


[ad_1]

Picture by Editor
These days, NLP is likely one of the most rising traits of AI as its functions are widespread throughout a number of industries corresponding to Healthcare, Retail, and Banking to call just a few. As there may be an rising must develop quick and scalable options, spaCy is likely one of the go-to NLP libraries for builders. NLP merchandise are developed to make sense of the prevailing textual content knowledge. It primarily revolves round fixing questions corresponding to ‘What’s the context of information?’, ‘Does it signify any bias?’, ‘Is there some similarity amongst phrases?’ and many others. to construct helpful options?
Subsequently, spaCy is a library that helps to cope with such questions and it gives a bunch of modules which can be straightforward to plug and play. It’s an open-source and production-friendly library that makes growth and deployment clean and environment friendly. Furthermore, spaCy was not constructed with a research-oriented method therefore it gives a restricted set of functionalities for the customers to select from as a substitute of a number of choices to develop shortly.
On this weblog, we’ll discover how one can get began with spaCy proper from the set up to discover the assorted functionalities it gives.
To put in spaCy enter the next command:
spaCy typically requires skilled pipelines to be loaded with the intention to entry most of its functionalities. These pipelines contained pretrained fashions which carry out prediction for a few of the generally used duties. The pipelines can be found in a number of languages and in a number of sizes. Right here, we’ll set up the small and medium measurement pipelines for English.
python -m spacy obtain en_core_web_sm python -m spacy obtain en_core_web_md
Voila! You at the moment are all set to begin utilizing spaCy.
Right here, we’ll load the smaller pipeline model of English.
import spacy
nlp = spacy.load("en_core_web_sm")
The pipeline is now loaded into the nlp object.
Subsequent, we can be exploring the assorted functionalities of spaCy utilizing an instance.
Tokenization is a strategy of splitting the textual content into smaller models known as tokens. For instance, in a sentence tokens can be phrases whereas in a paragraph tokens could possibly be sentences. This step helps to know the content material by making it straightforward to learn and course of.
We first outline a string.
textual content = "KDNuggets is an excellent web site to be taught machine studying with python"
Now we name the ‘nlp’ object on ‘textual content’ and retailer it in a ‘doc’ object. The thing ‘doc’ can be containing all of the details about the textual content – the phrases, the whitespaces and many others.
‘doc’ can be utilized as an iterator to parse by the textual content. It accommodates a ‘.textual content’ technique which may give the textual content of each token like:
for token in doc: print(token.textual content)
output:
KDNuggets is a great web site to be taught machine studying with python
Along with splitting the phrases by white areas, the tokenization algorithm additionally performs double-checks on the cut up textual content.
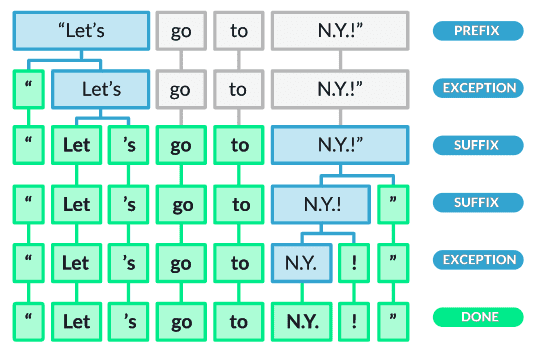
Supply: spaCy documentation
As proven within the above picture, after splitting the phrases by white areas, the algorithm checks for exceptions. The phrase ‘Let’s’ isn’t in its root kind therefore it’s once more cut up into ‘Let’ and ‘’s’. The punctuation marks are additionally cut up. Furthermore, the rule makes positive to not cut up phrases like ‘N.Y.’ and considers them like a single token.
One of many necessary preprocessing steps in NLP is to take away cease phrases from textual content. Cease phrases are principally connector phrases corresponding to ‘to’, ‘with’, ‘is’, and many others. which offer minimal context. spaCy permits straightforward identification of cease phrases with an attribute of the ‘doc’ object known as ‘is_stop’.
We iterate over all of the tokens and apply the ‘is_stop’ technique.
for token in doc: if token.is_stop == True: print(token)
output:
Lemmatization is one other necessary preprocessing step for NLP pipelines. It helps to take away totally different variations of a single phrase to cut back redundancy of same-meaning phrases because it converts the phrases to their root lemmas. For instance, it would convert ‘is’ -> ‘be’, ‘consuming’ -> ‘eat’, and ‘N.Y.’ -> ‘n.y.’. With spaCy, the phrases may be simply transformed to their lemmas utilizing a ‘.lemma_’ attribute of the ‘doc’ object.
We iterate over all of the tokens and apply the ‘.lemma_’ technique.
for token in doc: print(token.lemma_)
output:
kdnugget be a great web site to be taught machine studying with python
Automated POS tagging allows us to get an concept of the sentence construction by understanding what class of phrases dominate the content material and vice versa. This data types an important half in understanding the context. spaCy permits parsing the content material and tagging the person tokens with their respective components of speech by the ‘.pos_’ attribute of the ‘doc’ object.
