

[ad_1]
Probably the most necessary challenges in machine studying is modeling intricate chance distributions. Diffusion probabilistic fashions DPMs purpose to study the inverse of a well-defined stochastic course of that progressively destroys data.
Picture synthesis, video manufacturing, and 3D enhancing are some areas the place denoising diffusion probabilistic fashions (DDPMs) have proven their price. Because of their giant parameter sizes and frequent inference steps per picture, present state-of-the-art DDPMs incur excessive computational prices. In actuality, not all customers have entry to ample monetary means to cowl the price of computation and storage. Due to this fact, it’s essential to research methods for successfully customizing publically accessible, massive, pre-trained diffusion fashions for particular person functions.
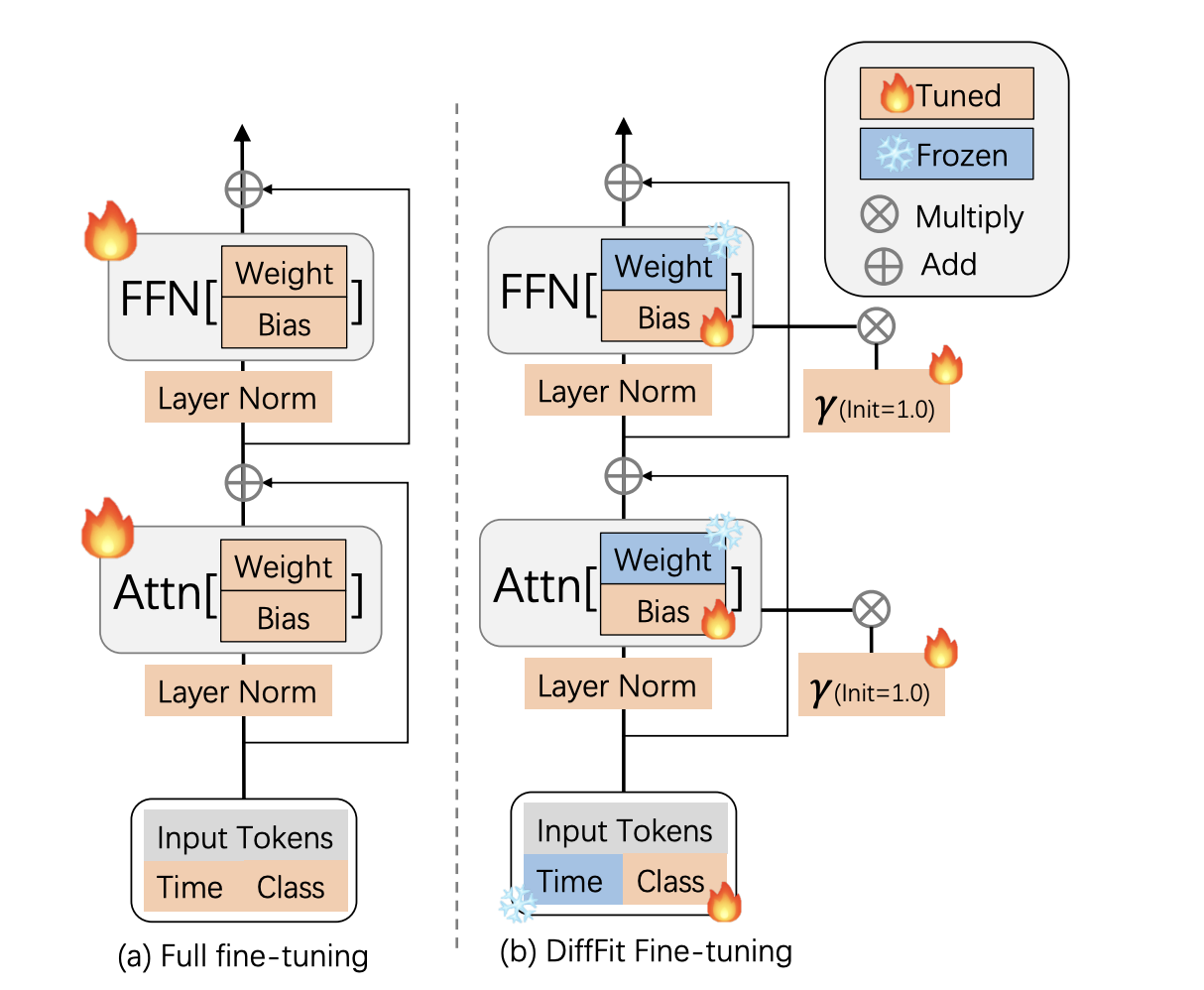
A brand new examine by Huawei Noah’s Ark Lab researchers makes use of the Diffusion Transformer as a basis and gives DiffFit, an easy and efficient fine-tuning method for big diffusion fashions. Current NLP (BitFit) analysis has proven that adjusting the bias time period can fine-tune a pre-trained mannequin for downstream duties. The researchers needed to adapt these efficient tuning methods for picture technology. They first instantly apply BitFi, and to enhance function scaling and generalizability, they incorporate learnable scaling components to specific layers of the mannequin, with a default worth of 1.0 and dataset-specific tweaks. The empirical outcomes point out that together with strategic locations all through the mannequin is essential for enhancing the Frechet Inception Distance (FID) rating.
BitFit, AdaptFormer, LoRA, and VPT are solely a number of the parameter-efficient fine-tuning methods the group used and in contrast over 8 downstream datasets. Concerning the variety of trainable parameters and the FID trade-off, the findings present that DiffFit performs higher than these different strategies. As well as, the researchers additionally discovered that their DiffFit technique could possibly be simply employed to fine-tune a low-resolution diffusion mannequin, permitting it to adapt to high-resolution image manufacturing at an inexpensive value just by treating high-resolution photographs as a definite area from low-resolution ones.
DiffFit outperformed the prior state-of-the-art diffusion fashions on ImageNet 512×512 by beginning with a pretrained ImageNet 256×256 checkpoint and fine-tuning DIT for under 25 epochs. DiffFit outperforms the unique DiT-XL/2-512 mannequin (which has 640M trainable parameters and 3M iterations) by way of FID whereas having solely roughly 0.9 million trainable parameters. It additionally requires 30% much less time to coach.
Total, DiffFit seeks to supply perception into the environment friendly fine-tuning of larger diffusion fashions by establishing a easy and highly effective baseline for parameter-efficient fine-tuning in image manufacturing.
Try the Paper. Don’t overlook to hitch our 19k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra. In case you have any questions relating to the above article or if we missed something, be at liberty to e mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Tanushree Shenwai is a consulting intern at MarktechPost. She is presently pursuing her B.Tech from the Indian Institute of Expertise(IIT), Bhubaneswar. She is a Knowledge Science fanatic and has a eager curiosity within the scope of software of synthetic intelligence in varied fields. She is keen about exploring the brand new developments in applied sciences and their real-life software.
[ad_2]
Source link
