

[ad_1]
Massive language fashions, equivalent to PaLM, Chinchilla, and ChatGPT, have opened up new prospects in performing pure language processing (NLP) duties from studying instructive cues. The prior artwork has demonstrated that instruction tuning, which entails finetuning language fashions on varied NLP duties organized with directions, additional improves language fashions’ capability to hold out an unknown activity given an instruction. By evaluating their finetuning procedures and methods, They consider the approaches and outcomes of open-sourced instruction generalization initiatives on this paper.
This work focuses on the main points of the instruction tuning strategies, ablating particular person elements and straight evaluating them. They determine and consider the vital methodological enhancements within the “Flan 2022 Assortment,” which is the time period they use for knowledge assortment and the strategies that apply to the information and instruction tuning course of that focuses on the emergent and state-of-the-art outcomes of mixing Flan 2022 with PaLM 540B. The Flan 2022 Assortment comprises probably the most complete assortment of jobs and methods for instruction tweaking that’s presently publicly accessible. It has been augmented with 1000’s of premium templates and higher formatting patterns.
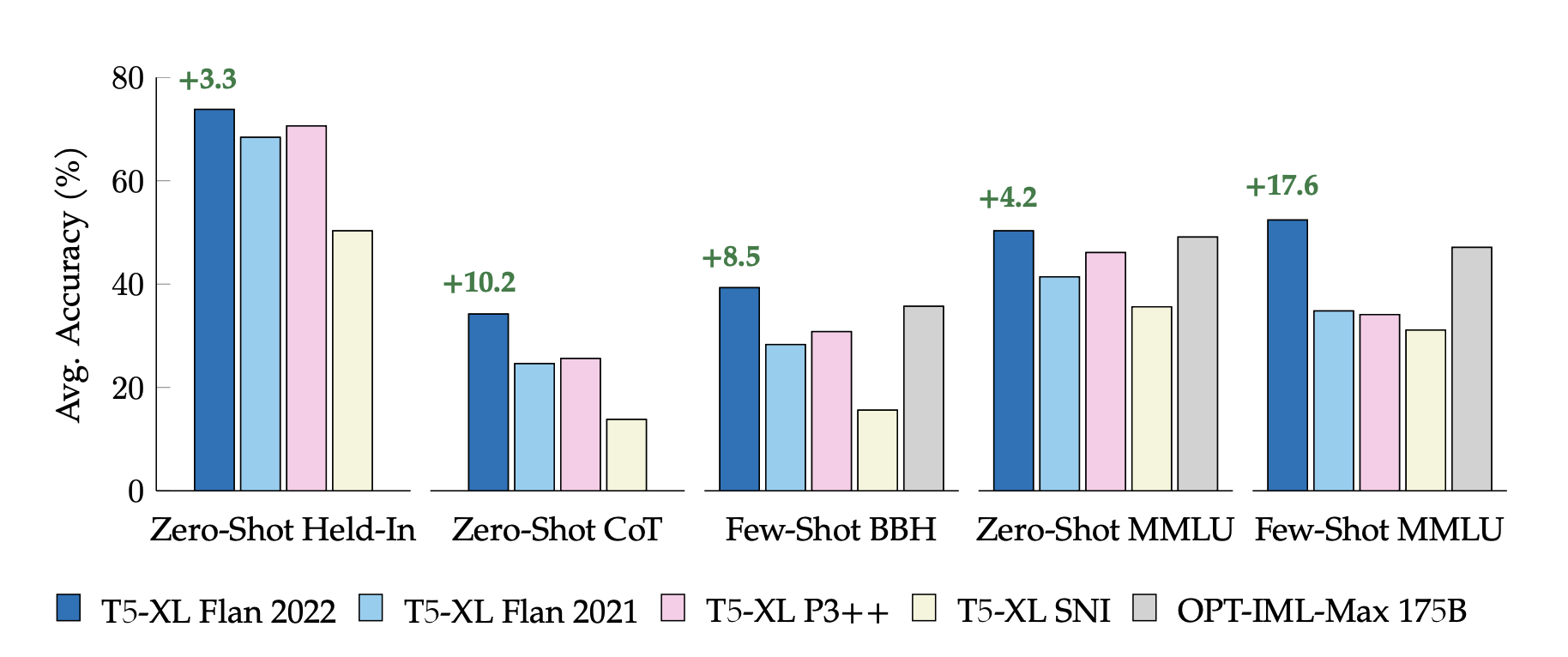
They show that, on all evaluated analysis benchmarks, a mannequin educated on this assortment outperforms different public collections, together with the unique Flan 2021 their, T0++ their, Tremendous-Pure Directions their, and the modern work on OPT-IML their. This contains, for identically sized fashions, enhancements of 4.2%+ and eight.5% on the MMLU and BIG-Bench Arduous evaluation benchmarks. In response to an evaluation of the Flan 2022 strategy, the strong outcomes are as a result of greater and extra diversified assortment of duties and a number of other easy methods for finetuning and knowledge augmentation. Specifically, coaching on varied situations templated with zero-shot, few-shot, and chain-of-thought prompts improves efficiency in all of those contexts.
For example, a ten% enhance in few-shot prompts improves the outcomes of zero-shot prompting by 2% or extra. Moreover, it has been demonstrated that balancing activity sources and enhancing activity selection by inverting input-output pairings, as accomplished in, are each important to efficiency. In single-task finetuning, the resultant Flan-T5 mannequin converges quicker and performs higher than T5 fashions, indicating that instruction-tuned fashions present a extra computationally efficient place to begin for subsequent functions. They anticipate that making these outcomes and instruments overtly accessible will streamline the sources accessible for instruction tailoring and hasten the event of extra general-purpose language fashions.
The primary contributions of this examine are enumerated as follows: • Methodological: Show that coaching with a mixture of zero- and few-shot cues produce considerably superior leads to each environments. • Measuring and demonstrating the important thing strategies for environment friendly instruction tuning, together with scaling Part 3.3, enhancing activity variety utilizing enter inversion, including chain-of-thought coaching knowledge, and balancing varied knowledge sources. • Outcomes: These technical selections enhance held-out activity efficiency by 3–17% in comparison with accessible open-source instruction tuning collections • Findings: Flan-T5 XL supplies a extra strong and efficient computational place to begin for single-task finetuning. • Make the brand new Flan 2022 activity assortment, templates, and analysis methodologies accessible for public use. Supply code is accessible on GitHub.
Try the Paper and Github. Here’s a cool article to be taught extra in regards to the comparability. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t neglect to hitch our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
Aneesh Tickoo is a consulting intern at MarktechPost. He’s presently pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Expertise(IIT), Bhilai. He spends most of his time engaged on initiatives aimed toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is captivated with constructing options round it. He loves to attach with folks and collaborate on fascinating initiatives.
[ad_2]
Source link
