelines to determine when to get well and restrict retrieval to latest sentences or tokens, which can not seize the total context. This method dangers introducing irrelevant knowledge and rising computation prices unnecessarily. Efficient methods for optimum retrieval timing and crafting related queries are important to reinforce LLM era whereas mitigating these challenges.
Researchers from Tsinghua College and the Beijing Institute of Know-how have developed DRAGIN, a Dynamic Retrieval Augmented Technology framework tailor-made to LLMs. DRAGIN dynamically determines when and what to retrieve primarily based on real-time data wants throughout textual content era. It introduces RIND for timing retrieval, contemplating LLM uncertainty and token significance, and QFS for question formulation, leveraging self-attention throughout the context. DRAGIN outperforms present strategies throughout 4 knowledge-intensive datasets with out requiring extra coaching or immediate engineering.
Single-round retrieval-augmented strategies improve LLMs by incorporating exterior data retrieved utilizing the preliminary enter as a question. Earlier research extensively discover this method, akin to REPLUG, which makes use of LLMs to generate coaching knowledge for retrieval fashions, and UniWeb, which self-assesses the necessity for retrieval. Nonetheless, multi-round retrieval turns into important for advanced duties requiring intensive exterior data. Strategies like RETRO and IC-RALM set off retrieval at fastened intervals, however FLARE innovatively triggers retrieval upon encountering unsure tokens, bettering retrieval relevance by contemplating the LLM’s real-time data wants.
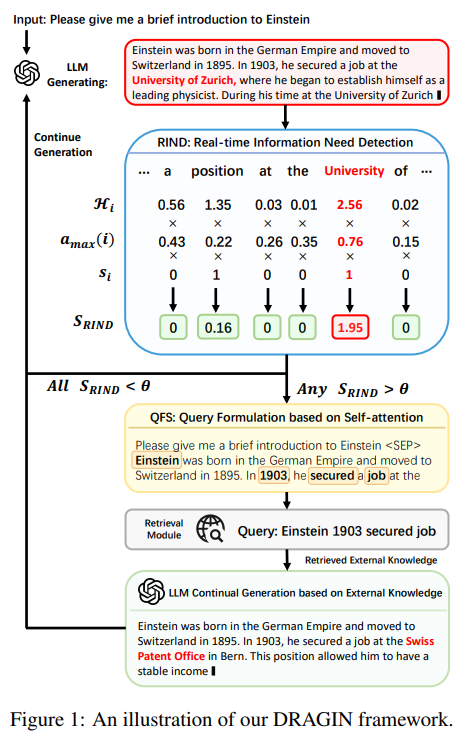
The DRAGIN framework includes two key elements: Actual-time Info Wants Detection (RIND) and Question Formulation primarily based on Self-attention (QFS). RIND evaluates tokens’ uncertainty, semantic significance, and affect on subsequent context to set off retrieval dynamically. QFS formulates queries by analyzing the LLM’s self-attention mechanism, prioritizing tokens primarily based on their relevance to the present context. After retrieval, the framework truncates the output on the recognized token, integrates retrieved data utilizing a designed immediate template, and generates resumes. This iterative course of ensures the LLM seamlessly incorporates related exterior data, enhancing its output’s high quality and relevance.
The efficiency of DRAGIN was evaluated towards varied baseline strategies throughout 4 datasets, and the experimental outcomes had been in contrast. DRAGIN constantly outperformed different strategies, demonstrating its effectiveness in enhancing LLMs. Effectivity evaluation revealed that DRAGIN required fewer retrieval calls than some baselines, indicating its effectivity. Timing evaluation confirmed DRAGIN’s superiority in figuring out optimum retrieval moments primarily based on real-time data wants. DRAGIN’s question formulation technique outperformed different frameworks, emphasizing its means to pick out tokens representing LLM’s data wants precisely. Moreover, BM25 outperformed SGPT as a retrieval technique, suggesting the continued effectiveness of lexicon-based approaches in RAG duties.
In conclusion, DRAGIN is a framework addressing limitations in dynamic RAG strategies for LLMs. DRAGIN improves retrieval activation timing with RIND and enhances question formulation precision utilizing QFS, main to higher efficiency on knowledge-intensive duties. Regardless of its reliance on Transformer-based LLMs’ self-attention mechanism, DRAGIN demonstrates effectiveness. Future work goals to beat limitations associated to self-attention accessibility. DRAGIN integrates exterior data by truncating LLM output for retrieval augmentation and incorporating retrieved data utilizing a immediate template. The affect of question formulation strategies is evaluated, with DRAGIN surpassing different strategies like FLARE, FL-RAG, and FS-RAG.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our newsletter..
Don’t Neglect to hitch our 39k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is keen about making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.
[ad_2]
Source link
