


[ad_1]

Picture by Writer
ChatGPT has change into a swiss-army knife that can be utilized for multitude of functions, and there’s considerable scope to combine ChatGPT into information science workflows.
In case you’ve ever educated a machine studying mannequin on a real-world dataset, you recognize that the steps of knowledge cleansing and preprocessing are necessary for constructing strong machine studying fashions. On this information, we’ll see how we will use ChatGPT to carry out these duties on an instance dataset.
We’ll use the bank marketing dataset from the UCI machine learning repository and immediate ChatGPT to do the next:
- Fetch and cargo the dataset
- Verify for lacking values
- Encode categorical variables
You’ll be able to observe alongside by signing in to your OpenAI account and beginning a brand new ChatGPT session. In case you desire, it’s also possible to code alongside in Google Colab.
There are a few different versions of the dataset. We’ll use bank-full.csv.
Immediate: Immediately we’ll carry out information cleansing and preprocessing on a real-world dataset. Write the code to do the next: 1. Fetch the financial institution advertising dataset from the UCI machine studying repository. Use libraries like requests or urllib. 2. Obtain the zip file, unzip the contents, and skim within the bank-full.csv file right into a pandas dataframe (name it information).
The code to fetch and skim within the dataset is as follows:
import pandas as pd
import urllib
import zipfile
# URL of the dataset
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/00222/financial institution.zip"
# Fetch and extract the dataset
urllib.request.urlretrieve(url, "financial institution.zip")
with zipfile.ZipFile("financial institution.zip", "r") as zip_ref:
zip_ref.extractall()
# Load the dataset right into a pandas DataFrame
information = pd.read_csv("bank-full.csv", delimiter=";",skipinitialspace=True)
Let’s perceive the dataset higher.
# Show the primary few rows of the dataset
print(information.head())
This outputs:
Truncated output of knowledge.head()
Immediate: Use pandas to get the dimension of the dataframe, descriptive statistics on the columns, and information sorts of numerous columns.
This step doesn’t actually require prompting ChatGPT because the pandas strategies are fairly easy.
# Get the size of the dataset (rows, columns)
print(information.form)
We’ve over 45000 data and 16 options (as 17 is inclusive of the output label as nicely).
# Get statistical abstract of numerical columns
print(information.describe())

Truncated output of knowledge.describe()
It’s additionally useful to get an summary of the info sorts of the assorted columns. We’ll take a better have a look at them after we encode categorical variables.
# Verify information sorts of every column
print(information.dtypes)
Output >>>
age int64
job object
marital object
schooling object
default object
steadiness int64
housing object
mortgage object
contact object
day int64
month object
period int64
marketing campaign int64
pdays int64
earlier int64
poutcome object
y object
dtype: object
To date we’ve gained an understanding of the financial institution advertising dataset. The output label denotes whether or not or not a buyer will subscribe to a time period deposit. The dataset accommodates a number of options such because the age, month, schooling, marital standing, end result of earlier campaigns, and extra.
Immediate: I wish to know the variety of lacking values in every column. Please give me the code to do it. Use pandas.
# Verify for lacking values in every column
missing_values = information.isnull().sum()
print(missing_values)
Right here’s the output:
Output >>>
age 0
job 0
marital 0
schooling 0
default 0
steadiness 0
housing 0
mortgage 0
contact 0
day 0
month 0
period 0
marketing campaign 0
pdays 0
earlier 0
poutcome 0
y 0
dtype: int64
This model of the financial institution advertising dataset—with over 45000 data—doesn’t have any lacking values. In follow, although, most real-world datasets have lacking values. It is best to deal with lacking values utilizing appropriate imputation methods.
As an optionally available train , you’ll be able to add a step right here prompting ChatGPT to drop a small fraction of values from a subset of columns so you’ll be able to follow find out how to deal with lacking values.
The following step is to encode categorical variables within the dataset. We’ll begin by getting the listing of all categorical columns.
Immediate: Give the code to get the listing of all categorical columns on this dataset.
# Depend the variety of categorical variables
categorical_columns = information.select_dtypes(embody=['object']).columns
print(categorical_columns)
num_categorical_variables = len(categorical_columns)
# Show the rely
print("Variety of categorical variables:", num_categorical_variables)
The explicit columns listing additionally contains the output label y. However let’s give attention to the opposite categorical variables first.
