

[ad_1]
The latest iteration of synthetic intelligence makes use of basis fashions. Such basis fashions or “generalist” fashions could also be used for quite a few downstream duties with out specific coaching as an alternative of constructing AI fashions that sort out particular duties separately. For example, the huge pre-trained language fashions GPT-3 and GPT-4 have revolutionized the fundamental AI mannequin. LLM might use few-shot or zero-shot studying to use its data to new duties for which it has but to be taught. Multitask studying, which allows LLM to be taught from implicit duties in its coaching corpus by accident, is partly in charge for this.
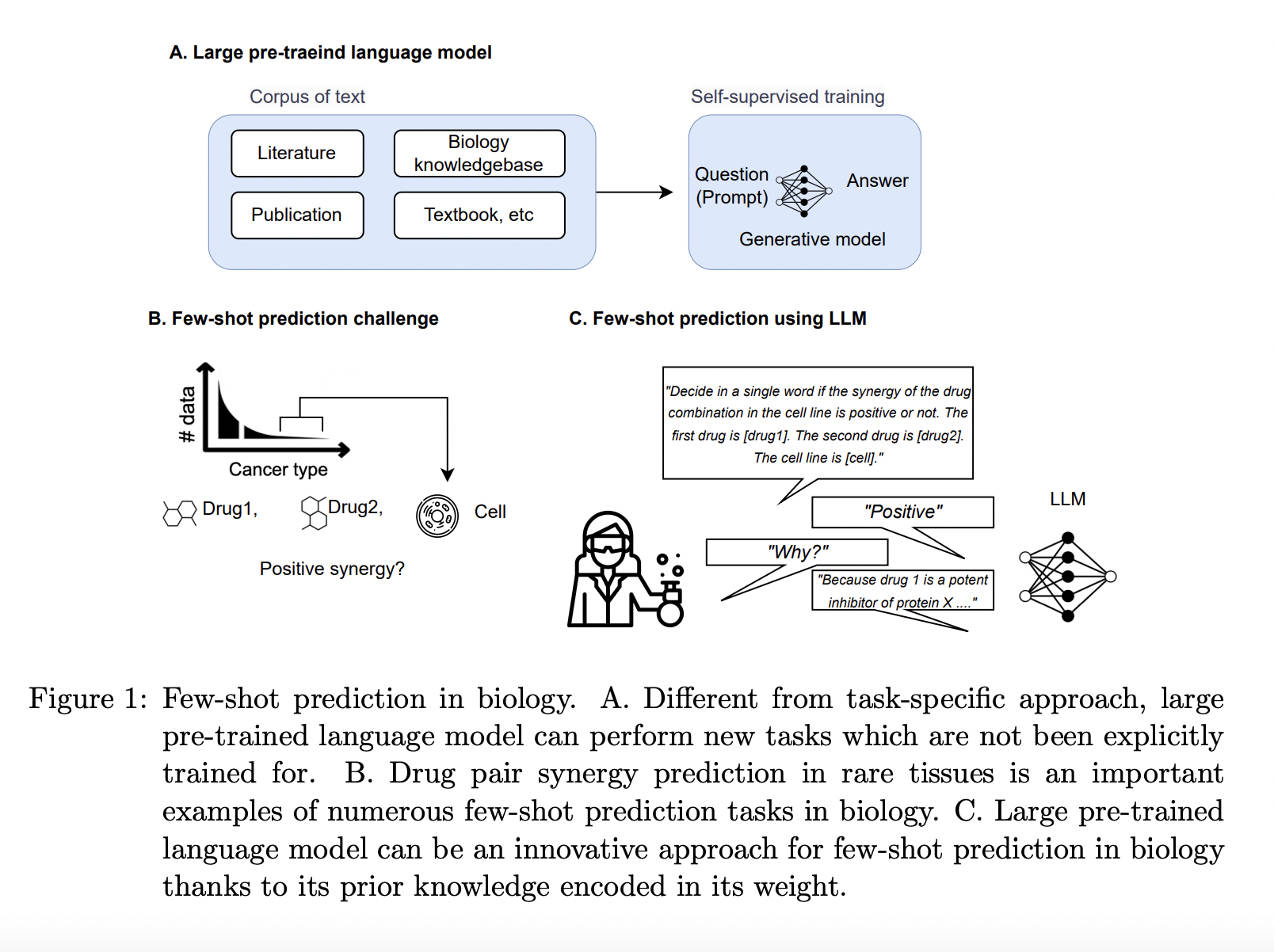
Though LLM has demonstrated proficiency in few-shot studying in a number of disciplines, together with pc imaginative and prescient, robotics, and pure language processing, its generalizability to issues that can not be noticed in additional complicated fields like biology has but to be totally examined. Understanding the concerned events and underlying organic techniques is important to deduce unobserved organic reactions. Most of this info is in free-text literature, which is perhaps used to coach LLMs, whereas structured databases solely encapsulate a small quantity. Researchers from the College of Texas, the College of Massachusetts Amherst, and the College of Texas Well being Science Heart imagine that LLMs, which extract earlier data from unstructured literature, is perhaps a inventive technique for organic prediction challenges the place there’s a lack of structured information and small pattern sizes.
