

[ad_1]
Many fashionable machine studying algorithms have numerous hyperparameters. To successfully use these algorithms, we have to choose good hyperparameter values.
On this article, we discuss Bayesian Optimization, a set of strategies typically used to tune hyperparameters. Extra typically, Bayesian Optimization can be utilized to optimize any black-box operate.
Allow us to begin with the instance of gold mining. Our objective is to mine for gold in an unknown land
For now, we assume that the gold is distributed a couple of line. We wish to discover the placement alongside this line with the utmost gold whereas solely drilling a number of instances (as drilling is pricey).
Allow us to suppose that the gold distribution seems to be one thing just like the operate under. It’s bi-modal, with a most worth round . For now, allow us to not fear in regards to the X-axis or the Y-axis models.

Initially, we do not know in regards to the gold distribution. We will study the gold distribution by drilling at totally different areas. Nevertheless, this drilling is expensive. Thus, we wish to reduce the variety of drillings required whereas nonetheless discovering the placement of most gold shortly.
We now talk about two widespread aims for the gold mining downside.
-
Downside 1: Greatest Estimate of Gold Distribution (Lively Studying)
On this downside, we wish to precisely estimate the gold distribution on the brand new land. We can’t drill at each location as a result of prohibitive price. As an alternative, we must always drill at areas offering excessive info in regards to the gold distribution. This downside is akin to
Lively Studying
. -
Downside 2: Location of Most Gold (Bayesian Optimization)
On this downside, we wish to discover the placement of the utmost gold content material. We, once more, can’t drill at each location. As an alternative, we must always drill at areas exhibiting excessive promise in regards to the gold content material. This downside is akin to
Bayesian Optimization
.
We are going to quickly see how these two issues are associated, however not the identical.
Lively Studying
For a lot of machine studying issues, unlabeled information is available. Nevertheless, labeling (or querying) is commonly costly. For example, for a speech-to-text job, the annotation requires skilled(s) to label phrases and sentences manually. Equally, in our gold mining downside, drilling (akin to labeling) is pricey.
Lively studying minimizes labeling prices whereas maximizing modeling accuracy. Whereas there are numerous strategies in lively studying literature, we take a look at uncertainty discount. This technique proposes labeling the purpose whose mannequin uncertainty is the best. Usually, the variance acts as a measure of uncertainty.
Since we solely know the true worth of our operate at a number of factors, we want a surrogate mannequin for the values our operate takes elsewhere. This surrogate needs to be versatile sufficient to mannequin the true operate. Utilizing a Gaussian Course of (GP) is a standard alternative, each due to its flexibility and its capacity to provide us uncertainty estimates
Gaussian Course of helps setting of priors through the use of particular kernels and imply capabilities. One would possibly wish to take a look at this glorious Distill article
Please discover this superb video from Javier González on Gaussian Processes.
.
Our surrogate mannequin begins with a previous of — within the case of gold, we choose a previous assuming that it’s easily distributed
Specifics: We use a Matern 5/2 kernel as a consequence of its property of favoring doubly differentiable capabilities. See Rasmussen and Williams 2004 and scikit-learn, for particulars relating to the Matern kernel.
As we consider factors (drilling), we get extra information for our surrogate to study from, updating it in response to Bayes’ rule.

Within the above instance, we began with uniform uncertainty. However after our first replace, the posterior is definite close to and unsure away from it. We may simply hold including extra coaching factors and procure a extra sure estimate of .
Nevertheless, we wish to reduce the variety of evaluations. Thus, we must always select the subsequent question level “well” utilizing lively studying. Though there are various methods to choose good factors, we can be choosing probably the most unsure one.
This offers us the next process for Lively Studying:
- Select and add the purpose with the best uncertainty to the coaching set (by querying/labeling that time)
- Prepare on the brand new coaching set
- Go to #1 until convergence or funds elapsed
Allow us to now visualize this course of and see how our posterior adjustments at each iteration (after every drilling).

