

[ad_1]
Pretrained giant language fashions (LLMs) boast outstanding language processing skills however require substantial computational sources. Binarization, which reduces mannequin weights to a single bit, provides an answer by drastically decreasing computation and reminiscence calls for. Nevertheless, current quantization strategies should assist preserve LLM efficiency at such low bit widths. This challenges reaching environment friendly deployment of LLMs whereas sustaining effectiveness in varied language processing duties.
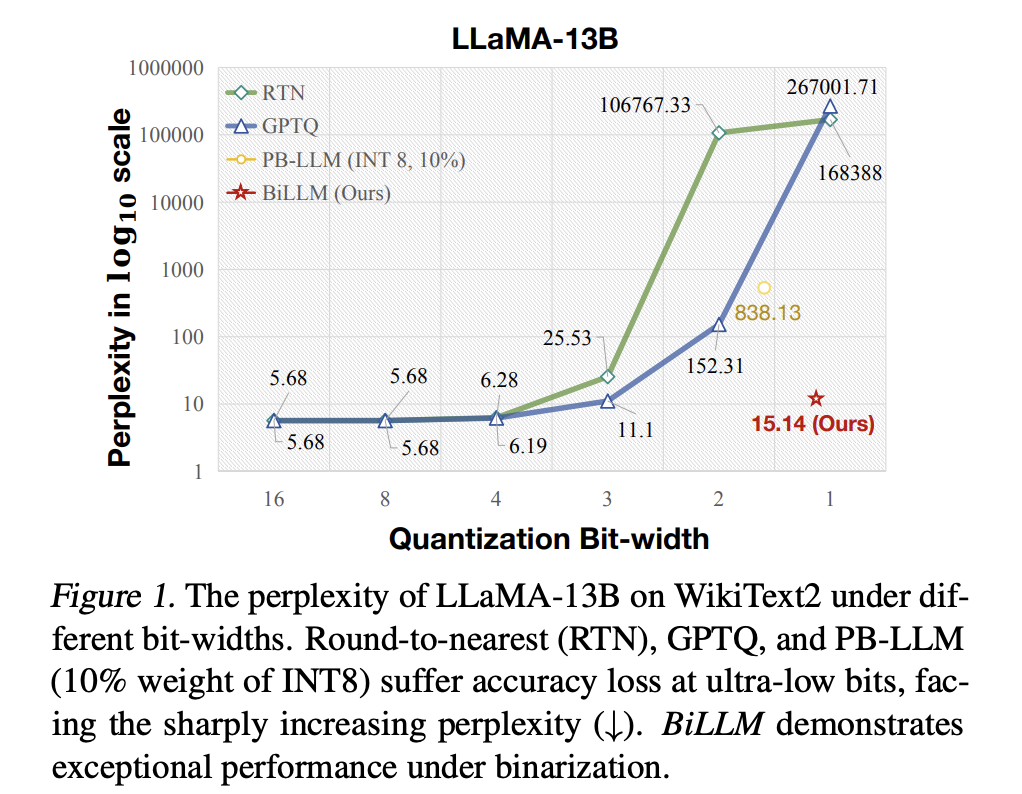
Current works have highlighted the distinctive efficiency of LLMs like OPT and LLaMA throughout varied benchmarks, however their deployment on memory-constrained gadgets stays difficult. Mannequin quantization, significantly Put up-Coaching Quantization (PTQ), successfully compresses LLMs, saving GPU reminiscence consumption. Whereas PTQ strategies have succeeded in 8-bit and 4-bit quantization, the increasing measurement of LLMs necessitates extra aggressive approaches like neural community binarization. Nevertheless, current PTQ strategies face efficiency collapse beneath ultra-low bit quantization.
Researchers from the College of Hong Kong, Beihang College, and ETH Zurich launched BiLLM, a groundbreaking 1-bit post-training quantization scheme designed for pre-trained LLMs. BiLLM makes use of weight distribution evaluation to determine salient weights and employs a binary residual approximation technique to reduce compression loss. It additionally introduces an optimum splitting seek for correct binarization of non-salient weights with a bell-shaped distribution.
BiLLM introduces a novel 1-bit post-training quantization methodology for LLMs, leveraging weight sensitivity evaluation through the Hessian matrix. It employs a structured number of salient weights and optimum splitting for non-salient weights, minimizing quantization error. BiLLM implements binary residual approximation for salient weights and bell-shaped distribution splitting for non-salient ones, reaching high-accuracy inference with ultra-low bit widths and environment friendly deployment on GPUs.

BiLLM, applied on PyTorch and Huggingface libraries, presents a groundbreaking 1-bit PTQ framework for LLMs. It surpasses current strategies like GPTQ and PB-LLM, reaching superior perplexity outcomes throughout varied mannequin sizes and datasets, together with WikiText2, PTB, and C4. BiLLM‘s structured salient binarization and optimum splitting of non-salient weights considerably improve binary efficiency, demonstrating its common applicability and robustness in various LLM settings.
In conclusion, Researchers from the College of Hong Kong, Beihang College, and ETH Zurich launched BiLLM, a novel post-training binary quantization methodology for compressing pre-trained LLMs. By leveraging binary residual approximation for salient weights and optimum segmentation for non-salient ones, BiLLM achieves ultra-low bit quantization with out important lack of precision. It units a brand new frontier in LLMs’ bit-width quantization, enabling deployment in edge eventualities and resource-constrained gadgets whereas sustaining efficiency ensures.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and Google News. Be part of our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our newsletter..
Don’t Overlook to hitch our Telegram Channel
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.
[ad_2]
Source link