Output >>>
Index(['job', 'marital', 'education', 'default', 'housing', 'loan', 'contact',
'month', 'poutcome', 'y'],
dtype="object")
Variety of categorical variables: 10
A Nearer Have a look at the Values of Categorical Variables
Subsequent, let’s see the values that every categorical variable takes.
Immediate: I wish to perceive the assorted values that every categorical variable takes. Give the pandas code to do it.
# Get the completely different values and their counts for every categorical column
categorical_columns = ['job', 'marital', 'education', 'default', 'housing', 'loan', 'contact', 'month', 'poutcome']
for column in categorical_columns:
value_counts = information[column].value_counts()
print(f"Column: {column}")
print(value_counts,"n")
The output is difficult to parse:
Output >>>
Column: job
blue-collar 9732
administration 9458
technician 7597
admin. 5171
providers 4154
retired 2264
self-employed 1579
entrepreneur 1487
unemployed 1303
housemaid 1240
pupil 938
unknown 288
Identify: job, dtype: int64
...
...
...
Column: poutcome
unknown 36959
failure 4901
different 1840
success 1511
Identify: poutcome, dtype: int64
Visualizing the Values of Categorical Variables
Let’s immediate ChatGPT to create a visualization so it’s simpler to grasp what values the explicit variables take.
Immediate: I need a plot that exhibits the values that every categorical variable takes. Exclude the output label y. Embody all different categorical variables.
And right here we go!
import matplotlib.pyplot as plt
# Get the completely different values and their counts for every categorical column
categorical_columns = ['job', 'marital', 'education', 'default', 'housing', 'loan', 'contact', 'month', 'poutcome']
# Arrange the subplot grid
fig, axes = plt.subplots(3, 3, figsize=(10,8))
# Iterate over every categorical column and plot the worth counts
for i, column in enumerate(categorical_columns):
row = i // 3
col = i % 3
value_counts = information[column].value_counts()
ax = axes[row, col]
value_counts.plot(sort='bar', ax=ax)
ax.set_xlabel(column)
ax.set_ylabel('Depend')
ax.set_title(f'{column.title()} Worth Counts')
# Modify spacing between subplots
plt.tight_layout()
# Present the plot
plt.present()
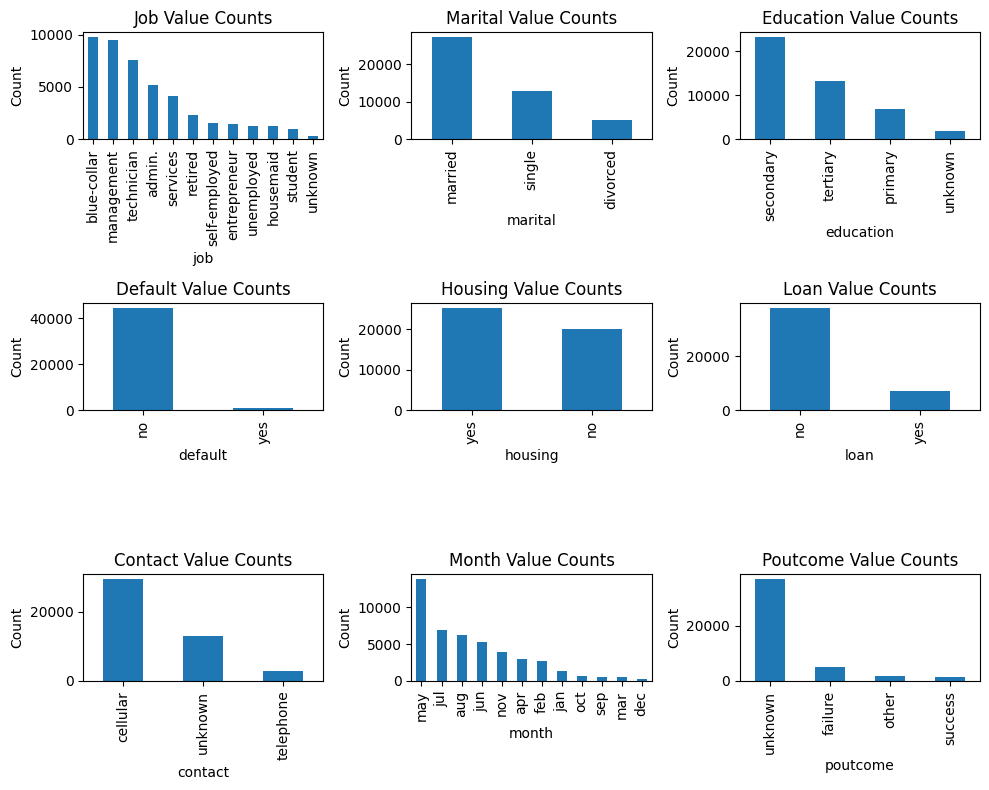
Values of Categorical Variables
One-Sizzling Encoding
For a subset of categorical columns, we will use one-hot encoding.
