


[ad_1]
Textual content-to-image technology is a singular subject the place language and visuals converge, creating an fascinating intersection within the ever-changing world of AI. This know-how converts textual descriptions into corresponding photographs, merging the complexities of understanding language with the creativity of visible illustration. As the sphere matures, it encounters challenges, significantly in producing high-quality photographs effectively from textual prompts. This effectivity isn’t just about pace but additionally in regards to the computational sources required, impacting the sensible software of such know-how.
Historically, text-to-image technology has relied closely on fashions like latent diffusion. These fashions function by iteratively lowering noise from a picture, simulating a reverse diffusion course of. Whereas they’ve efficiently created detailed and correct photographs, they arrive with a value – computational depth and an absence of interpretability. Researchers have been investigating different approaches that would stability effectivity and high quality.
Meet aMUSEd: a breakthrough on this subject developed by a Hugging Face and Stability AI collaborative workforce. This revolutionary mannequin is a streamlined model of the MUSE framework, designed to be light-weight but efficient. What units aMUSEd aside is its considerably diminished parameter rely, which stands at simply 10% of MUSE’s parameters. This discount is a deliberate transfer to reinforce picture technology pace with out compromising the output high quality.
The core of aMUSEd’s methodology lies in its distinctive architectural selections. It integrates a CLIP-L/14 textual content encoder and employs a U-ViT spine. The U-ViT spine is essential because it eliminates the necessity for a super-resolution mannequin, a standard requirement in lots of high-resolution picture technology processes. By doing so, aMUSEd simplifies the mannequin construction and reduces the computational load, making it a extra accessible software for varied purposes. The mannequin is educated to generate photographs immediately at resolutions of 256×256 and 512×512, showcasing its means to provide detailed visuals with out requiring intensive computational sources.
Relating to efficiency, aMUSEd units new requirements within the subject. Its inference pace outshines that of non-distilled diffusion fashions and is on par with among the few-step distilled diffusion fashions. This pace is essential for real-time purposes and demonstrates the mannequin’s sensible viability. Furthermore, aMUSEd excel in duties like zero-shot in-painting and single-image type switch, showcasing its versatility and adaptableness. In assessments, the mannequin has proven specific prowess in producing much less detailed photographs, akin to landscapes, indicating its potential for purposes in areas like digital setting design and fast visible prototyping.
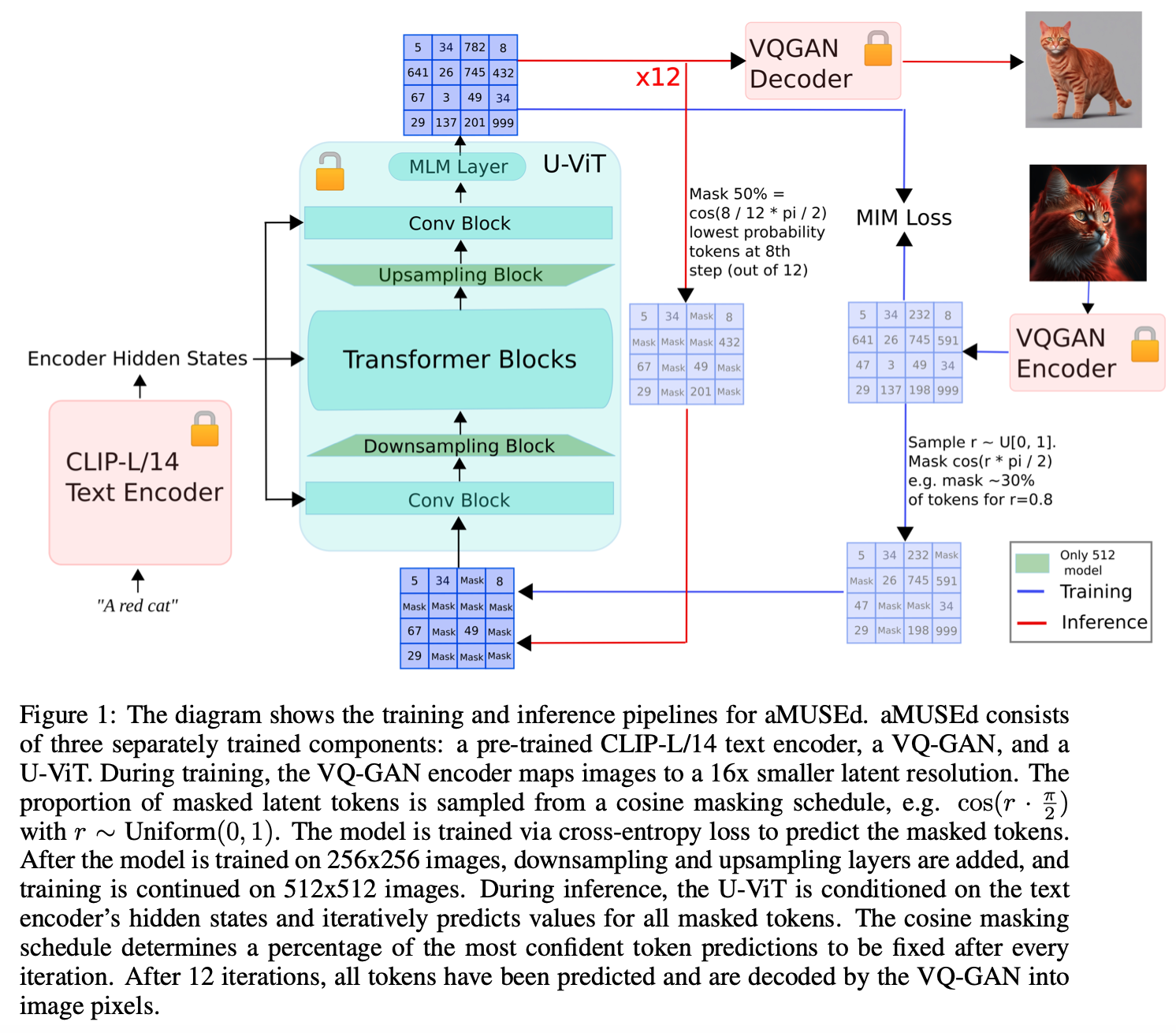
The event of aMUSEd represents a notable stride ahead in producing photographs from textual content. Addressing the vital problem of computational effectivity opens new avenues for making use of this know-how in additional various and resource-constrained environments. Its means to take care of high quality whereas drastically lowering computational calls for makes it a mannequin that would encourage future analysis and improvement. As we transfer ahead, applied sciences like aMUSEd may redefine the boundaries of creativity, mixing the realms of language and imagery in methods beforehand unimagined.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter. Be a part of our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a deal with Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical data with sensible purposes. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.
[ad_2]
Source link