The visualization reveals that one can estimate the true distribution in a number of iterations. Moreover, probably the most unsure positions are sometimes the farthest factors from the present analysis factors. At each iteration, lively studying explores the area to make the estimates higher.
Bayesian Optimization
Within the earlier part, we picked factors with the intention to decide an correct mannequin of the gold content material. However what if our objective is just to search out the placement of most gold content material? In fact, we may do lively studying to estimate the true operate precisely after which discover its most. However that appears fairly wasteful — why ought to we use evaluations bettering our estimates of areas the place the operate expects low gold content material after we solely care in regards to the most?
That is the core query in Bayesian Optimization: “Primarily based on what we all know thus far, which level ought to we consider subsequent?” Keep in mind that evaluating every level is pricey, so we wish to choose rigorously! Within the lively studying case, we picked probably the most unsure level, exploring the operate. However in Bayesian Optimization, we have to stability exploring unsure areas, which could unexpectedly have excessive gold content material, in opposition to specializing in areas we already know have greater gold content material (a form of exploitation).
We make this resolution with one thing referred to as an acquisition operate. Acquisition capabilities are heuristics for the way fascinating it’s to guage a degree, primarily based on our current mannequin
This brings us to how Bayesian Optimization works. At each step, we decide what one of the best level to guage subsequent is in response to the acquisition operate by optimizing it. We then replace our mannequin and repeat this course of to find out the subsequent level to guage.
It’s possible you’ll be questioning what’s “Bayesian” about Bayesian Optimization if we’re simply optimizing these acquisition capabilities. Nicely, at each step we preserve a mannequin describing our estimates and uncertainty at every level, which we replace in response to Bayes’ rule
Formalizing Bayesian Optimization
Allow us to now formally introduce Bayesian Optimization. Our objective is to search out the placement () akin to the worldwide most (or minimal) of a operate .
We current the final constraints in Bayesian Optimization and distinction them with the constraints in our gold mining instance
.
Common Constraints |
Constraints in Gold Mining instance |
|---|---|
| ’s possible set is easy, e.g., field constraints. |