Immediate: Give the pandas code to carry out one-hot encoding for a listing of columns.
We use get_dummies from pandas to one-hot encode the next columns:
# Choose the explicit columns (excluding schooling and poutcome)
categorical_columns = ['job', 'marital', 'default', 'housing', 'loan', 'contact']
# Carry out one-hot encoding
encoded_data = pd.get_dummies(information, columns=categorical_columns)
Immediate: I wish to print out the primary few rows for the newly added columns. Write the code to do the identical.
# Choose the newly added columns
new_columns = encoded_data.columns.distinction(information.columns)
# Print the top of the newly added columns
print(encoded_data[new_columns].head())
Truncated output of encoded_data[‘new_colums’].head()
Defining a Customized Mapping
For columns for variables like ‘schooling’ and ‘poutcome’ (earlier end result), somewhat than one-hot encoding, it could be higher to make use of customized mapping to have a level of comparability between the values.
Additionally, after we use one-hot encoding to encode a categorical variable that takes ok distinct values ok new columns. For a categorical column like ‘month’ this will likely be extreme with out including a lot data.
So for each of those instances, we’ll outline a customized mapping after which remodel the values. We are able to immediate ChatGPT to get a generic code snippet which we will then modify to outline the mapping for the particular columns.
Immediate: I wish to do a customized mapping for encoding some categorical variables. First give me a generic code snippet that defines a customized mapping from distinctive values in a categorical column to a distinct set of output values. We must always then use this mapping to rework the values within the columns.
# Outline the customized mapping dictionary
custom_mapping = {
'category1': 'value1',
'category2': 'value2',
'category3': 'value3',
# Add extra classes and corresponding values as wanted
}
# Specify the explicit column
categorical_column = 'column_name' # Exchange 'column_name' with the precise column title
# Carry out the mapping utilizing the customized mapping dictionary
information[categorical_column] = information[categorical_column].map(custom_mapping)
For the ‘month’ column, allow us to remodel the month strings like so:
# Outline the mapping dictionary for months
month_mapping = {
'jan': 1,
'feb': 2,
'mar': 3,
'apr': 4,
'could': 5,
'jun': 6,
'jul': 7,
'aug': 8,
'sep': 9,
'oct': 10,
'nov': 11,
'dec': 12
}
# Map the values within the month column
encoded_data['month'] = encoded_data['month'].map(month_mapping)
Let’s map the ‘poutcome’ and ‘schooling’ columns to numerical values as proven:
# Outline the customized mapping for poutcome and schooling
poutcome_mapping = {
'unknown': 0,
'failure': 1,
'different': 2,
'success': 3
}
education_mapping = {
'unknown': 0,
'main': 1,
'secondary': 2,
'tertiary': 3
}
# Carry out ordinal encoding utilizing pandas map
encoded_data['poutcome'] = encoded_data['poutcome'].map(poutcome_mapping)
encoded_data['education'] = encoded_data['education'].map(education_mapping)
# Choose the newly added columns
new_columns = ['month','poutcome', 'education']
# Print the top of the newly added columns
print(encoded_data[new_columns].head(10))
Encoding the Output Label
Let’s additionally map the output name and why the output values sure and no to 190 respectively to 1 and nil respectively
encoded_data['y'] = encoded_data['y'].exchange({'no': 0, 'sure': 1})
print(encoded_data['y'])
Output >>>
0 0
1 0
2 0
3 0
4 0
..