We iterate over all of the tokens and apply the ‘.pos_’ technique.
for token in doc: print(token.textual content,':',token.pos_)
output:
KDNuggets : NOUN is : AUX a : DET great : ADJ web site : NOUN to : PART be taught : VERB machine : NOUN studying : NOUN with : ADP python : NOUN
Each sentence has an inherent construction by which the phrases have an interdependent relationship with one another. Dependency parsing may be considered a directed graph whereby the nodes are phrases and the sides are relationships between the phrases. It extracts the knowledge on what one phrase means to a different grammatically; whether or not it’s a topic, an auxiliary verb, or a root, and so forth. spaCy has a way ‘.dep_’ of the ‘doc’ object which describes the syntactic dependencies of the tokens.
We iterate over all of the tokens and apply the ‘.dep_’ technique.
for token in doc: print(token.textual content, '-->', token.dep_)
output:
KDNuggets --> nsubj is --> ROOT a --> det great --> amod web site --> attr to --> aux be taught --> relcl machine --> compound studying --> dobj with --> prep python --> pobj
All of the real-world objects have a reputation assigned to them for recognition and likewise, they’re grouped right into a class. For example, the phrases ‘India’, ‘U.Ok.’, and ‘U.S.’ fall below the class of nations whereas ‘Microsoft’, ‘Google’, and ‘Fb’ belong to the class of organizations. spaCy already has skilled fashions within the pipeline that may decide and predict the classes of such named entities.
We’ll entry the named entities by utilizing the ‘.ents’ technique over the ‘doc’ object. We’ll show the textual content, begin character, finish character, and label of the entity.
for ent in doc.ents: print(ent.textual content, ent.start_char, ent.end_char, ent.label_)
output:
Usually in NLP, we want to analyze the similarity of phrases, sentences, or paperwork which can be utilized for functions corresponding to recommender techniques or plagiarism detection instruments to call just a few. The similarity rating is calculated by discovering the space between the phrase embeddings, i.e., the vector illustration of phrases. spaCy gives this performance with medium and enormous pipelines. The bigger pipeline is extra correct because it accommodates fashions skilled on extra and numerous knowledge. Nonetheless, we’ll use the medium pipeline right here only for the sake of understanding.
We first outline the sentences to be in contrast for similarity.
nlp = spacy.load("en_core_web_md")
doc1 = nlp("Summers in India are extraordinarily scorching.")
doc2 = nlp("Throughout summers numerous areas in India expertise extreme temperatures.")
doc3 = nlp("Folks drink lemon juice and put on shorts throughout summers.")
print("Similarity rating of doc1 and doc2:", doc1.similarity(doc2))
print("Similarity rating of doc1 and doc3:", doc1.similarity(doc3))
output:
Similarity rating of doc1 and doc2: 0.7808246189842116 Similarity rating of doc1 and doc3: 0.6487306770376172
Rule-based matching may be thought of much like regex whereby we are able to point out the particular sample to be discovered within the textual content. spaCy’s matcher module not solely does the talked about job but additionally gives entry to the doc data corresponding to tokens, POS tags, lemmas, dependency buildings, and many others. which makes extraction of phrases attainable on a number of further situations.
Right here, we’ll first create a matcher object to include all of the vocabulary. Subsequent, we’ll outline the sample of textual content to be regarded for and add that as a rule to the matcher module. Lastly, we’ll name the matcher module over the enter sentence.
from spacy.matcher import Matcher
matcher = Matcher(nlp.vocab)
doc = nlp("chilly drinks assist to cope with warmth in summers")
sample = [{'TEXT': 'cold'}, {'TEXT': 'drinks'}]
matcher.add('rule_1', [pattern], on_match=None)
matches = matcher(doc)
for _, begin, finish in matches:
matched_segment = doc[start:end]
print(matched_segment.textual content)
output:
chilly drinks Let's additionally take a look at one other instance whereby we try to seek out the phrase 'guide' however solely when it's a 'noun'.
from spacy.matcher import Matcher
matcher = Matcher(nlp.vocab)
doc1 = nlp("I'm studying the guide known as Huntington.")
doc2 = nlp("I want to guide a flight ticket to Italy.")
pattern2 = [{'TEXT': 'book', 'POS': 'NOUN'}]
matcher.add('rule_2', [pattern2], on_match=None)
matches = matcher(doc1)
print(doc1[matches[0][1]:matches[0][2]])
matches = matcher(doc2)
print(matches)
output:
On this weblog, we checked out how one can set up and get began with spaCy. We additionally explored the assorted primary functionalities it gives corresponding to tokenization, lemmatization, dependency parsing, parts-of-speech tagging, named entity recognition and so forth. spaCy is a very handy library in terms of growing NLP pipelines for manufacturing functions. Its detailed documentation, simplicity of use, and number of features make it one of many broadly used libraries for NLP.
Yesha Shastri is a passionate AI developer and author pursuing Grasp’s in Machine Studying from Université de Montréal. Yesha is intrigued to discover accountable AI methods to resolve challenges that profit society and share her learnings with the neighborhood.
[ad_2]
Source link