Our area within the gold mining downside is a single-dimensional field constraint: . |
| is steady however lacks particular construction, e.g., concavity, that might make it straightforward to optimize. |
Our true operate is neither a convex nor a concave operate, leading to native optimums. |
| is derivative-free: evaluations don’t give gradient info. |
Our analysis (by drilling) of the quantity of gold content material at a location didn’t give us any gradient info. |
| is pricey to guage: the variety of instances we will consider it is severely restricted. |
Drilling is expensive. |
| could also be noisy. If noise is current, we are going to assume it’s impartial and usually distributed, with widespread however unknown variance. | We assume noiseless measurements in our modeling (although, it’s straightforward to include usually distributed noise for GP regression). |
To unravel this downside, we are going to comply with the next algorithm:
- We first select a surrogate mannequin for modeling the true operate and outline its prior.
- Given the set of observations (operate evaluations), use Bayes rule to acquire the posterior.
- Use an acquisition operate , which is a operate of the posterior, to determine the subsequent pattern level .
- Add newly sampled information to the set of observations and goto step #2 until convergence or funds elapses.
Acquisition Capabilities
Acquisition capabilities are essential to Bayesian Optimization, and there are all kinds of choices
Please discover these slides from Washington College in St. Louis to know extra about acquisition capabilities.
Likelihood of Enchancment (PI)
This acquisition operate chooses the subsequent question level because the one which has the best likelihood of enchancment over the present max . Mathematically, we write the number of subsequent level as follows,
the place,
- signifies likelihood
- is a small constructive quantity
- And, the place is the placement queried at time step.
Wanting intently, we’re simply discovering the upper-tail likelihood (or the CDF) of the surrogate posterior. Furthermore, if we’re utilizing a GP as a surrogate the expression above converts to,
the place,
- signifies the CDF
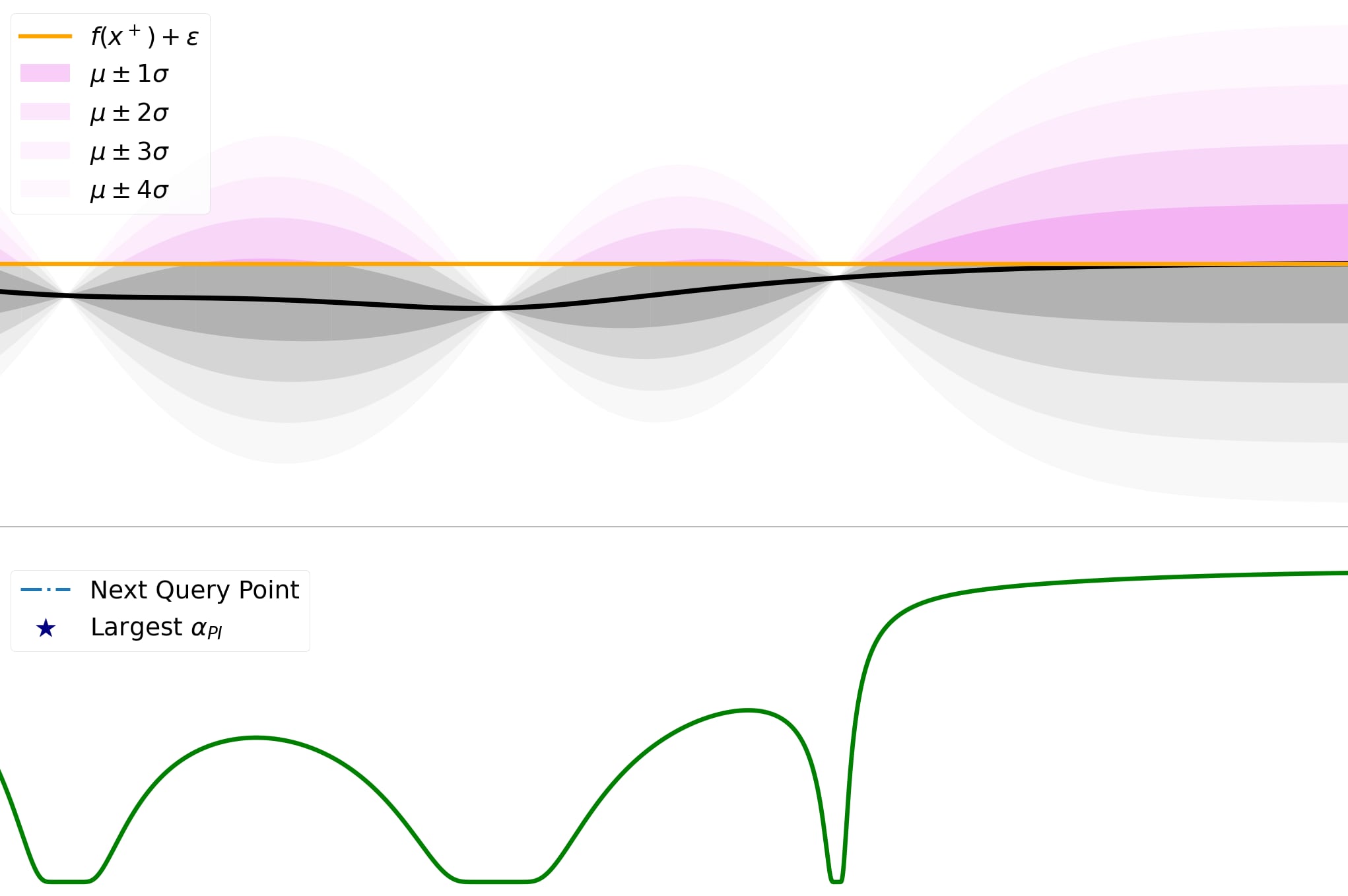
The visualization under reveals the calculation of . The orange line represents the present max (plus an ) or . The violet area reveals the likelihood density at every level. The gray areas present the likelihood density under the present max. The “space” of the violet area at every level represents the “likelihood of enchancment over present most”. The subsequent level to guage by way of the PI standards (proven in dashed blue line) is .

