


[ad_1]
Within the realm of reasoning duties, massive language fashions (LLMs) have displayed exceptional efficiency when supplied with examples and intermediate steps. Nonetheless, approaches that depend upon implicit data inside an LLM can generally produce inaccurate solutions when the implicit data is inaccurate or inconsistent with the duty at hand.
To handle this subject, a workforce of researchers from Google, Mila – Québec AI Insitute, Université de Montréal, HEC Montréal, College of Alberta, and CIFAR AI Chair introduce the Hypotheses-to-Theories (HtT) framework that focuses on buying a rule library for LLM-based reasoning. HtT includes two key phases: an induction stage and a deduction stage. Within the induction stage, an LLM is initially tasked with producing and validating guidelines based mostly on a set of coaching examples.
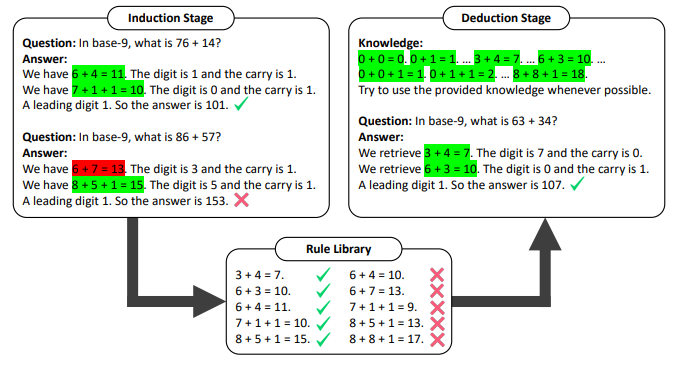
The above picture demonstrates the appliance of Hypotheses-to-Theories to the chain-of-thought technique for fixing base-9 arithmetic issues is exemplified right here. To keep up conciseness, a few-shot examples have been omitted. Within the induction stage, the Chain of Thought (CoT) approach is utilized to generate guidelines and validate them utilizing coaching samples.
Subsequently, the principles produced are gathered and refined to assemble a rule library. Within the deduction stage, the CoT immediate is enhanced with data derived from the rule library. Appropriate guidelines are indicated with inexperienced markers, whereas incorrect ones are marked in crimson. Guidelines that regularly result in right solutions are accrued to ascertain a rule library. Within the deduction stage, the LLM is subsequently prompted to make the most of the acquired rule library for reasoning with a purpose to reply check questions.
Of their analysis of HtT, the researchers combine it as an enhancement to pre-existing few-shot prompting methods, akin to chain-of-thought and least-to-most prompting. Efficiency is assessed on two difficult multi-step reasoning issues which have confirmed to be problematic for present few-shot prompting approaches.
Experimental outcomes on each numerical reasoning and relational reasoning issues reveal that HtT enhances current prompting strategies, attaining a rise in accuracy starting from 11% to 27%. Moreover, the acquired guidelines may be successfully transferred to completely different fashions and numerous types of the identical drawback. The launched technique paves the best way for a novel method to buying textual data utilizing LLMs. It’s anticipated that HtT will allow a spread of purposes and encourage additional analysis within the subject of LLMs.
Take a look at the Paper. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t overlook to hitch our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
We’re additionally on WhatsApp. Join our AI Channel on Whatsapp..
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming information scientist and has been working on the earth of ml/ai analysis for the previous two years. She is most fascinated by this ever altering world and its fixed demand of people to maintain up with it. In her pastime she enjoys touring, studying and writing poems.
[ad_2]
Source link
