

[ad_1]
How can the effectiveness of imaginative and prescient transformers be leveraged in diffusion-based generative studying? This paper from NVIDIA introduces a novel mannequin referred to as Diffusion Imaginative and prescient Transformers (DiffiT), which mixes a hybrid hierarchical structure with a U-shaped encoder and decoder. This method has pushed the state-of-the-art in generative fashions and presents an answer to the problem of producing reasonable photographs.
Whereas prior fashions like DiT and MDT make use of transformers in diffusion fashions, DiffiT distinguishes itself by using time-dependent self-attention as an alternative of shift and scale for conditioning. Diffusion fashions, recognized for noise-conditioned rating networks, provide benefits in optimization, latent house protection, coaching stability, and invertibility, making them interesting for numerous purposes equivalent to text-to-image era, pure language processing, and 3D level cloud era.
Diffusion fashions have enhanced generative studying, enabling numerous and high-fidelity scene era via an iterative denoising course of. DiffiT introduces time-dependent self-attention modules to boost the eye mechanism at varied denoising levels. This innovation leads to state-of-the-art efficiency throughout datasets for picture and latent house era duties.
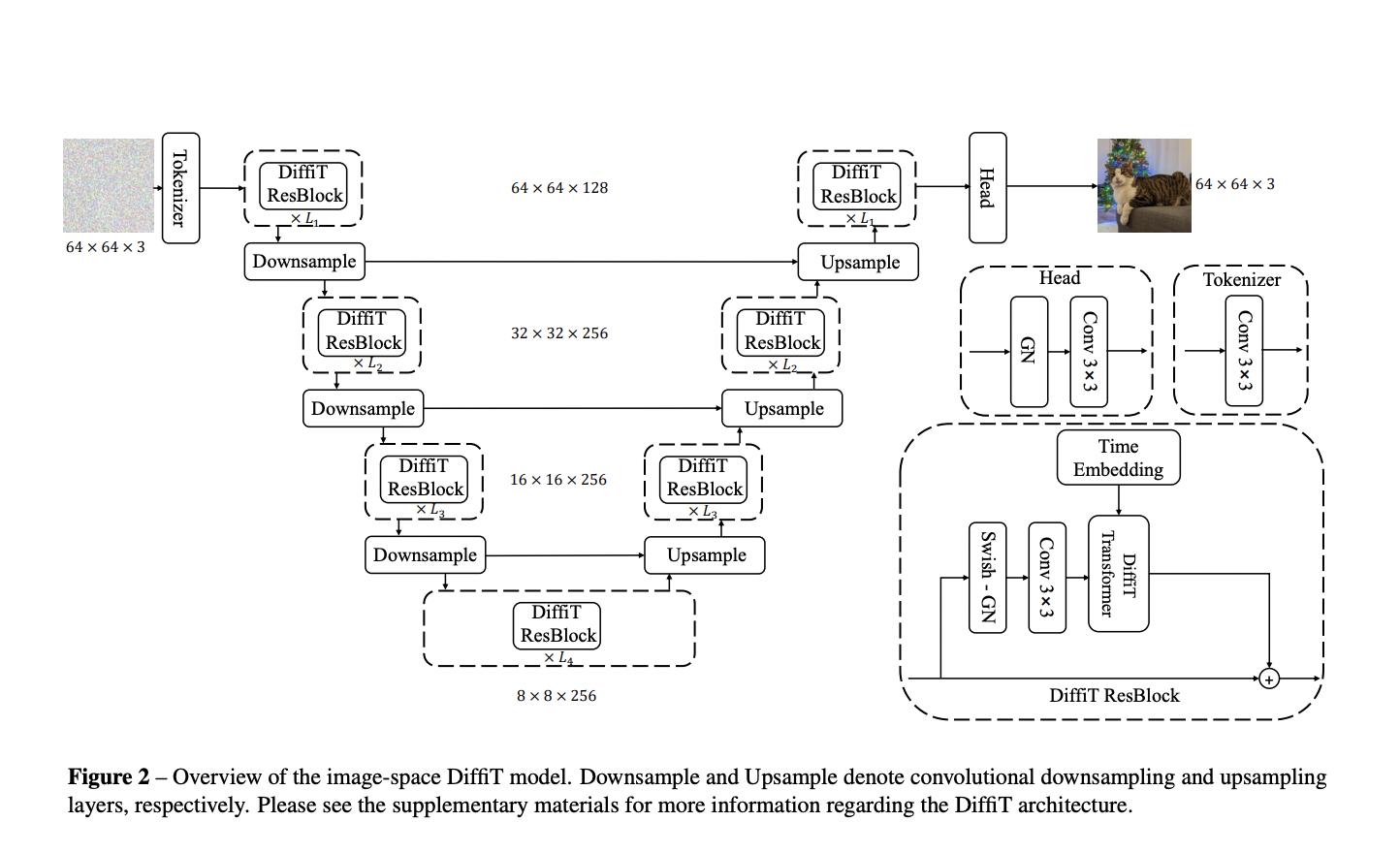
DiffiT contains a hybrid hierarchical structure with a U-shaped encoder and decoder. It incorporates a singular time-dependent self-attention module to adapt consideration habits throughout varied denoising levels. Primarily based on ViT, the encoder makes use of multiresolution steps with convolutional layers for downsampling. On the similar time, the decoder employs a symmetric U-like structure with the same multiresolution setup and convolutional layers for upsampling. The examine contains investigating classifier-free steering scales to boost generated pattern high quality and testing totally different scales in ImageNet-256 and ImageNet-512 experiments.
DiffiT has been proposed as a brand new method to producing high-quality photographs. This mannequin has been examined on varied class-conditional and unconditional synthesis duties and surpassed earlier fashions in pattern high quality and expressivity. DiffiT has achieved a brand new report within the Fréchet Inception Distance (FID) rating, with a powerful 1.73 on the ImageNet-256 dataset, indicating its skill to generate high-resolution photographs with distinctive constancy. The DiffiT transformer block is a vital part of this mannequin, contributing to its success in simulating samples from the diffusion mannequin via stochastic differential equations.
In conclusion, DiffiT is an distinctive mannequin for producing high-quality photographs, as evidenced by its state-of-the-art outcomes and distinctive time-dependent self-attention layer. With a brand new FID rating of 1.73 on the ImageNet-256 dataset, DiffiT produces high-resolution photographs with distinctive constancy, because of its DiffiT transformer block, which permits pattern simulation from the diffusion mannequin utilizing stochastic differential equations. The mannequin’s superior pattern high quality and expressivity in comparison with prior fashions are demonstrated via picture and latent house experiments.
Future analysis instructions for DiffiT embody exploring different denoising community architectures past conventional convolutional residual U-Nets to boost effectiveness and potential enhancements. Investigation into different strategies for introducing time dependency within the Transformer block goals to boost the modeling of temporal data through the denoising course of. Experimenting with totally different steering scales and techniques for producing numerous and high-quality samples is proposed to enhance DiffiT’s efficiency by way of FID rating. Ongoing analysis will assess DiffiT’s generalizability and potential applicability to a broader vary of generative studying issues in varied domains and duties.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to affix our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is obsessed with making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.
[ad_2]
Source link
