

[ad_1]
Deep options are pivotal in pc imaginative and prescient research, unlocking picture semantics and empowering researchers to deal with numerous duties, even in eventualities with minimal knowledge. Currently, strategies have been developed to extract options from various knowledge sorts like photos, textual content, and audio. These options function the bedrock for numerous purposes, from classification to weakly supervised studying, semantic segmentation, neural rendering, and the cutting-edge subject of picture era. With their transformative potential, deep options proceed to push the boundaries of what’s doable in pc imaginative and prescient.
Though deep options have many purposes in pc imaginative and prescient, they usually want extra spatial decision to immediately carry out dense prediction duties like segmentation and depth prediction on account of fashions that aggressively pool data by fashions over giant areas. As an example, ResNet-50 condenses a 224 × 224-pixel enter to 7 × 7 deep options. Even the cutting-edge Imaginative and prescient Transformers (ViTs) face related challenges, considerably decreasing decision. This discount presents a hurdle in leveraging these options for duties demanding exact spatial data, corresponding to segmentation or depth estimation.
A gaggle of researchers from MIT, Google, Microsoft, and Adobe launched FeatUp, a job and model-agnostic framework that restores misplaced spatial data in deep options. They gave two variants of FeatUp: the primary one guides options with a high-resolution sign in a single ahead cross. In distinction, the second suits an implicit mannequin to a single picture to reconstruct options at any decision. These options retain their unique semantics and may seamlessly exchange current options in numerous purposes to yield decision and efficiency good points even with out re-training. FeatUp considerably outperforms different characteristic upsampling and picture super-resolution approaches in school activation map era, depth prediction, and many others.
For FeatUp variants, a multi-view consistency loss with deep analogies to NeRFs has been used. The next steps are thought of on this analysis paper whereas creating FeatUp:
- Generated low-resolution characteristic views to refine right into a single high-resolution output. For this, the enter picture was perturbed with small pads and horizontal flips. The mannequin was utilized to every reworked picture to extract a set of low-resolution characteristic maps from these views. It supplies sub-feature data to coach the upsampler.
- We constructed a constant high-resolution characteristic map and postulated that it will probably reproduce low-resolution jittered options when downsampled. FeatUp’s downsampling is a direct analog to ray-marching, which transforms high-resolution into low-resolution options.
- Upsamplers are skilled on the ImageNet coaching set for two,000 steps, and metrics are computed throughout 2,000 random photos from the validation set. A frozen pre-trained ViT-S/16 additionally served because the characteristic, extracting Class Activation Maps (CAMs) by making use of a linear classifier after max-pooling.
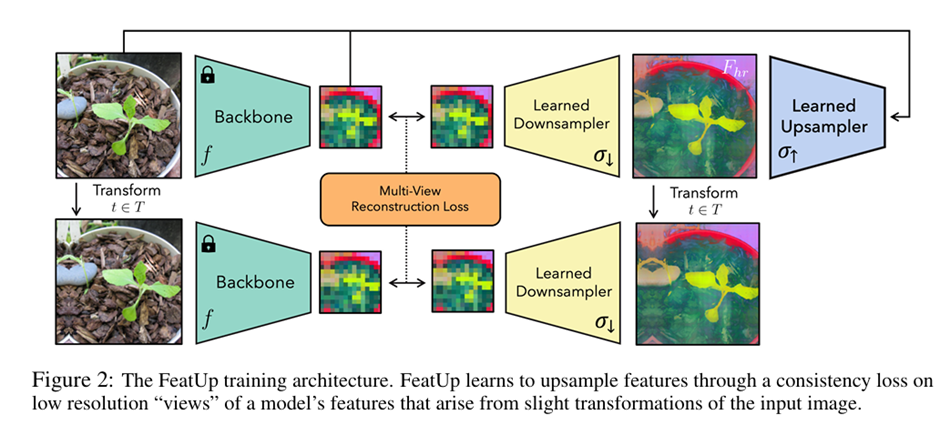
On evaluating downsampled options with the true mannequin outputs utilizing a Gaussian probability loss, it’s noticed {that a} good high-resolution characteristic map ought to reconstruct the noticed options throughout all of the totally different views. To scale back the reminiscence footprint and additional pace up the coaching of FeatUp’s implicit community, the spatially various options are compressed to their high ok=128 principal elements. This compression operation maintains practically all related data, as the highest 128 elements clarify roughly 96% of the variance in a single picture’s options. This optimization accelerates coaching time by a exceptional 60× for fashions like ResNet-50 and facilitates bigger batches with out compromising characteristic high quality.
In conclusion, FeatUp, a job and model-agnostic framework that restores misplaced spatial data in deep options, is a novel method to upsample deep options utilizing multi-view consistency. It might study high-quality options at arbitrary resolutions. It solves a important downside in pc imaginative and prescient: deep fashions study high-quality options however at prohibitively low spatial resolutions. Each variants of FeatUp outperform a variety of baselines throughout linear probe switch studying, mannequin interpretability, and end-to-end semantic segmentation.
Take a look at the Paper and MIT Blog. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our newsletter..
Don’t Overlook to affix our 39k+ ML SubReddit

Sajjad Ansari is a remaining 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a deal with understanding the affect of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.
[ad_2]
Source link