Instinct behind in PI
PI makes use of to strike a stability between exploration and exploitation.
Growing ends in querying areas with a bigger as their likelihood density is unfold.
Allow us to now see the PI acquisition operate in motion. We begin with .

Wanting on the graph above, we see that we attain the worldwide maxima in a number of iterations
Our surrogate possesses a big uncertainty in within the first few iterations
The acquisition operate initially exploits areas with a excessive promise

The visualization above reveals that growing to 0.3, permits us to discover extra. Nevertheless, evidently we’re exploring greater than required.
What occurs if we improve a bit extra?

We see that we made issues worse! Our mannequin now makes use of , and we’re unable to take advantage of after we land close to the worldwide most. Furthermore, with excessive exploration, the setting turns into much like lively studying.
Our fast experiments above assist us conclude that controls the diploma of exploration within the PI acquisition operate.
Anticipated Enchancment (EI)
Likelihood of enchancment solely checked out how probably is an enchancment, however, didn’t take into account how a lot we will enhance. The subsequent criterion, referred to as Anticipated Enchancment (EI), does precisely that
The thought is pretty easy — select the subsequent question level because the one which has the best anticipated enchancment over the present max , the place and is the placement queried at time step.
On this acquisition operate, question level, , is chosen in response to the next equation.
The place, is the precise floor reality operate, is the posterior imply of the surrogate at timestep, is the coaching information and is the precise place the place takes the utmost worth.
In essence, we are attempting to pick out the purpose that minimizes the space to the target evaluated on the most. Sadly, we have no idea the bottom reality operate, . Mockus
the next acquisition operate to beat the difficulty.
the place is the utmost worth that has been encountered thus far. This equation for GP surrogate is an analytical expression proven under.
the place signifies CDF and signifies pdf.
From the above expression, we will see that Anticipated Enchancment can be excessive when: i) the anticipated worth of is excessive, or, ii) when the uncertainty round a degree is excessive.
Just like the PI acquisition operate, we will reasonable the quantity of exploration of the EI acquisition operate by modifying .

For we come near the worldwide maxima in a number of iterations.
We now improve to discover extra.

As we anticipated, growing the worth to makes the acquisition operate discover extra. In comparison with the sooner evaluations, we see much less exploitation. We see that it evaluates solely two factors close to the worldwide maxima.
Allow us to improve much more.

Is that this higher than earlier than? It seems a sure and a no; we explored an excessive amount of at and shortly reached close to the worldwide maxima. However sadly, we didn’t exploit to get extra good points close to the worldwide maxima.
We’ve got seen two intently associated strategies, The Likelihood of Enchancment and the Anticipated Enchancment.

The scatter plot above reveals the insurance policies’ acquisition capabilities evaluated on totally different factors
We see that and attain a most of 0.3 and round 0.47, respectively. Selecting a degree with low and excessive interprets to excessive threat
In case of a number of factors having the identical , we must always prioritize the purpose with lesser threat (greater ). Equally, when the chance is similar (similar ), we must always select the purpose with better reward (greater ).
Thompson Sampling
One other widespread acquisition operate is Thompson Sampling
Under now we have a picture exhibiting three sampled capabilities from the discovered surrogate posterior for our gold mining downside. The coaching information constituted the purpose and the corresponding purposeful worth.

We will perceive the instinct behind Thompson sampling by two observations:
-
Places with excessive uncertainty () will present a big variance within the purposeful values sampled from the surrogate posterior. Thus, there’s a non-trivial likelihood {that a} pattern can take excessive worth in a extremely unsure area. Optimizing such samples can assist exploration.
For example, the three samples (pattern #1, #2, #3) present a excessive variance near . Optimizing pattern 3 will assist in exploration by evaluating .
-
The sampled capabilities should go by way of the present max worth, as there isn’t a uncertainty on the evaluated areas. Thus, optimizing samples from the surrogate posterior will guarantee exploiting conduct.
For example of this conduct, we see that each one the sampled capabilities above go by way of the present max at . If have been near the worldwide maxima, then we might be capable of exploit and select a greater most.

The visualization above makes use of Thompson sampling for optimization. Once more, we will attain the worldwide optimum in comparatively few iterations.
Random
We’ve got been utilizing clever acquisition capabilities till now.
We will create a random acquisition operate by sampling
randomly.

