


[ad_1]
Within the quickly evolving discipline of audio synthesis, a brand new frontier has been crossed with the event of Secure Audio, a state-of-the-art generative mannequin. This modern strategy has considerably superior our capability to create detailed, high-quality audio from textual prompts. In contrast to its predecessors, Secure Audio can produce long-form, stereo music, and sound results which might be each excessive in constancy and variable in size, addressing a longstanding problem within the area.
The crux of Secure Audio’s methodology lies in its distinctive mixture of a completely convolutional variational autoencoder and a diffusion mannequin, each conditioned on textual content prompts and timing embeddings. This novel conditioning permits for unprecedented management over the audio’s content material and period, enabling the technology of complicated audio narratives that carefully adhere to their textual descriptions. Together with timing embeddings is groundbreaking, because it permits for producing audio with exact lengths, a function that has eluded earlier fashions.
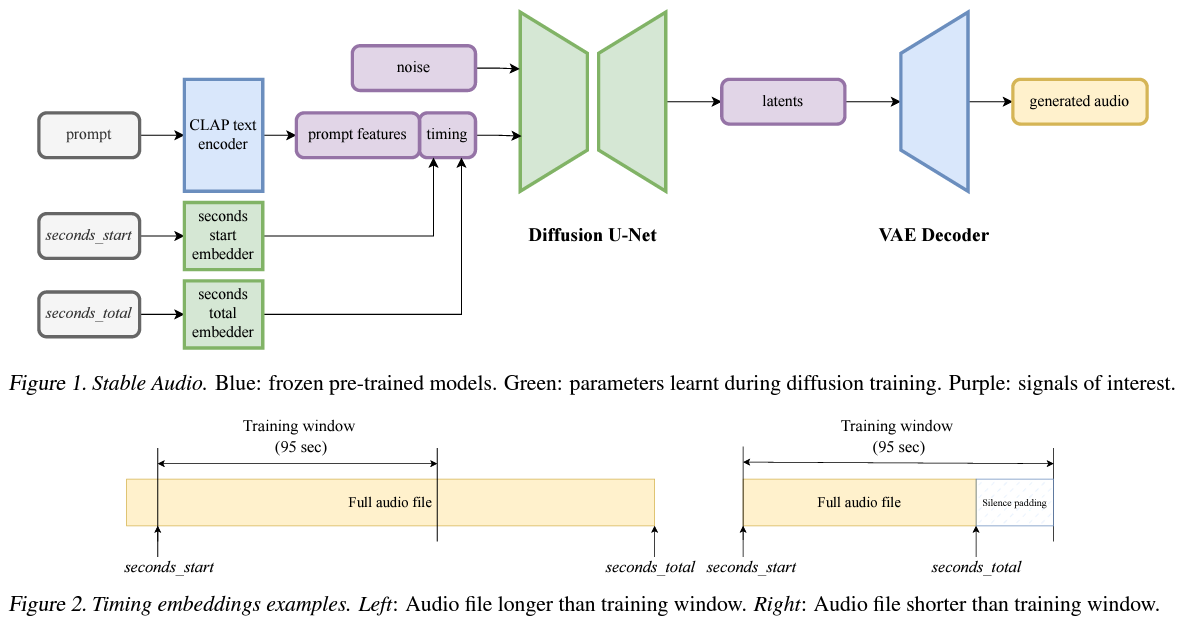
Efficiency-wise, Secure Audio units a brand new benchmark in audio technology effectivity and high quality. It might probably render as much as 95 seconds of stereo audio at 44.1kHz in simply eight seconds on an A100 GPU. This leap in efficiency doesn’t come at the price of high quality; quite the opposite, Secure Audio demonstrates superior constancy and construction within the generated audio. It achieves this by leveraging a latent diffusion course of inside a extremely compressed latent area, enabling speedy technology with out sacrificing element or texture.
To scrupulously consider Secure Audio’s efficiency, the analysis crew launched novel metrics designed to evaluate long-form, full-band stereo audio. These metrics measure the plausibility of generated audio, the semantic correspondence between the audio and the textual content prompts, and the diploma to which the audio adheres to the offered descriptions. By these measures, Secure Audio persistently outperforms present fashions, showcasing its capability to generate audio that’s reasonable and high-quality and precisely displays the nuances of the enter textual content.
One of the putting features of Secure Audio’s efficiency is its capability to provide audio with a transparent construction—full with introductions, developments, and conclusions—whereas sustaining stereo integrity. This functionality considerably advances earlier fashions, which regularly struggled to generate coherent long-form content material or protect stereo high quality over prolonged durations.
In abstract, Secure Audio represents a big leap ahead in audio synthesis, bridging the hole between textual prompts and high-fidelity, structured audio. Its modern strategy to audio technology opens up new prospects for inventive expression, multimedia manufacturing, and automatic content material creation, setting a brand new customary for what is feasible in text-to-audio synthesis.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and Google News. Be a part of our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our newsletter..
Don’t Neglect to hitch our Telegram Channel
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a deal with Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical information with sensible purposes. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.
[ad_2]
Source link
