


[ad_1]

Google researchers have created an AI that may generate music primarily based on a textual content description offered by a person.
Analysis on the Noise2music program, which was published last week and continues to be in its early days, provides a brand new dimension to what conversational AIs can do.
Customers can already request AIs like DALL·E 2 to generate photos primarily based on easy textual content descriptions. ChatGPT can generate full solutions, write essays and even generate code primarily based on a person’s request.
The Noise2music AI can now generate custom-made sound at a person’s request.
It has been a busy month for Google, which is speeding to commercialize its AI analysis after being upstaged final week by Microsoft, which is placing AI expertise from OpenAI into its merchandise. OpenAI created ChatGPT conversational AI and the image-generating DALL·E 2.
The Noise2music analysis makes use of the identical giant language mannequin known as LaMDA, which Google used for its Bard conversational AI, which the corporate plans to include in its search engine.
Google announced Bard final week after Microsoft’s shock announcement that it was incorporating a ChatGPT-style chatbot in its Bing search engine. Google had largely stored its main AI initiatives away from public view, although it has revealed analysis papers.
Another main Google AI initiatives embody Imagen, which may generate photos and video primarily based on textual content descriptions, and PaLM, which is a big language mannequin with 540 billion parameters.
Massive language fashions run on the Transformer structure, introduced by Google in 2017, which helps tie collectively relations between elements of sentences, photos, and different information factors. By comparability, convolutional neural networks have a look at solely quick neighboring relationships.
The Google researchers fed Noise2music tons of of hundreds of hours of music, and hooked up a number of labels to the music clips that finest described the audio. That concerned utilizing a large-language to generate descriptions that could possibly be hooked up as captions to audio clips, after which utilizing one other pre-trained mannequin to label the audio clip.
The LaMDA large-language mannequin generated 4 million long-form sentences to explain tons of of hundreds of well-liked songs. One description included “a light-weight, atmospheric drum groove supplies a tropical really feel.”
“We use LaMDA as our LM of selection as a result of it’s skilled for dialogue functions, and anticipate the generated textual content to be nearer to person prompts for producing music,” the researchers wrote.
The researchers used the diffusion mannequin, which is utilized in DALL·E 2 to generate higher-quality photos. On this case, the mannequin goes by an upscaling course of that generates higher-quality 24kHz audio for 30 seconds. The researchers generated AI processing on TPU V4 chips within the Google Cloud infrastructure.
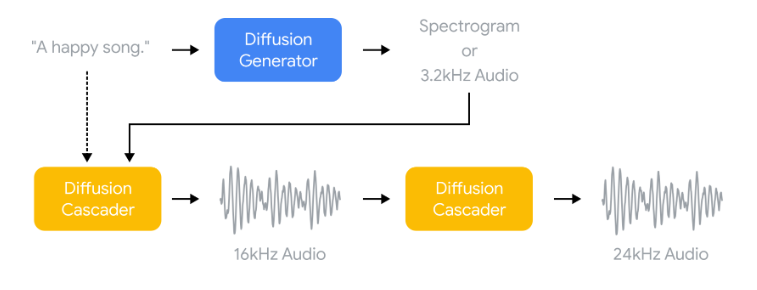
Noise2Music Finish-to-Finish Diffusion depiction (Supply: Google)
The researchers posted sample audio generated by the Noise2music AI on Google Analysis’s Github web site. EnterpriseAI ran the audio clips by track recognition utility Shazam, and the app could not acknowledge any clip as an present track.
The researchers famous that there’s a lot work to be accomplished to enhance the music technology primarily based on textual content prompts, and one course for this AI could possibly be “to fine-tune the fashions skilled on this work for various audio duties together with music completion and modification,” the researchers famous.
The enhancements could have to be accomplished with the assistance of musicians and others to develop a co-creation software, the researchers famous.
“We imagine our work has the potential to develop into a useful gizmo for artists and content material creators that may additional enrich their artistic pursuits,” the researchers famous.
Associated
[ad_2]
Source link