The visualization above reveals that the efficiency of the random acquisition operate shouldn’t be that unhealthy! Nevertheless, if our optimization was extra complicated (extra dimensions), then the random acquisition would possibly carry out poorly.
Abstract of Acquisition Capabilities
Allow us to now summarize the core concepts related to acquisition capabilities: i) they’re heuristics for evaluating the utility of a degree; ii) they’re a operate of the surrogate posterior; iii) they mix exploration and exploitation; and iv) they’re cheap to guage.
Different Acquisition Capabilities
We’ve got seen numerous acquisition capabilities till now. One trivial option to provide you with acquisition capabilities is to have a discover/exploit mixture.
Higher Confidence Sure (UCB)
One such trivial acquisition operate that mixes the exploration/exploitation tradeoff is a linear mixture of the imply and uncertainty of our surrogate mannequin. The mannequin imply signifies exploitation (of our mannequin’s data) and mannequin uncertainty signifies exploration (as a consequence of our mannequin’s lack of observations).
The instinct behind the UCB acquisition operate is weighing of the significance between the surrogate’s imply vs. the surrogate’s uncertainty. The above is the hyperparameter that may management the choice between exploitation or exploration.
We will additional type acquisition capabilities by combining the prevailing acquisition capabilities although the bodily interpretability of such mixtures may not be so simple. One cause we’d wish to mix two strategies is to beat the constraints of the person strategies.
Likelihood of Enchancment + Anticipated Enchancment (EI-PI)
One such mixture is usually a linear mixture of PI and EI.
We all know PI focuses on the likelihood of enchancment, whereas EI focuses on the anticipated enchancment. Such a mixture may assist in having a tradeoff between the 2 primarily based on the worth of .
Gaussian Course of Higher Confidence Sure (GP-UCB)
Earlier than speaking about GP-UCB, allow us to shortly discuss remorse. Think about if the utmost gold was models, and our optimization as an alternative samples a location containing models, then our remorse is
. If we accumulate the remorse over iterations, we get what is known as cumulative remorse.
GP-UCB’s
The place is the timestep.
Srinivas et. al.
Comparability
We now evaluate the efficiency of various acquisition capabilities on the gold mining downside
slides from Nando De Freitas
We ran the random acquisition operate a number of instances with totally different seeds and plotted the imply gold sensed at each iteration.

The random technique is initially corresponding to or higher than different acquisition capabilities
Hyperparameter Tuning
Earlier than we discuss Bayesian optimization for hyperparameter tuning
In Ridge regression, the burden matrix is the parameter, and the regularization coefficient is the hyperparameter.
If we clear up the above regression downside by way of gradient descent optimization, we additional introduce one other optimization parameter, the educational fee .
The commonest use case of Bayesian Optimization is hyperparameter tuning: discovering one of the best performing hyperparameters on machine studying fashions.
When coaching a mannequin shouldn’t be costly and time-consuming, we will do a grid search to search out the optimum hyperparameters. Nevertheless, grid search shouldn’t be possible if operate evaluations are expensive, as within the case of a big neural community that takes days to coach. Additional, grid search scales poorly by way of the variety of hyperparameters.
We flip to Bayesian Optimization to counter the costly nature of evaluating our black-box operate (accuracy).
Instance 1 — Assist Vector Machine (SVM)
On this instance, we use an SVM to categorise on sklearn’s moons dataset and use Bayesian Optimization to optimize SVM hyperparameters.
-
— modifies the conduct of the SVM’s kernel. Intuitively it’s a measure of the affect of a single coaching instance
StackOverflow answer for instinct behind the hyperparameters. . - — modifies the slackness of the classification, the upper the is, the extra delicate is SVM in direction of the noise.
Allow us to take a look on the dataset now, which has two lessons and two options.

Allow us to apply Bayesian Optimization to study one of the best hyperparameters for this classification job

Above we see a slider exhibiting the work of the Likelihood of Enchancment acquisition operate to find one of the best hyperparameters.

Above we see a slider exhibiting the work of the Anticipated Enchancment acquisition operate to find one of the best hyperparameters.
Comparability
Under is a plot that compares the totally different acquisition capabilities. We ran the random acquisition operate a number of instances to common out its outcomes.

All our acquisition beat the random acquisition operate after seven iterations. We see the random technique appeared to carry out significantly better initially, but it surely couldn’t attain the worldwide optimum, whereas Bayesian Optimization was capable of get pretty shut. The preliminary subpar efficiency of Bayesian Optimization will be attributed to the preliminary exploration.
Instance 2 — Random Forest
Utilizing Bayesian Optimization in a Random Forest Classifier.
We are going to proceed now to coach a Random Forest on the moons dataset we had used beforehand to study the Assist Vector Machine mannequin. The first hyperparameters of Random Forests we want to optimize our accuracy are the quantity of
Choice Bushes we want to have, the most depth for every of these resolution bushes.
The parameters of the Random Forest are the person skilled Choice Bushes fashions.
We can be once more utilizing Gaussian Processes with Matern kernel to estimate and predict the accuracy operate over the 2 hyperparameters.

