


[ad_1]
MLPerf stays the definitive measurement for AI efficiency as an unbiased, third-party benchmark. NVIDIA’s AI platform has persistently proven management throughout each coaching and inference because the inception of MLPerf, together with the MLPerf Inference 3.0 benchmarks launched in the present day.
“Three years in the past after we launched A100, the AI world was dominated by pc imaginative and prescient. Generative AI has arrived,” mentioned NVIDIA founder and CEO Jensen Huang.
“That is precisely why we constructed Hopper, particularly optimized for GPT with the Transformer Engine. Right now’s MLPerf 3.0 highlights Hopper delivering 4x extra efficiency than A100.
“The subsequent stage of Generative AI requires new AI infrastructure to coach massive language fashions with nice power effectivity. Clients are ramping Hopper at scale, constructing AI infrastructure with tens of hundreds of Hopper GPUs linked by NVIDIA NVLink and InfiniBand.
“The trade is working arduous on new advances in secure and reliable Generative AI. Hopper is enabling this important work,” he mentioned.
The most recent MLPerf results present NVIDIA taking AI inference to new ranges of efficiency and effectivity from the cloud to the sting.
Particularly, NVIDIA H100 Tensor Core GPUs operating in DGX H100 systems delivered the best efficiency in each take a look at of AI inference, the job of operating neural networks in manufacturing. Due to software optimizations, the GPUs delivered as much as 54% efficiency good points from their debut in September.
In healthcare, H100 GPUs delivered a 31% efficiency improve since September on 3D-UNet, the MLPerf benchmark for medical imaging.
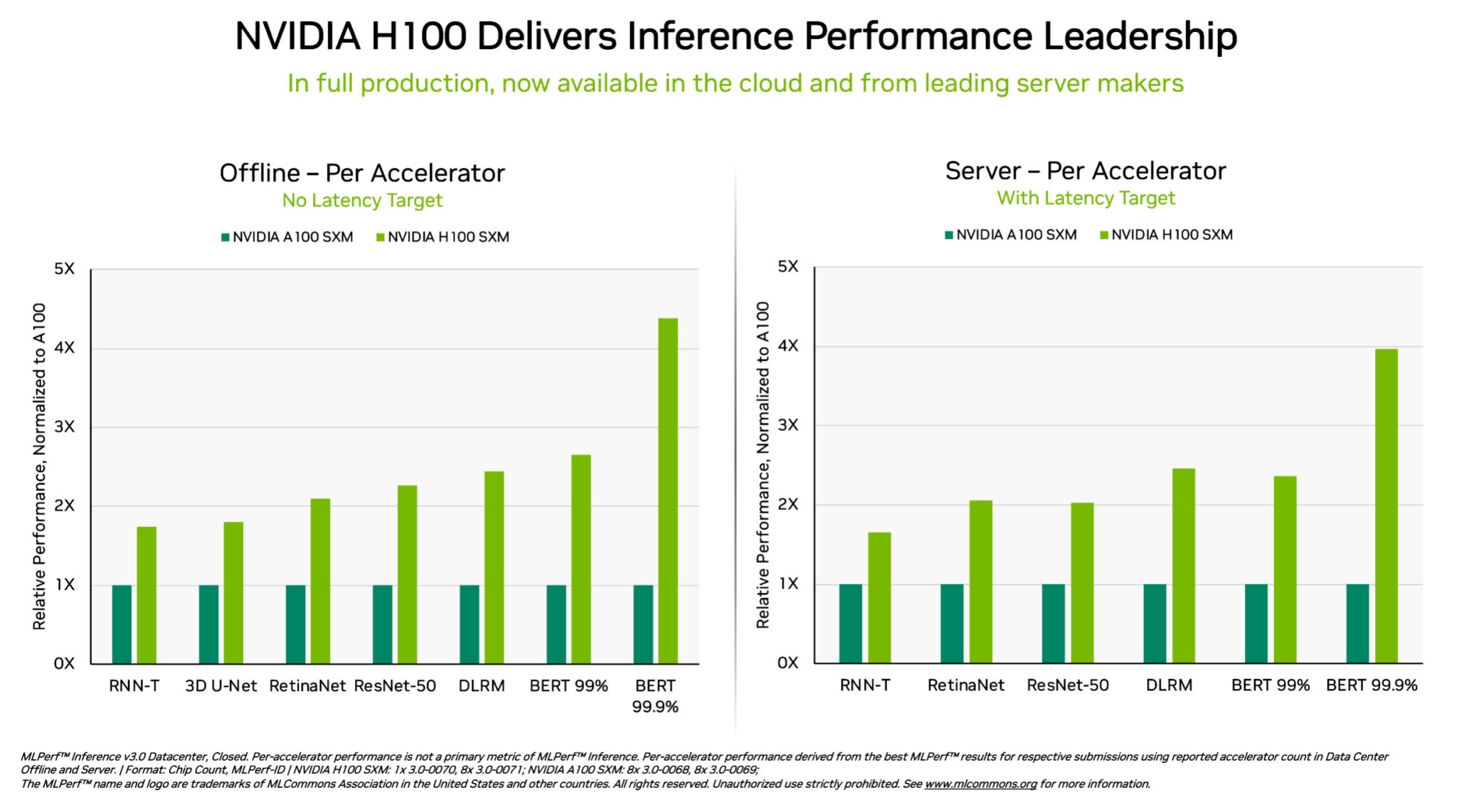
Powered by its Transformer Engine, the H100 GPU, based mostly on the Hopper structure, excelled on BERT, a transformer-based large language model that paved the best way for in the present day’s broad use of generative AI.
