

[ad_1]
Many open-source initiatives have developed complete linguistic fashions that may be educated to hold out particular duties. These fashions can present helpful responses to questions and instructions from customers. Notable examples embody the LLaMA-based Alpaca and Vicuna and the Pythia-based OpenAssistant and Dolly.
Despite the fact that new fashions are being launched each week, the neighborhood nonetheless struggles to benchmark them correctly. Since LLM assistants’ considerations are sometimes obscure, making a benchmarking system that may mechanically assess the standard of their solutions is troublesome. Human analysis by way of pairwise comparability is usually required right here. A scalable, incremental, and distinctive benchmark system based mostly on pairwise comparability is right.
Few of the present LLM benchmarking programs meet all of those necessities. Traditional LLM benchmark frameworks like HELM and lm-evaluation-harness present multi-metric measures for research-standard duties. Nonetheless, they don’t consider free-form questions nicely as a result of they don’t seem to be based mostly on pairwise comparisons.
LMSYS ORG is a company that develops massive fashions and programs which might be open, scalable, and accessible. Their new work presents Chatbot Enviornment, a crowdsourced LLM benchmark platform with nameless, randomized battles. As with chess and different aggressive video games, the Elo score system is employed in Chatbot Enviornment. The Elo score system reveals promise for delivering the aforementioned fascinating high quality.
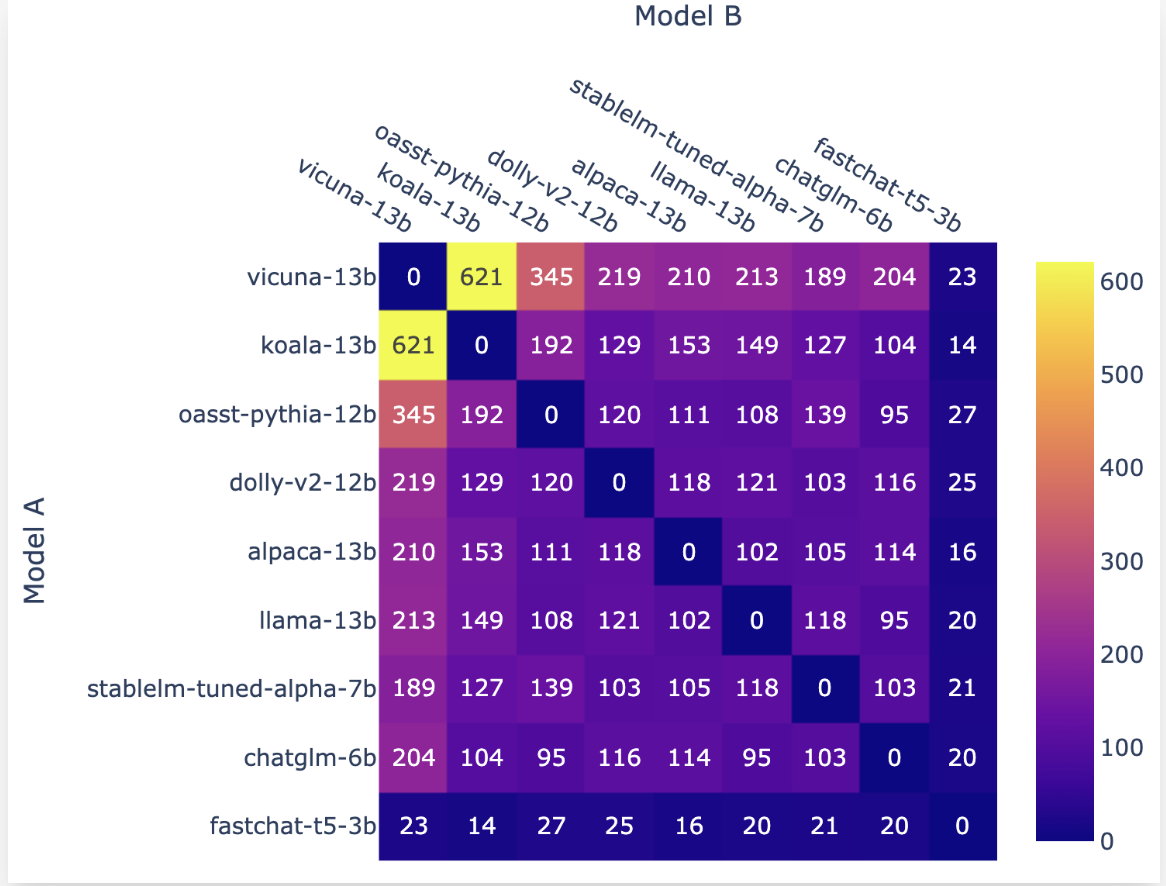
They began amassing info per week in the past once they opened the sector with many well-known open-source LLMs. Some examples of real-world purposes of LLMs could be seen within the crowdsourcing knowledge assortment technique. A consumer can examine and distinction two nameless fashions whereas chatting with them concurrently within the enviornment.
FastChat, the multi-model serving system, hosted the sector at https://enviornment.lmsys.org. An individual getting into the sector will face a dialog with two anonymous fashions. When shoppers obtain feedback from each fashions, they will proceed the dialog or vote for which one they like. After a vote is forged, the fashions’ identities will probably be unmasked. Customers can proceed conversing with the identical two nameless fashions or begin a contemporary battle with two new fashions. The system information all consumer exercise. Solely when the mannequin names have obscured the votes within the evaluation used. About 7,000 authentic, nameless votes have been tallied because the enviornment went dwell per week in the past.
Sooner or later, they wish to implement improved sampling algorithms, match procedures, and serving programs to accommodate a better number of fashions and provide granular ranks for numerous duties.
Take a look at the Project and Notebook. Don’t neglect to hitch our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra. In case you have any questions concerning the above article or if we missed something, be at liberty to e mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Tanushree Shenwai is a consulting intern at MarktechPost. She is at present pursuing her B.Tech from the Indian Institute of Know-how(IIT), Bhubaneswar. She is a Information Science fanatic and has a eager curiosity within the scope of software of synthetic intelligence in numerous fields. She is keen about exploring the brand new developments in applied sciences and their real-life software.
[ad_2]
Source link