Above is a typical Bayesian Optimization run with the Likelihood of Enchancment acquisition operate.

Above we see a run exhibiting the work of the Anticipated Enchancment acquisition operate in optimizing the hyperparameters.

Now utilizing the Gaussian Processes Higher Confidence Sure acquisition operate in optimizing the hyperparameters.

Allow us to now use the Random acquisition operate.

The optimization methods appeared to battle on this instance. This may be attributed to the non-smooth floor reality. This reveals that the effectiveness of Bayesian Optimization relies on the surrogate’s effectivity to mannequin the precise black-box operate. It’s fascinating to note that the Bayesian Optimization framework nonetheless beats the random technique utilizing numerous acquisition capabilities.
Instance 3 — Neural Networks
Allow us to take this instance to get an concept of the best way to apply Bayesian Optimization to coach neural networks. Right here we can be utilizing scikit-optim, which additionally gives us assist for optimizing operate with a search house of categorical, integral, and actual variables. We won’t be plotting the bottom reality right here, as this can be very expensive to take action. Under are some code snippets that present the convenience of utilizing Bayesian Optimization packages for hyperparameter tuning.
The code initially declares a search house for the optimization downside. We restrict the search house to be the next:
-
batch_size — This hyperparameter units the variety of coaching examples to mix to search out the gradients for a single step in gradient descent.
Our search house for the attainable batch sizes consists of integer values s.t. batch_size = . -
studying fee — This hyperparameter units the stepsize with which we are going to carry out gradient descent within the neural community.
We can be looking out over all the true numbers within the vary . - activation — We can have one categorical variable, i.e. the activation to use to our neural community layers. This variable can tackle values within the set .
log_batch_size = Integer(
low=2,
excessive=7,
identify=”log_batch_size”
)
lr = Actual(
low=1e-6,
excessive=1e0,
prior=”log-uniform”,
identify=”lr”
)
activation = Categorical(
classes=[‘relu’, ‘sigmoid’],
identify=”activation”
)
dimensions = [
dim_num_batch_size_to_base,
dim_learning_rate,
dim_activation
]
Now import gp-minimizescikit-optim.scikit-optim to carry out the optimization. Under we present calling the optimizer utilizing Anticipated Enchancment, however in fact we will choose from a variety of different acquisition capabilities.
# preliminary parameters (1st level)
default_parameters =
[4, 1e-1, ‘relu’]
# bayesian optimization
search_result = gp_minimize(
func=practice,
dimensions=dimensions,
acq_func=”EI”, # Expctd Imprv.
n_calls=11,
x0=default_parameters
)

Within the graph above the y-axis denotes one of the best accuracy until then, and the x-axis denotes the analysis quantity.
Wanting on the above instance, we will see that incorporating Bayesian Optimization shouldn’t be troublesome and may save a variety of time. Optimizing to get an accuracy of almost one in round seven iterations is spectacular!scikit-optim.
Allow us to get the numbers into perspective. If we had run this optimization utilizing a grid search, it could have taken round iterations. Whereas Bayesian Optimization solely took seven iterations. Every iteration took round fifteen minutes; this units the time required for the grid search to finish round seventeen hours!
On this article, we checked out Bayesian Optimization for optimizing a black-box operate. Bayesian Optimization is effectively suited when the operate evaluations are costly, making grid or exhaustive search impractical. We appeared on the key parts of Bayesian Optimization. First, we appeared on the notion of utilizing a surrogate operate (with a previous over the house of goal capabilities) to mannequin our black-box operate. Subsequent, we appeared on the “Bayes” in Bayesian Optimization — the operate evaluations are used as information to acquire the surrogate posterior. We take a look at acquisition capabilities, that are capabilities of the surrogate posterior and are optimized sequentially. This new sequential optimization is in-expensive and thus of utility of us. We additionally checked out a number of acquisition capabilities and confirmed how these totally different capabilities stability exploration and exploitation. Lastly, we checked out some sensible examples of Bayesian Optimization for optimizing hyper-parameters for machine studying fashions.
We hope you had fun studying the article and hope you might be able to exploit the ability of Bayesian Optimization. In case you want to discover extra, please learn the Further Reading part under. We additionally present our repository to breed your complete article.
[ad_2]
Source link