Generative AI lets customers shortly create textual content, photographs, 3D fashions and extra. It’s a functionality corporations from startups to cloud service suppliers are quickly adopting to allow new enterprise fashions and speed up present ones.
Tons of of thousands and thousands of individuals are actually utilizing generative AI instruments like ChatGPT — additionally a transformer mannequin — anticipating prompt responses.
At this iPhone second of AI, efficiency on inference is significant. Deep studying is now being deployed practically all over the place, driving an insatiable want for inference efficiency from manufacturing unit flooring to on-line recommendation systems.
L4 GPUs Pace Out of the Gate
NVIDIA L4 Tensor Core GPUs made their debut within the MLPerf exams at over 3x the velocity of prior-generation T4 GPUs. Packaged in a low-profile type issue, these accelerators are designed to ship excessive throughput and low latency in virtually any server.
L4 GPUs ran all MLPerf workloads. Due to their assist for the important thing FP8 format, their outcomes have been significantly beautiful on the performance-hungry BERT mannequin.
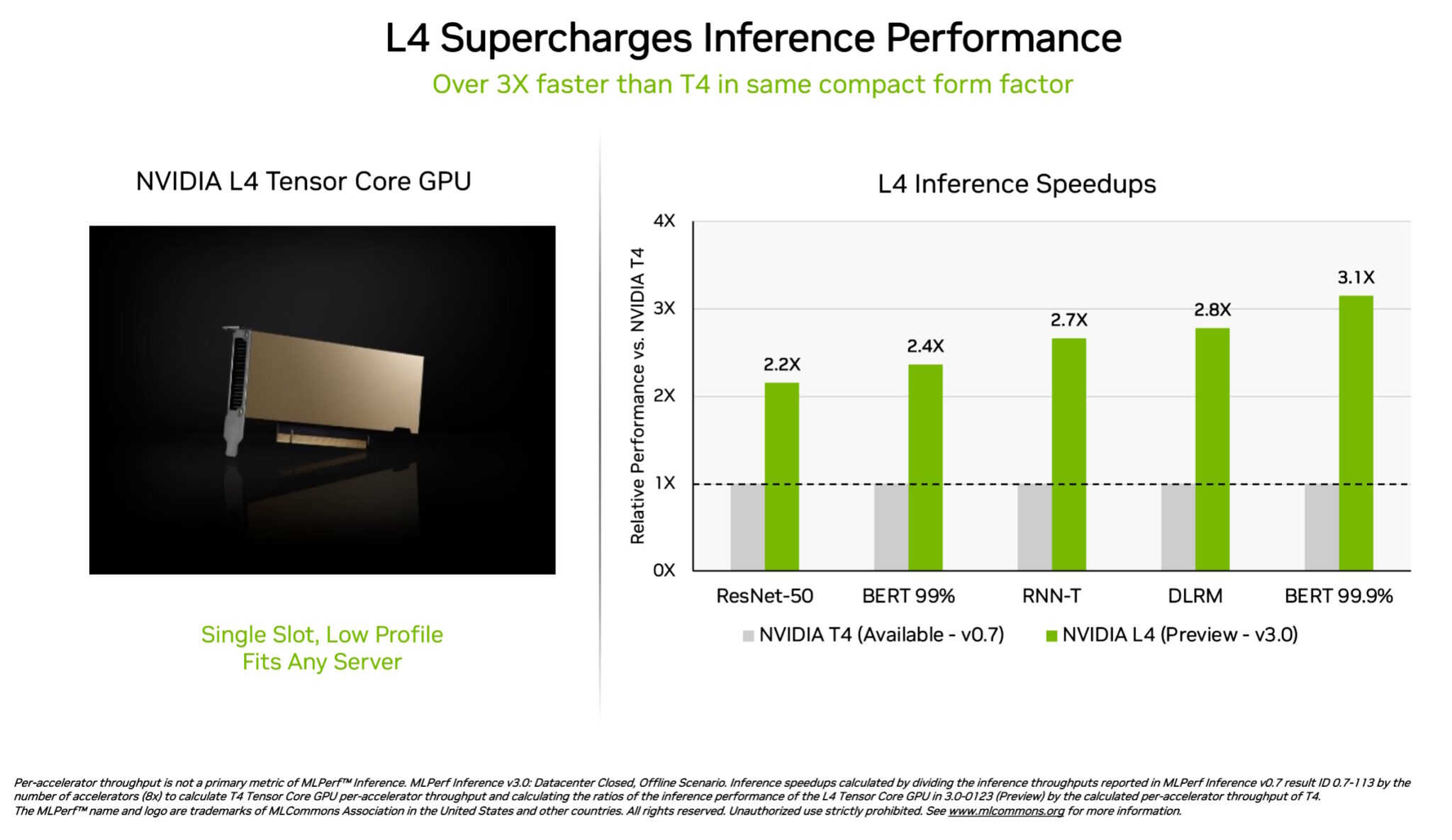
Along with stellar AI efficiency, L4 GPUs ship as much as 10x sooner picture decode, as much as 3.2x sooner video processing and over 4x sooner graphics and real-time rendering efficiency.
Introduced two weeks in the past at GTC, these accelerators are already out there from main techniques makers and cloud service providers. L4 GPUs are the most recent addition to NVIDIA’s portfolio of AI inference platforms launched at GTC.
Software program, Networks Shine in System Take a look at
NVIDIA’s full-stack AI platform confirmed its management in a brand new MLPerf take a look at.
The so-called network-division benchmark streams knowledge to a distant inference server. It displays the favored situation of enterprise customers operating AI jobs within the cloud with knowledge saved behind company firewalls.
