

[ad_1]
Learn the way siamese BERT networks precisely rework sentences into embeddings

It’s no secret that transformers made evolutionary progress in NLP. Based mostly on transformers, many different machine studying fashions have advanced. Certainly one of them is BERT which primarily consists of a number of stacked transformer encoders. Other than getting used for a set of various issues like sentiment evaluation or query answering, BERT grew to become more and more common for establishing phrase embeddings — vectors of numbers representing semantic meanings of phrases.
Representing phrases within the type of embeddings gave an enormous benefit as machine studying algorithms can’t work with uncooked texts however can function on vectors of vectors. This enables evaluating completely different phrases by their similarity by utilizing a normal metric like Euclidean or cosine distance.
The issue is that, in apply, we regularly must assemble embeddings not for single phrases however as an alternative for entire sentences. Nevertheless, the fundamental BERT model builds embeddings solely on the phrase degree. Resulting from this, a number of BERT-like approaches had been later developed to unravel this downside which might be mentioned on this article. By progressively discussing them, we are going to then attain to the state-of-the-art mannequin referred to as SBERT.
For getting a deep understanding of how SBERT works below the hood, it is suggested that you’re already accustomed to BERT. If not, the earlier a part of this text sequence explains it intimately.
To begin with, allow us to remind how BERT processes info. As an enter, it takes a [CLS] token and two sentences separated by a particular [SEP] token. Relying on the mannequin configuration, this info is processed 12 or 24 instances by multi-head consideration blocks. The output is then aggregated and handed to a easy regression mannequin to get the ultimate label.

For extra info on BERT interior workings, you possibly can check with the earlier a part of this text sequence:
Cross-encoder structure
It’s attainable to make use of BERT for calculation of similarity between a pair of paperwork. Take into account the target of discovering essentially the most comparable pair of sentences in a big assortment. To unravel this downside, every attainable pair is put contained in the BERT mannequin. This results in quadratic complexity throughout inference. As an example, coping with n = 10 000 sentences requires n * (n — 1) / 2 = 49 995 000 inference BERT computations which isn’t actually scalable.
Different approaches
Analysing the inefficiency of cross-encoder structure, it appears logical to precompute embeddings independently for every sentence. After that, we are able to immediately compute the chosen distance metric on all pairs of paperwork which is way quicker than feeding a quadratic variety of pairs of sentences to BERT.
Sadly, this strategy isn’t attainable with BERT: the core downside of BERT is that each time two sentences are handed and processed concurrently making it tough to get embeddings that may independently signify solely a single sentence.
Researchers tried to get rid of this problem by utilizing the output of the [CLS] token embedding hoping that it could comprise sufficient info to signify a sentence. Nevertheless, the [CLS] turned out to not be helpful in any respect for this process just because it was initially pre-trained in BERT for subsequent sentence prediction.
One other strategy was to cross a single sentence to BERT after which averaging the output token embeddings. Nevertheless, the obtained outcomes had been even worse than merely averaging GLoVe embeddings.
Deriving impartial sentence embeddings is without doubt one of the major issues of BERT. To alleviate this facet, SBERT was developed.
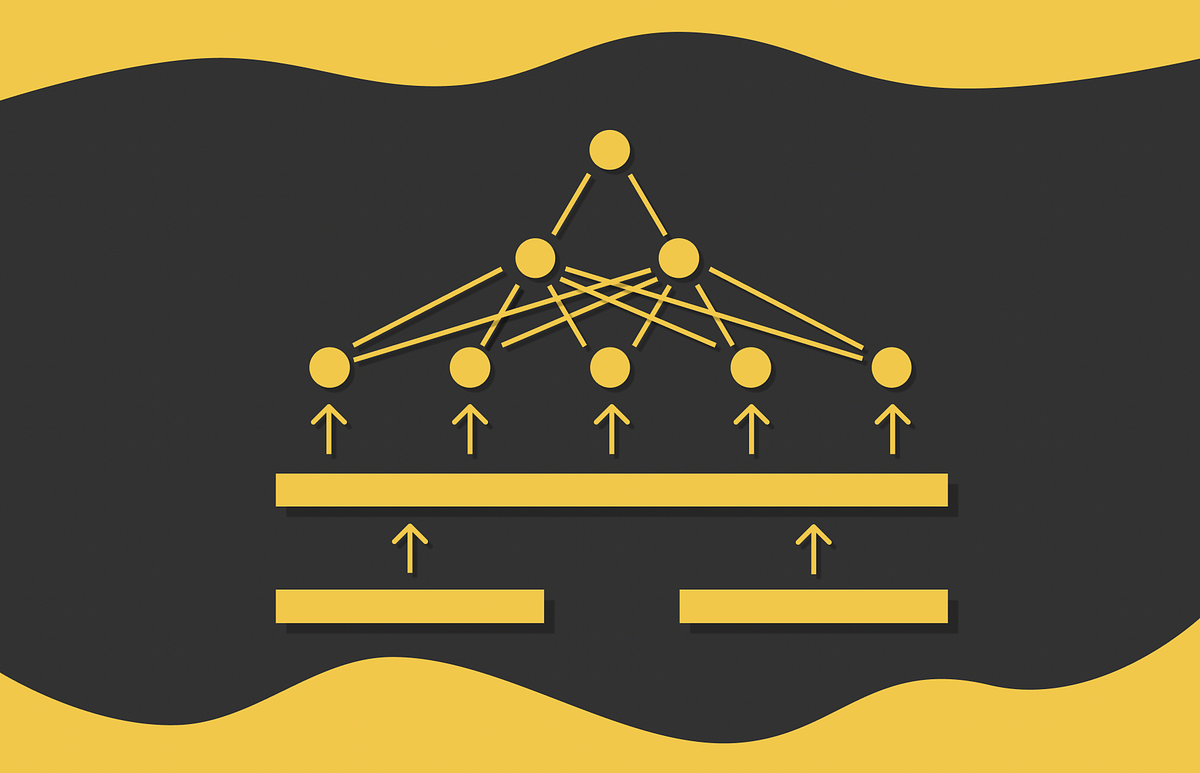
SBERT introduces the Siamese community idea which means that every time two sentences are handed independently via the identical BERT mannequin. Earlier than discussing SBERT structure, allow us to check with a delicate word on Siamese networks:
More often than not in scientific papers, a siamese community structure is depicted with a number of fashions receiving so many inputs. In actuality, it may be considered a single mannequin with the identical configuration and weights shared throughout a number of parallel inputs. Every time mannequin weights are up to date for a single enter, they’re equally up to date for different inputs as properly.

