


[ad_1]
Object notion in photographs and movies unleashes the ability of machines to decipher the visible world. Like digital sleuths, laptop imaginative and prescient techniques scour pixels, recognizing, monitoring, and understanding the myriad objects that paint the canvas of digital experiences. This technological prowess, fueled by deep studying magic, opens doorways to transformative functions – from self-driving vehicles navigating city landscapes to digital assistants including extra intelligence to visible encounters.
Researchers from Huazhong College of Science and Expertise, ByteDance Inc., and Johns Hopkins College introduce GLEE, a flexible mannequin for object notion in photographs and movies. GLEE excels at finding and figuring out objects, demonstrating superior generalization throughout various duties with out task-specific adaptation. Its adaptability extends to integrating Giant Language Fashions, providing common object-level info for multi-modal research. The mannequin’s functionality to accumulate data from varied knowledge sources enhances its effectiveness in dealing with completely different object notion duties with improved effectivity.
GLEE integrates a picture encoder, textual content encoder, and visible prompter for multi-modal enter processing and generalized object illustration prediction. Educated on various datasets like Objects365, COCO, and Visible Genome, GLEE employs a unified framework for detecting, segmenting, monitoring, grounding, and figuring out objects in open-world situations. Primarily based on MaskDINO with a dynamic class head, the thing decoder makes use of similarity computation for prediction. After pretraining on object detection and occasion segmentation, joint coaching ends in state-of-the-art efficiency throughout varied downstream picture and video duties.
GLEE demonstrates outstanding versatility and enhanced generalization, successfully addressing various downstream duties with out task-specific adaptation. It excels in varied picture and video duties, reminiscent of object detection, occasion segmentation, grounding, multi-target monitoring, video occasion segmentation, video object segmentation, and interactive segmentation and monitoring. GLEE maintains state-of-the-art efficiency when built-in into different fashions, showcasing its representations’ versatility and effectiveness. The mannequin’s zero-shot generalization is additional improved by incorporating giant volumes of robotically labeled knowledge. Additionally, GLEE serves as a foundational mannequin.
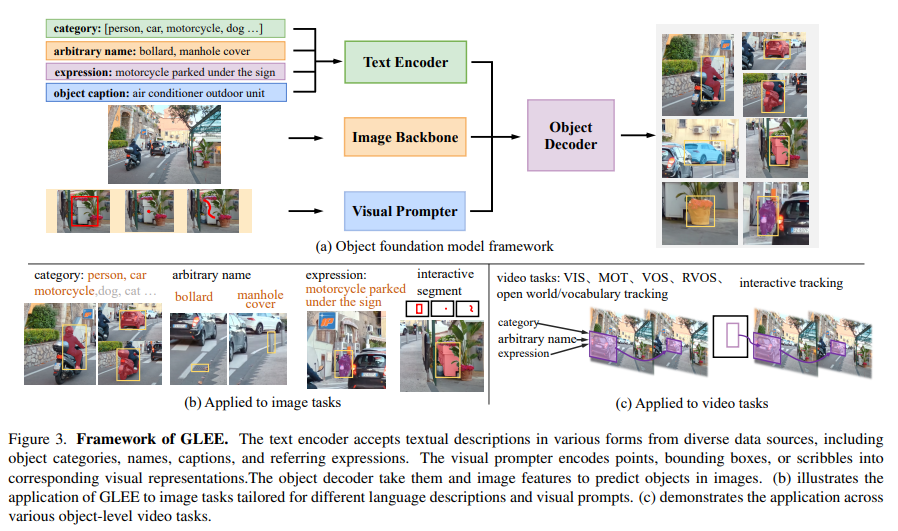
GLEE is a groundbreaking common object basis mannequin that overcomes limitations in present visible basis fashions, offering correct and common object-level info. It tackles various object-centric duties adeptly, showcasing outstanding versatility and superior generalization, notably excelling in zero-shot switch situations. GLEE incorporates various knowledge sources for common object representations, enabling scalable dataset enlargement and enhanced zero-shot capabilities. With unified help for multi-source knowledge, the mannequin accommodates extra annotations, attaining state-of-the-art efficiency throughout varied downstream duties, surpassing present fashions, even in zero-shot situations.
The scope of the analysis carried out to date and the route for future analysis may be centered on the next:
- Ongoing analysis is being carried out to broaden the capabilities of GLEE in dealing with advanced situations and difficult datasets, particularly these with long-tail distributions, to enhance its adaptability.
- Integrating specialised fashions goals to leverage GLEE’s common object-level representations, which might improve its efficiency in multi-modal duties.
- Researchers are additionally exploring GLEE’s potential for producing detailed picture content material primarily based on textual directions, much like fashions like DALL-E, by coaching it on in depth image-caption pairs.
- They improve GLEE’s object-level info by incorporating semantic context, which might broaden its utility in object-level duties.
- Additional growth of interactive segmentation and monitoring capabilities contains exploring various visible prompts and refining object segmentation expertise.
Try the Paper and Project. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to hitch our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
Whats up, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m at present pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m captivated with expertise and wish to create new merchandise that make a distinction.
[ad_2]
Source link
