


[ad_1]

Picture by freepik.com
In real-world knowledge science tasks, the information used for evaluation might include a number of imperfections such because the presence of lacking knowledge, redundant knowledge, knowledge entries having incorrect format, presence of outliers within the knowledge, and so forth. Information cleansing refers back to the means of preprocessing and reworking uncooked knowledge to render it in a type that’s appropriate for additional evaluation similar to for descriptive evaluation (knowledge visualization) or prescriptive evaluation (mannequin constructing). Clear, correct, and dependable knowledge should be utilized for publish evaluation as a result of “unhealthy knowledge results in unhealthy predictive fashions”.
A number of libraries in Python, together with pandas and numpy, can be utilized for knowledge cleansing and transformation. These libraries supply a variety of strategies and capabilities to hold out duties together with coping with lacking values, eliminating outliers, and translating knowledge right into a model-friendly format. Moreover, eliminating redundant options or combining teams of extremely correlated options right into a single function might result in dimensionality discount. Coaching a mannequin utilizing a dataset with fewer options will enhance the computational effectivity of the mannequin. Moreover, a mannequin constructed utilizing a dataset having fewer options is less complicated to interpret and has higher predictive energy.
On this article, we are going to discover varied instruments and methods which can be accessible in Python for cleansing, processing, and reworking knowledge. We are going to display knowledge cleansing methods utilizing the knowledge.cvs dataset proven beneath:
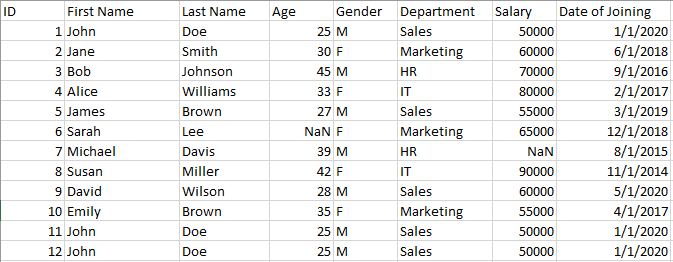
knowledge.csv displaying varied imperfections similar to duplicated knowledge, NaN, and so forth. Information created by Writer.
In Python, a spread of libraries and instruments, together with pandas and NumPy, could also be used to wash up knowledge. As an example, the dropna(), drop duplicates(), and fillna() capabilities in pandas could also be used to handle lacking knowledge, take away lacking knowledge, and take away duplicate rows, respectively. The scikit-learn toolkit presents instruments for coping with outliers (such because the SimpleImputer class) and reworking knowledge right into a format that may be utilized by a mannequin, such because the StandardScaler class for standardizing normalizing numerical knowledge, and the MinMaxScalar for normalizing knowledge.
On this article, we are going to discover varied knowledge cleansing methods that can be utilized in Python to organize and preprocess knowledge to be used in a machine studying mannequin.
The processing of lacking knowledge is likely one of the most essential imperfections in a dataset. A number of strategies for coping with lacking knowledge are supplied by the pandas bundle in Python, together with dropna() and fillna(). The dropna() methodology is used to remove any columns or rows which have lacking values. As an example, the code beneath will remove all rows with at the very least one lacking worth:
import pandas as pd
knowledge = pd.read_csv('knowledge.csv')
knowledge = knowledge.dropna()
The fillna() operate can be utilized to fill in lacking values with a selected worth or methodology. For instance, the next code will fill in lacking values within the ‘age’ column with the imply age of the information:
import pandas as pd
knowledge = pd.read_csv('knowledge.csv')
knowledge['age'].fillna(knowledge['age'].imply(), inplace=True)
Dealing with outliers is a typical knowledge cleansing exercise. Values that diverge vastly from the remainder of the information are thought-about outliers. These components must be managed fastidiously since they’ve a major affect on a mannequin’s efficiency. The RobustScaler class from the scikit-learn toolkit in Python is used to deal with outliers. By deleting the median and scaling the information in keeping with the interquartile vary, this class could also be used to scale the information.
from sklearn.preprocessing import RobustScaler
knowledge = pd.read_csv('knowledge.csv')
scaler = RobustScaler()
knowledge = scaler.fit_transform(knowledge)
One other widespread knowledge cleansing job is changing knowledge right into a format that can be utilized by a mannequin. As an example, earlier than categorical knowledge will be employed in a mannequin, it should be reworked into numerical knowledge. The get_dummies() methodology within the pandas bundle permits one to rework class knowledge into numerical knowledge. Within the instance beneath, the explicit function ‘Department’ is reworked into numerical knowledge:
import pandas as pd
knowledge = pd.read_csv('knowledge.csv')
knowledge = pd.get_dummies(knowledge, columns=['Department'])
Duplicate knowledge should even be eradicated in the course of the knowledge cleansing course of. To delete duplicate rows from a Python DataFrame, the drop_duplicates() methodology supplied by the pandas bundle can be utilized. As an example, the code beneath will remove any redundant rows from the information:
import pandas as pd
knowledge = pd.read_csv('knowledge.csv')
knowledge = knowledge.drop_duplicates()
Function choice and have engineering are important parts of information cleansing. The method of selecting solely the related options in a dataset is known as function choice, whereas the method of constructing new options from already current ones is called function engineering. The code beneath is an illustration of function engineering:
import pandas as pd
from sklearn.preprocessing import StandardScaler
# learn the information right into a pandas dataframe
df = pd.read_excel("knowledge.csv")
# create a function matrix and goal vector
X = df.drop(["Employee ID", "Date of Joining"], axis=1)
y = df["Salary"]
# scale the numerical options
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X[["Age", "Experience"]])
# concatenate the scaled options with the explicit options
gender_dummies = pd.get_dummies(X["Gender"], prefix="Gender")
X_processed = pd.concat(
[gender_dummies, pd.DataFrame(X_scaled, columns=["Age", "Experience"])],
axis=1,
)
print(X_processed)
Within the above code, we first create a function matrix (X) by dropping the ‘Worker ID‘ and ‘Date of Becoming a member of‘ columns, and create a goal vector (y) consisting of the ‘Wage‘ column. We then scale the numerical options ‘Age‘ and ‘Expertise‘ utilizing the StandardScaler() operate from scikit-learn.
Subsequent, we create dummy variables for the explicit ‘Gender‘ column and concatenate them with the scaled numerical options to create the ultimate processed function matrix (X_processed).
Word that the particular function extraction methods used will rely upon the information and the particular necessities of the evaluation. Additionally, it is essential to separate the information into coaching and testing units earlier than making use of any machine studying fashions to keep away from overfitting.
To conclude, knowledge cleansing is a vital stage within the machine studying course of because it ensures the information used for evaluation (descriptive or prescriptive) is of top quality. Vital strategies that could be used to organize and preprocess knowledge embody changing knowledge format, eradicating duplicate knowledge, coping with lacking knowledge, outlier detection, function engineering, and have choice. Pandas, NumPy, and scikit-learn are only a few of the various libraries and instruments for function engineering and knowledge cleansing.
Benjamin O. Tayo is a Physicist, Information Science Educator, and Author, in addition to the Proprietor of DataScienceHub. Beforehand, Benjamin was educating Engineering and Physics at U. of Central Oklahoma, Grand Canyon U., and Pittsburgh State U.
[ad_2]
Source link
