

[ad_1]
Current developments in (self) supervised studying fashions have been pushed by empirical scaling legal guidelines, the place a mannequin’s efficiency scales with its measurement. Nonetheless, such scaling legal guidelines have been difficult to determine in reinforcement studying (RL). In contrast to supervised studying, growing the parameter rely of an RL mannequin typically results in decreased efficiency. This paper investigates the combination of Combination-of-Skilled (MoE) modules, notably Gentle MoEs, into value-based networks.
Deep Reinforcement Studying (RL) combines reinforcement studying with deep neural networks, creating a robust software in AI. It’s confirmed to be extremely efficient in fixing powerful issues, even surpassing human efficiency in some circumstances. This strategy has gained lots of consideration throughout totally different fields, like gaming and robotics. Many research have proven its success in tackling challenges that had been beforehand considered unimaginable.
Although Deep RL has achieved spectacular outcomes, how precisely deep neural networks work in RL remains to be unclear. These networks are essential for serving to brokers in complicated environments and bettering their actions. However understanding how they’re designed and the way they study presents fascinating puzzles for researchers. Current research have even discovered stunning issues occurring that go towards what we normally see in supervised studying.
On this context, understanding the position of deep neural networks in Deep RL turns into crucial. This introductory part units the stage for exploring the mysteries surrounding the design, studying dynamics, and peculiar behaviors of deep networks inside the framework of Reinforcement Studying. By means of a complete examination, this examine goals to make clear the enigmatic interaction between deep studying and reinforcement studying, unraveling the complexities underlying the success of Deep RL brokers.
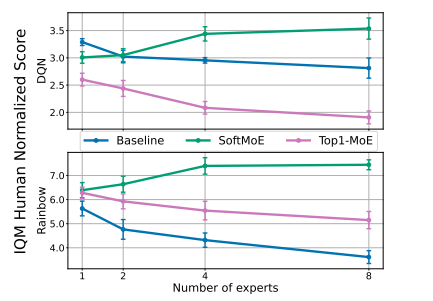
The above determine demonstrates the usage of Combination of Specialists permits the efficiency of DQN (prime) and Rainbow (backside) to scale with an elevated variety of parameters. Combination of Specialists (MoEs) in neural networks selectively routes inputs to specialised parts. Whereas generally utilized in transformer architectures for token inputs, the idea of tokens shouldn’t be universally relevant in deep reinforcement studying networks, not like in most supervised studying duties.
Important distinctions are noticed between the baseline structure and people incorporating Combination of Specialists (MoE) modules. Compared to the baseline community, architectures with MoE modules display greater numerical ranks in empirical Neural Tangent Kernel (NTK) matrices and exhibit minimal dormant neurons and have norms. These observations trace on the stabilizing affect of MoE modules on optimization dynamics, though direct causal hyperlinks between enhancements in these metrics and agent efficiency will not be conclusively established.

Mixtures of Specialists introduce a structured sparsity into neural networks, elevating the query of whether or not the noticed advantages stem solely from this sparsity reasonably than the MoE modules themselves. Our findings point out that it’s most likely a mix of each elements. Determine 1 illustrates that in Rainbow, incorporating an MoE module with a single professional results in statistically important efficiency enhancements, whereas Determine 2 reveals that decreasing professional dimensionality could be performed with out compromising efficiency.
The outcomes point out the potential for Combination of Specialists (MoEs) to supply broader benefits in coaching deep RL brokers. Furthermore, these findings affirm the numerous influence that architectural design selections can exert on the general efficiency of RL brokers. It’s hoped that these outcomes will encourage additional exploration by researchers into this comparatively uncharted analysis course.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and Google News. Be a part of our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our newsletter..
Don’t Neglect to affix our Telegram Channel
You might also like our FREE AI Courses….
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming information scientist and has been working on the earth of ml/ai analysis for the previous two years. She is most fascinated by this ever altering world and its fixed demand of people to maintain up with it. In her pastime she enjoys touring, studying and writing poems.
[ad_2]
Source link