An important downside in such a few-shot organic prediction is the prediction of remedy pair synergy in most cancers sorts that haven’t been properly explored. Drug mixtures in remedy at the moment are a standard apply for managing difficult-to-treat circumstances, together with most cancers, infectious infections, and neurological issues. Mixture remedy often provides superior therapeutic outcomes over single-drug remedy. Medicine discovery and improvement analysis has more and more targeted on predicting the synergy of remedy pairs. Drug pair synergy describes how utilizing two medicines collectively has a better therapeutic influence than utilizing every individually. As a result of quite a few potential mixtures and complexity of the underlying organic techniques, forecasting remedy pair synergy can’t be simple.
A number of computational strategies have been created to anticipate remedy pair synergy, notably using machine studying. Giant datasets of in vitro experiment outcomes for drug mixtures could also be used to coach machine studying algorithms to seek out traits and forecast the probability of synergy for a novel remedy pair. A comparatively small quantity of experiment information is accessible for some tissues, comparable to bone and tender tissues. In distinction, most information pertains to widespread most cancers kinds in choose tissues, like breast and lung most cancers. The amount of coaching information out there for remedy pair synergy prediction is constrained by the bodily demanding and costly nature of acquiring cell traces from these tissues. Giant dataset-dependent machine studying fashions might need assistance to coach.
Early analysis ignored these tissues’ organic and mobile variations and extrapolated the synergy rating to cell traces in different tissues based mostly on relational or contextual info. By using numerous and high-dimensional information, comparable to genomic or chemical profiles, one other line of analysis has tried to scale back the disparity throughout tissues. Regardless of the promising findings in some tissues, these strategies should be used on tissues with adequate information to change their mannequin with the various parameters for these high-dimensional properties. They need to handle the aforementioned downside confronted by LLMs on this work. They assert that the scientific literature nonetheless accommodates helpful info on most cancers sorts with sparse organized information and inconsistent traits.
It isn’t simple to manually collect prognostic information about such organic issues from literature. Using previous info from scientific literature saved in LLMs is their novel technique. They created a mannequin that converts the prediction job right into a pure language inference problem and generates responses based mostly on data embodied in LLMs, known as the few-shot drug pair synergy prediction mannequin. Their experimental findings present that their LLM-based few-shot prediction mannequin beat sturdy tabular prediction fashions in most eventualities and attained appreciable accuracy even in zero-shot settings. As a result of it demonstrates a excessive potential within the “generalist” biomedical synthetic intelligence, this extraordinary few-shot prediction efficiency in one of the vital tough organic prediction duties has a significant and well timed relevance to a big neighborhood of biomedicine.
Take a look at the Paper. Don’t overlook to affix our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra. When you’ve got any questions concerning the above article or if we missed something, be at liberty to e-mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at present pursuing his undergraduate diploma in Knowledge Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on tasks aimed toward harnessing the facility of machine studying. His analysis curiosity is picture processing and is obsessed with constructing options round it. He loves to attach with individuals and collaborate on attention-grabbing tasks.
[ad_2]
Source link