Getting again to SBERT, after passing a sentence via BERT, a pooling layer is utilized to BERT embeddings to get their decrease dimensionality illustration: preliminary 512 768-dimensional vectors are reworked to a single 768-dimensional vector. For the pooling layer, SBERT authors suggest selecting a mean-pooling layer as a default one, although in addition they point out that’s attainable to make use of the max-pooling technique or just to take the output of the [CLS] token as an alternative.
When each sentences are handed via pooling layers, we have now two 768-dimensional vectors u and v. By utilizing these two vectors, authors suggest three approaches for optimising completely different aims that are going to be mentioned beneath.
Classification goal operate
The purpose of this downside is to accurately classify a given pair of sentences in one among a number of lessons.
After the technology of embeddings u and v, the researchers discovered it helpful to generate one other vector derived from these two because the element-wise absolute distinction |u-v|. In addition they tried different function engineering strategies however this one confirmed one of the best outcomes.
Lastly, three vectors u, v and |u-v| are concatenated, multiplied by a trainable weight matrix W and the multiplication result’s fed into the softmax classifier which outputs normalised chances of sentences akin to completely different lessons. The cross-entropy loss operate is used to replace the weights of the mannequin.

One of the vital common present issues was solved with this goal is NLI (Natural Language Inference) the place for a given pair of sentences A and B which outline speculation and premise it’s essential to predict whether or not the speculation is true (entailment), false (contradiction) or undetermined (impartial) given the premise. For this downside, the inference course of is similar as for the coaching.
As acknowledged within the paper, the SBERT mannequin is initially skilled on two datasets SNLI and MultiNLI which comprise one million sentence pairs with corresponding labels entailment, contradiction or impartial. After that, the paper researchers point out particulars about SBERT tuning parameters:
“We fine-tune SBERT with a 3-way softmax-classifier goal operate for one epoch. We used a batch-size of 16, Adam optimizer with studying price 2e−5, and a linear studying price warm-up over 10% of the coaching knowledge. Our default pooling technique is imply.”
Regression goal operate
On this formulation, after getting vectors u and v, the similarity rating between them is immediately computed by a selected similarity metric. The anticipated similarity rating is in contrast with the true worth and the mannequin is up to date by utilizing the MSE loss operate. By default, authors select cosine similarity because the similarity metric.

Throughout inference, this structure can be utilized in one among two methods:
- By a given sentence pair, it’s attainable to calculate the similarity rating. The inference workflow is totally the identical as for the coaching.
- For a given sentence, it’s attainable to extract its sentence embedding (proper after making use of the pooling layer) for some later use. That is notably helpful once we are given a big assortment of sentences with the target to calculate pairwise similarity scores between them. By operating every sentence via BERT solely as soon as, we extract all the required sentence embeddings. After that, we are able to immediately calculate the chosen similarity metric between all of the vectors (no doubt, it nonetheless requires a quadratic variety of comparisons however on the similar time we keep away from quadratic inference computations with BERT because it was earlier than).
Triplet goal operate
The triplet goal introduces a triplet loss which is calculated on three sentences normally named anchor, optimistic and damaging. It’s assumed that anchor and optimistic sentences are very shut to one another whereas anchor and damaging are very completely different. In the course of the coaching course of, the mannequin evaluates how nearer the pair (anchor, optimistic) is, in comparison with the pair (anchor, damaging). Mathematically, the next loss operate is minimised:

Margin ε ensures {that a} optimistic sentence is nearer to the anchor a minimum of by ε than the damaging sentence to the anchor. In any other case, the loss turns into higher than 0. By default, on this formulation, the authors select the Euclidean distance because the vector norm and the parameter ε is ready to 1.
The triplet SBERT structure differs from the earlier two in a manner that the mannequin now accepts in parallel three enter sentences (as an alternative of two).

SentenceTransformers is a state-of-the-art Python library for constructing sentence embeddings. It comprises a number of pretrained models for various duties. Constructing embeddings with SentenceTransformers is straightforward and an instance is proven within the code snippet beneath.

Constructed embeddings will be then used for similarity comparability. Each mannequin is skilled for a sure process, so it’s all the time vital to decide on an acceptable similarity metric for comparability by referring to the documentation.
We’ve got walked via one of many superior NLP fashions for acquiring sentence embeddings. By lowering a quadratic variety of BERT inference executions to linear, SBERT achieves a large development in velocity whereas sustaining excessive accuracy.
To lastly perceive how vital this distinction is, it is sufficient to check with the instance described within the paper the place researchers tried to search out essentially the most comparable pair amongst n = 10000 sentences. On a contemporary V100 GPU, this process took about 65 hours with BERT and solely 5 seconds with SBERT! This instance demonstrates that SBERT is a large development in NLP.
All photographs until in any other case famous are by the writer
[ad_2]
Source link