On BERT, distant NVIDIA DGX A100 techniques delivered as much as 96% of their most native efficiency, slowed partially as a result of they wanted to attend for CPUs to finish some duties. On the ResNet-50 take a look at for pc imaginative and prescient, dealt with solely by GPUs, they hit the complete 100%.
Each outcomes are thanks, largely, to NVIDIA Quantum Infiniband networking, NVIDIA ConnectX SmartNICs and software program corresponding to NVIDIA GPUDirect.
Orin Reveals 3.2x Positive aspects on the Edge
Individually, the NVIDIA Jetson AGX Orin system-on-module delivered good points of as much as 63% in power effectivity and 81% in efficiency in contrast with its outcomes a yr in the past. Jetson AGX Orin provides inference when AI is required in confined areas at low energy ranges, together with on techniques powered by batteries.
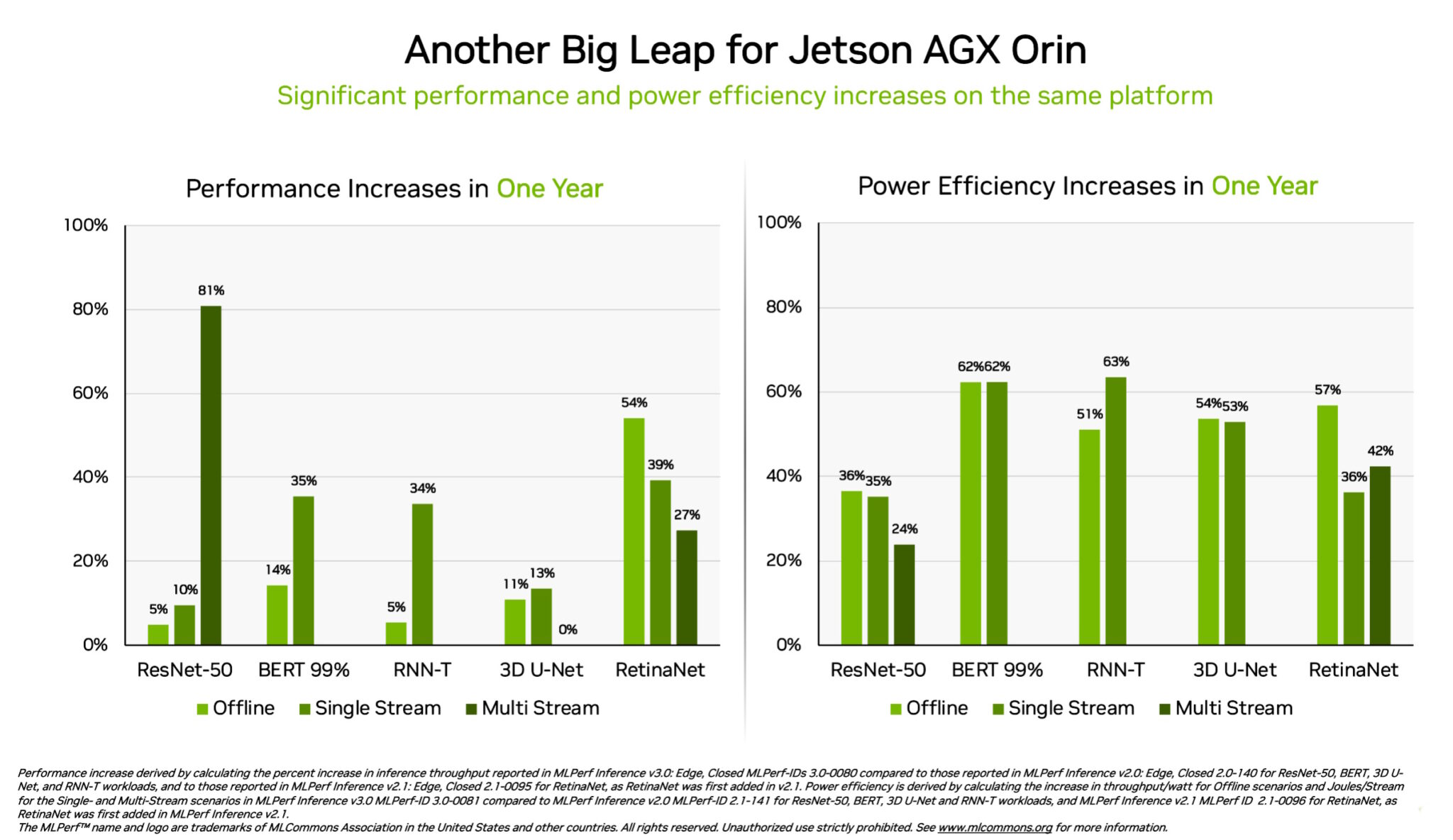
For purposes needing even smaller modules drawing much less energy, the Jetson Orin NX 16G shined in its debut within the benchmarks. It delivered as much as 3.2x the efficiency of the prior-generation Jetson Xavier NX processor.
A Broad NVIDIA AI Ecosystem
The MLPerf outcomes present NVIDIA AI is backed by the trade’s broadest ecosystem in machine studying.
Ten corporations submitted outcomes on the NVIDIA platform on this spherical. They got here from the Microsoft Azure cloud service and system makers together with ASUS, Dell Technologies, GIGABYTE, H3C, Lenovo, Nettrix, Supermicro and xFusion.
Their work exhibits customers can get nice efficiency with NVIDIA AI each within the cloud and in servers operating in their very own knowledge facilities.
NVIDIA companions take part in MLPerf as a result of they realize it’s a beneficial software for purchasers evaluating AI platforms and distributors. Leads to the most recent spherical reveal that the efficiency they ship in the present day will develop with the NVIDIA platform.
