

[ad_1]
Pure Language Processing has advanced considerably lately, particularly with the creation of subtle language fashions. Nearly all pure language duties, together with translation and reasoning, have seen notable advances within the efficiency of well-known fashions like GPT 3.5, GPT 4, BERT, PaLM, and so on. A variety of benchmarks are used to entry and consider these developments within the area of Synthetic Intelligence. Benchmark is mainly a group of standardized duties made to check language fashions’ (LLMs’) talents.
Contemplating the GLUE and the SuperGLUE benchmark, which had been among the many first few language understanding benchmarks, fashions like BERT and GPT-2 had been tougher as language fashions have been beating these benchmarks, sparking a race between the event of the fashions and the issue of the benchmarks. Scaling up the fashions by making them larger and coaching them on larger datasets is the important thing to enhanced efficiency. LLMs have demonstrated excellent efficiency on a wide range of benchmarks that gauge their capability for data and quantitative reasoning, however when these fashions rating greater on the present requirements, it’s clear that these benchmarks are not helpful for assessing the fashions’ capabilities.
To handle the restrictions, a group of researchers has proposed a brand new and distinctive benchmark known as ARB (Superior Reasoning Benchmark). ARB is made to convey tougher points in a wide range of topic areas, resembling arithmetic, physics, biology, chemistry, and regulation. ARB, in distinction to earlier benchmarks, focuses on advanced reasoning issues in an effort to enhance LLM efficiency. The group has additionally launched a set of math and physics questions as a subset of ARB that demand subtle symbolic considering and in-depth topic data. These points are exceptionally troublesome and outdoors the scope of LLMs as they exist right now.
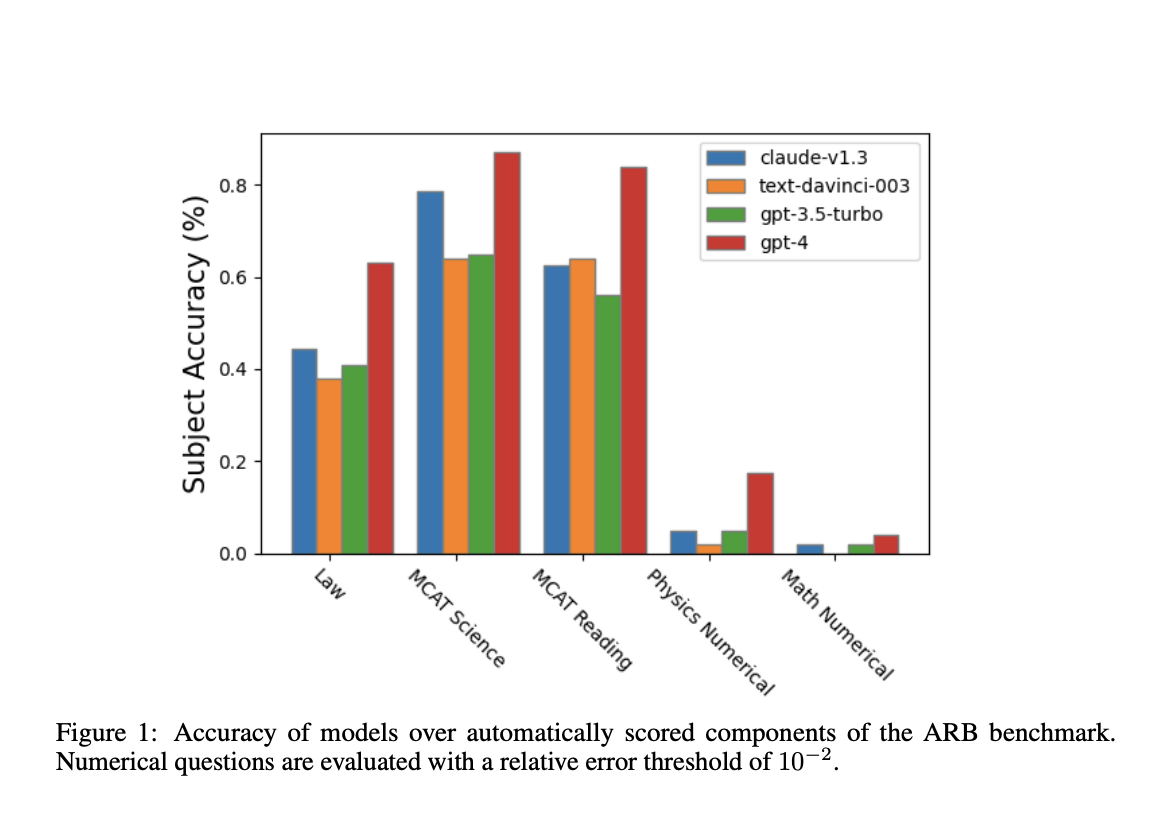
The group has evaluated these new fashions on the ARB benchmark, together with GPT-4 and Claude. These fashions struggled to handle the complexity of those difficulties, as evidenced by the findings, which exhibit that they carry out on the tougher duties contained in ARB with scores considerably beneath 50%. The group has additionally demonstrated a rubric-based analysis strategy to enhance the analysis course of. Through the use of this technique, GPT-4 could consider its personal intermediate reasoning processes because it tries to resolve ARB issues. This broadens the scope of the overview course of and sheds gentle on the mannequin’s problem-solving technique.
The symbolic subset of ARB has been subjected to human overview as nicely. Human annotators have been requested to resolve the issues and supply their very own evaluations. There was a promising settlement between the human evaluators and GPT-4’s rubric-based analysis scores, suggesting that the mannequin’s self-assessment aligns fairly nicely with human judgment. With tons of of points requiring skilled reasoning in quantitative fields, the place LLMs have sometimes had issue, the brand new dataset considerably outperforms earlier benchmarks.
In distinction to the multiple-choice questions in previous benchmarks, a large variety of the problems are made up of short-answer and open-response questions, making it tougher for LLMs to be evaluated. A extra correct analysis of the fashions’ capacities to deal with sophisticated, real-world issues is made potential by the mixture of expert-level reasoning duties and extra sensible query codecs.
Take a look at the Paper, Github, and Project. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t neglect to hitch our 27k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
Tanya Malhotra is a remaining yr undergrad from the College of Petroleum & Vitality Research, Dehradun, pursuing BTech in Pc Science Engineering with a specialization in Synthetic Intelligence and Machine Studying.
She is a Knowledge Science fanatic with good analytical and demanding considering, together with an ardent curiosity in buying new expertise, main teams, and managing work in an organized method.
[ad_2]
Source link