45206 1
45207 1
45208 1
45209 0
45210 0
Identify: y, Size: 45211, dtype: int64
Recall that we used one-hot encoding for ‘housing’, ‘default’, and ‘mortgage’ columns. As a result of these columns additionally take ‘sure’ and ‘no’ values, it’s also possible to map ‘sure’ and ‘no’ to 1 and 0, respectively.
Visualizing the Distribution of Class Labels
It’s additionally useful to examine the distribution of sophistication labels in order that we will account for sophistication imbalance when constructing fashions if wanted.
Immediate: I wish to perceive the distribution of sophistication labels. Please give me the code to generate an acceptable plot for a similar.
Right here’s the code to generate a countplot in Seaborn:
import seaborn as sns
import matplotlib.pyplot as plt
# Plot the distribution of output labels
sns.countplot(information=information, x='y')
plt.xlabel('Output Label')
plt.ylabel('Depend')
plt.title('Output Label Distribution')
plt.present()
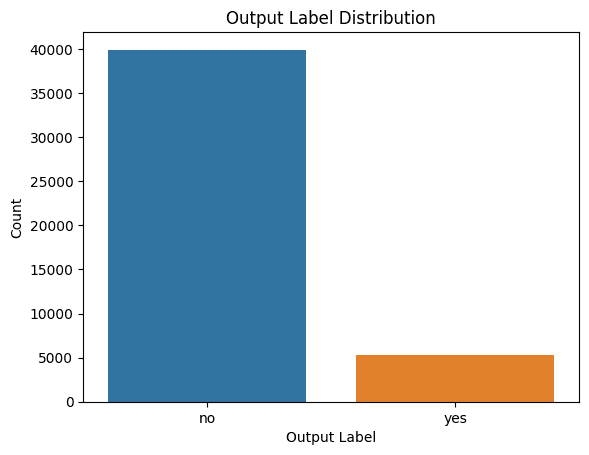
Distribution of Class Labels
We see that there’s class imbalance. So in case you are constructing a mannequin, you need to make sure you tackle class imbalance utilizing applicable resampling strategies.
Although information cleansing and preprocessing require efforts from the developer, let’s attempt to get a generic sequence of steps that works moderately nicely for a easy dataset.
Immediate: Are you able to give me a generic information cleansing and preprocessing pipeline based mostly on what we’ve finished to this point. Get primary data on the dataset, examine for and deal with lacking values, determine categorical columns, and encode categorical columns. Use solely pandas.
And right here it’s:
import pandas as pd
# Load the dataset right into a DataFrame
information = pd.read_csv('information.csv')
# Step 1: Primary Information
print(information.data())
# Step 2: Lacking Values
missing_values = information.isnull().sum()
print(missing_values)
# Step 3: Deal with Lacking Values
# Establish columns with lacking values
columns_with_missing_values = missing_values[missing_values > 0].index
# Impute lacking values utilizing fillna() or different appropriate methodology
information[columns_with_missing_values] = information[columns_with_missing_values].fillna(information[columns_with_missing_values].imply())
# Step 4: Get Categorical Columns
categorical_columns = information.select_dtypes(embody=['object']).columns
# Step 5: Encode Categorical Columns
# Carry out ordinal encoding or one-hot encoding utilizing pandas' get_dummies() operate
encoded_data = pd.get_dummies(information, columns=categorical_columns)
# Print the encoded information
print(encoded_data.head())
As seen, information science experience in synergy with ChatGPT will help make information cleansing and preprocessing easier and sooner. Now that you’ve the preprocessed dataset prepared, you’ll be able to take this additional by constructing a easy predictive mannequin on this financial institution advertising dataset.
If , it’s also possible to discover find out how to leverage ChatGPT for data exploration.
The financial institution advertising dataset is licensed below a Creative Commons Attribution 4.0 International (CC BY 4.0) license.
Moro,S., Rita,P., and Cortez,P.. (2012). Financial institution Advertising. UCI Machine Studying Repository. https://doi.org/10.24432/C5K306.
Bala Priya C is a developer and technical author from India. She likes working on the intersection of math, programming, information science, and content material creation. Her areas of curiosity and experience embody DevOps, information science, and pure language processing. She enjoys studying, writing, coding, and occasional! At present, she’s engaged on studying and sharing her information with the developer neighborhood by authoring tutorials, how-to guides, opinion items, and extra.
[ad_2]
Source link