Customers Want Versatile Efficiency
NVIDIA AI is the one platform to run all MLPerf inference workloads and situations in knowledge heart and edge computing. Its versatile efficiency and effectivity make customers the true winners.
Actual-world purposes usually make use of many neural networks of various varieties that usually must ship solutions in actual time.
For instance, an AI software may have to know a consumer’s spoken request, classify a picture, make a advice after which ship a response as a spoken message in a human-sounding voice. Every step requires a special sort of AI mannequin.
The MLPerf benchmarks cowl these and different in style AI workloads. That’s why the exams guarantee IT resolution makers will get efficiency that’s reliable and versatile to deploy.
Customers can depend on MLPerf outcomes to make knowledgeable shopping for choices, as a result of the exams are clear and goal. The benchmarks get pleasure from backing from a broad group that features Arm, Baidu, Fb AI, Google, Harvard, Intel, Microsoft, Stanford and the College of Toronto.
Software program You Can Use
The software program layer of the NVIDIA AI platform, NVIDIA AI Enterprise, ensures customers get optimized efficiency from their infrastructure investments in addition to the enterprise-grade assist, safety and reliability required to run AI within the company knowledge heart.
All of the software program used for these exams is obtainable from the MLPerf repository, so anybody can get these world-class outcomes.
Optimizations are constantly folded into containers out there on NGC, NVIDIA’s catalog for GPU-accelerated software program. The catalog hosts NVIDIA TensorRT, utilized by each submission on this spherical to optimize AI inference.
Learn this technical blog for a deeper dive into the optimizations fueling NVIDIA’s MLPerf efficiency and effectivity.
[ad_2]
Source link
