


[ad_1]
Current developments in text-to-image fashions have led to classy methods able to producing high-quality photographs primarily based on temporary scene descriptions. Nonetheless, these fashions encounter difficulties when confronted with intricate captions, typically ensuing within the omission or mixing of visible attributes tied to completely different objects. The time period “dense” on this context is rooted within the idea of dense captioning, the place particular person phrases are utilized to explain particular areas inside a picture. Moreover, customers face challenges in exactly dictating the association of parts throughout the generated photographs utilizing solely textual prompts.
A number of current research have proposed options that empower customers with spatial management by coaching or refining text-to-image fashions conditioned on layouts. Whereas particular approaches like “Make-aScene” and “Latent Diffusion Fashions” assemble fashions from the bottom up with each textual content and structure circumstances, different concurrent strategies like “SpaText” and “ControlNet” introduce supplementary spatial controls to present text-to-image fashions by way of fine-tuning. Sadly, coaching or fine-tuning a mannequin could be computationally intensive. Furthermore, the mannequin necessitates retraining for each novel consumer situation, area, or base text-to-image mannequin.
Based mostly on the abovementioned points, a novel training-free method termed DenseDiffusion is proposed to accommodate dense captions and supply structure manipulation.
Earlier than presenting the primary thought, let me briefly recap how diffusion fashions work. Diffusion fashions generate photographs by way of sequential denoising steps, ranging from random noise. Noise prediction networks estimate noise added and attempt to render a sharper picture at every step. Current fashions cut back the variety of denoising steps for quicker outcomes with out considerably compromising the generated picture.
Two important blocks in state-of-the-art diffusion fashions are the self-attention and cross-attention layers.
Inside a self-attention layer, intermediate options moreover operate as contextual options. This allows the creation of worldwide constant constructions by establishing connections amongst picture tokens spanning numerous areas. Concurrently, a cross-attention layer adapts primarily based on textual options obtained from the enter textual content caption, using a CLIP textual content encoder for encoding.
Rewinding, the primary thought behind DenseDiffusion is the revised consideration modulation course of, which is introduced within the determine beneath.
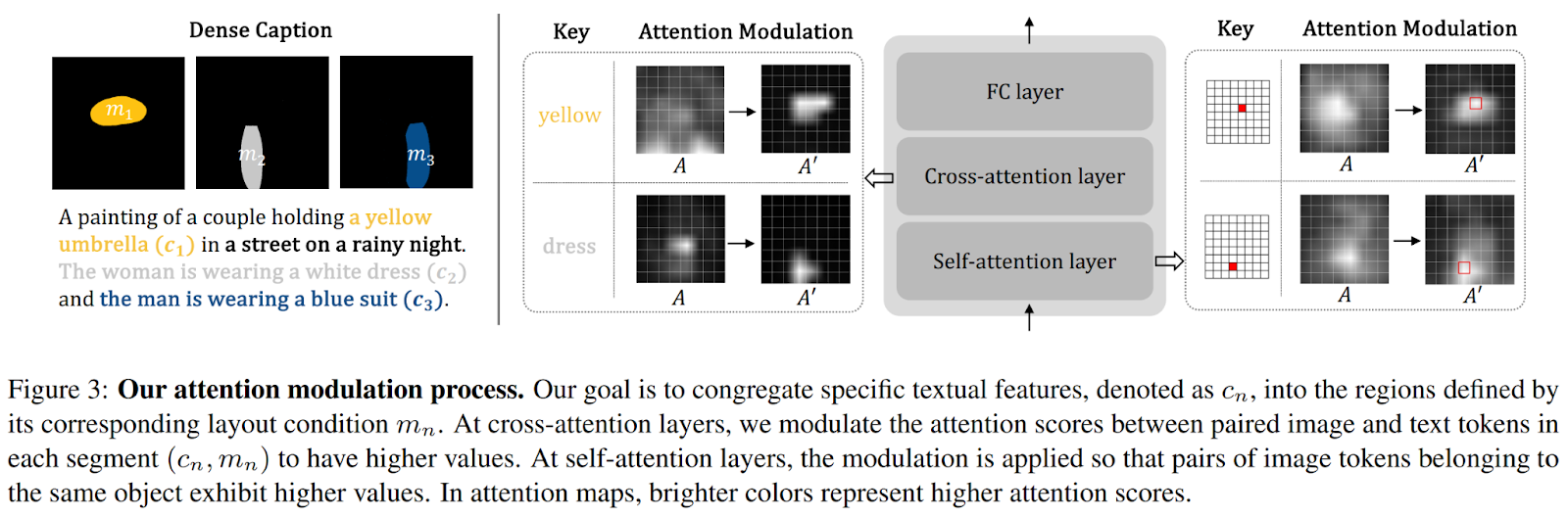
Initially, the middleman options of a pre-trained text-to-image diffusion mannequin are scrutinized to disclose the substantial correlation between the generated picture’s structure and self-attention and cross-attention maps. Drawing from this perception, intermediate consideration maps are dynamically adjusted primarily based on the structure circumstances. Moreover, the strategy entails contemplating the unique consideration rating vary and fine-tuning the modulation extent primarily based on every phase’s space. Within the introduced work, the authors exhibit the potential of DenseDiffusion to boost the efficiency of the “Secure Diffusion” mannequin and surpass a number of compositional diffusion fashions when it comes to dense captions, textual content and structure circumstances, and picture high quality.
Pattern consequence outcomes chosen from the research are depicted within the picture beneath. These visuals present a comparative overview between DenseDiffusion and state-of-the-art approaches.

This was the abstract of DenseDiffusion, a novel AI training-free method to accommodate dense captions and supply structure manipulation in text-to-image synthesis.
Try the Paper and Github. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t neglect to hitch our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
Daniele Lorenzi obtained his M.Sc. in ICT for Web and Multimedia Engineering in 2021 from the College of Padua, Italy. He’s a Ph.D. candidate on the Institute of Data Know-how (ITEC) on the Alpen-Adria-Universität (AAU) Klagenfurt. He’s at the moment working within the Christian Doppler Laboratory ATHENA and his analysis pursuits embody adaptive video streaming, immersive media, machine studying, and QoS/QoE analysis.
[ad_2]
Source link
