


[ad_1]
The capabilities of LLMs are advancing quickly, evidenced by their efficiency throughout varied benchmarks in arithmetic, science, and coding duties. Concurrently, developments in Reinforcement Studying from Human Suggestions (RLHF) and instruction fine-tuning are aligning LLMs extra carefully with human preferences. This progress enhances the obvious skills of LLMs, making advanced behaviors extra accessible by instruction prompting. Revolutionary prompting methods like Chain-of-Thought or Tree-of-Ideas additional increase LLM reasoning. Drawing from successes in RL strategies seen in gaming environments, integrating RL into LLM reasoning represents a pure development, leveraging interactive problem-solving dynamics for enhanced efficiency.
Researchers from Meta, Georgia Institute of Know-how, StabilityAI, and UC Berkeley have investigated varied RL algorithms’ effectiveness in enhancing the reasoning capabilities of LLMs throughout various reward schemes, mannequin sizes, and initializations. Professional Iteration (EI) persistently outperforms different strategies, displaying aggressive pattern effectivity. EI’s efficiency approaches that of extra advanced algorithms like Proximal Coverage Optimization (PPO), even requiring fewer samples for convergence. The research highlights the importance of RL fine-tuning in bridging the efficiency hole between pre-trained and supervised fine-tuned LLMs. Exploration emerges as a important issue impacting RL fine-tuning efficacy for LLMs, with implications for RL from Human Suggestions and the way forward for LLM fine-tuning.
Varied research showcase the rising prowess of LLMs in tackling advanced reasoning duties, supported by developments like CoT and Tree of Thought strategies. These strategies allow LLMs to defer last solutions by producing intermediate computations. Combining LLMs with planning algorithms and instruments additional enhances their reasoning capabilities. RLHF is a outstanding methodology for fine-tuning LLMs, whereas knowledgeable iteration algorithms present comparable efficiency. Regardless of in depth analysis in RL for LLM enchancment, understanding probably the most impactful elements nonetheless must be found.
Researchers strategy reasoning duties for LLMs as RL issues, analyzing the efficiency and pattern complexity of assorted RL algorithms for fine-tuning LLMs. The research analyzes EI, PPO, and Return-Conditioned RL (RCRL). Every algorithm goals to maximise the anticipated future return of a scholar coverage on a given process. The research particulars the methodologies of PPO, EI, and RCRL, together with exploration methods, coaching procedures, and reward mechanisms. Researchers additionally current outcomes from experiments carried out with these algorithms on reasoning duties, showcasing their effectiveness in bettering LLM efficiency.
Experiments on GSM8K and SVAMP datasets consider varied fashions utilizing completely different metrics. Supervised fine-tuning (SFT) information is utilized initially, adopted by experiments with out SFT information. EI outperforms different strategies, displaying a big enchancment over the baseline. EI fashions carry out higher than PPO fashions regardless of additional coaching. Outcomes point out that RL fine-tuning, notably EI, supplies higher generalization and variety in answer paths than static SFT fine-tuning. Bigger fashions have interaction in additional various exploration, impacting mannequin efficiency throughout coaching. These findings make clear the effectiveness of RL fine-tuning in bettering mannequin efficiency and generalization.
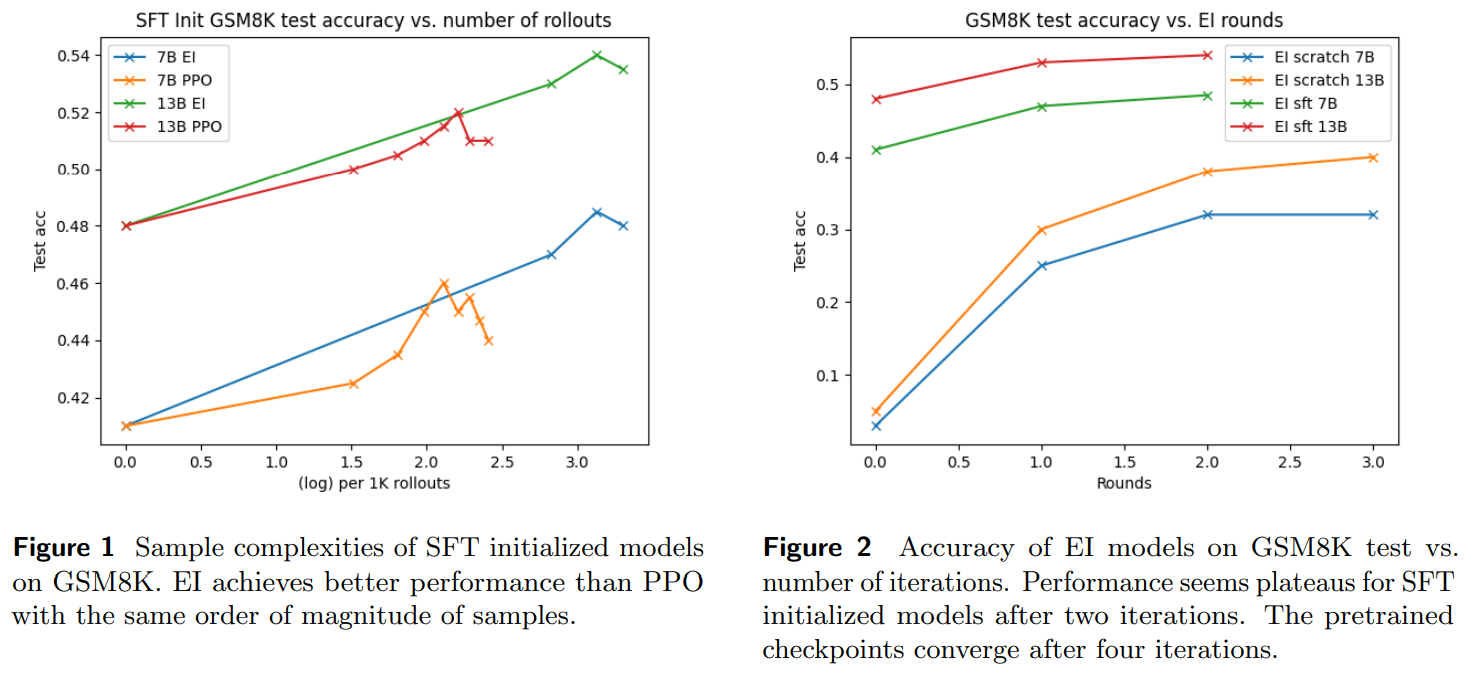
In conclusion, the research findings point out that EI outperforms different RL algorithms in reasoning duties. EI and PPO converge shortly with out supervised fine-tuning, benefiting little from extra steerage or denser rewards. RL fine-tuning improves single- and multi-step accuracy, leveraging dynamic artificial information technology. The research highlights the significance of pretrained fashions in enabling exploration and suggests limitations in present exploration methods. Additional developments in prompting strategies and mannequin exploration are essential for bettering Language Mannequin reasoning capabilities.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and Google News. Be part of our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our newsletter..
Don’t Neglect to hitch our Telegram Channel
You may additionally like our FREE AI Courses….
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is obsessed with making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.
[ad_2]
Source link
