

[ad_1]
Massive language fashions (LLMs) have just lately proven spectacular efficiency on varied duties. Generative LLM inference has never-before-seen powers, but it surely additionally faces explicit difficulties. These fashions can embody billions or trillions of parameters, which means that operating them requires great reminiscence and computing energy. GPT-175B, as an illustration, solely wants 325GB of GPU RAM to load its mannequin weights. It could take at the very least 5 A100 (80GB) GPUs and complicated parallelism strategies to suit this mannequin onto GPUs. Therefore, decreasing the assets wanted for LLM inference has just lately generated lots of curiosity.
LLMs are used for varied “back-of-house” operations, together with benchmarking, data extraction, information wrangling, kind processing, and interactive use instances like chatbots. On this examine, they consider a scenario that they consult with as throughput-oriented generative inference. The truth that these duties incessantly name for conducting LLM inference in batches throughout a lot of tokens resembling all of the papers in an organization’s corpus and are much less vulnerable to the delay of token era is a big characteristic of those jobs. Due to this, there are potentialities to decrease useful resource wants in sure workloads by buying and selling off latency for higher throughput.
Three approaches have been used to cut back the assets wanted for LLM inference: mannequin compression to cut back the general reminiscence footprint, collaborative inference to unfold out the price of inference by means of decentralization, and offloading to make higher use of reminiscence on the CPU and disc. Though clear limits exist, these methods have significantly decreased the useful resource wants for using LLMs. Analysis within the first two strategies typically wants assist to run 175B-scale fashions on a single commodity GPU as a result of it assumes that the mannequin matches throughout the GPU reminiscence. Alternatively, on account of ineffective I/O scheduling and tensor placement, cutting-edge offloading-based methods within the third class can not attain an appropriate throughput on a single GPU.
With a single commodity GPU, their principal aim is to construct efficient offloading mechanisms for high-throughput generative inference. They’ll partially load an LLM and execute computation piecemeal by offloading it to secondary storage to function an LLM with constrained GPU reminiscence. The reminiscence hierarchy is split into three tiers in a typical system. Decrease ranges are slower however extra plentiful, whereas greater ranges are faster however extra scarce. Small batch sizes could trigger bottlenecks in these methods. They might compromise latency in throughput-oriented eventualities by utilizing a excessive batch dimension and distributing the costly I/O operations over a number of reminiscence hierarchies all through a big batch of inputs overlapped with processing.
Even when they’ll compromise the delay, reaching high-throughput generative inference with constrained GPU reminiscence is troublesome. The primary issue is developing with a profitable unloading plan. The plan ought to define which tensors needs to be offloaded, the place they need to be offloaded within the three-level reminiscence construction, and when throughout inference. Three varieties of tensors are utilized in generative inference: weights, activations, and key-value (KV) caching.
There are a number of methods to calculate due to the algorithm’s batch-by-batch, token-by-token, and layer-by-layer construction. These choices come collectively to create a sophisticated design house. Offloading-based inference methods now in use inherit training-based methodologies that conduct extreme I/O and obtain throughput far beneath theoretical {hardware} constraints, making them some poor areas for inference. The creation of environment friendly compression algorithms presents the second downside. LLMs’ weights and activations have proven promising compression ends in earlier publications. However, when compression and offloading are coupled for high-throughput generative inference, extra compression methods are pushed by the I/O prices and reminiscence discount of the weights and KV cache.
Researchers from UCB, Stanford, CMU, Meta, Yandex, ETH and HSE collectively introduce FlexGen, an offloading framework for high-throughput LLM inference, to beat these issues. FlexGen successfully schedules I/O actions, potential compression strategies, and distributed pipeline parallelism by combining reminiscence from the GPU, CPU, and disc. These are the contributions they made:
- They explicitly describe a search house of potential offloading choices by contemplating the computing schedule, tensor placement, and computation delegation. They reveal that their search house captures a computing order with I/O complexity inside 2 of optimality. Subsequent, they create a search algorithm based mostly on linear programming to maximise throughput throughout the search house.
- They present that, with out retraining or calibration, it’s potential to lower the weights and KV cache for LLMs just like the OPT-175B to 4 bits with little to no accuracy loss. Effective-grained group-wise quantization, suited to decreasing I/O prices and reminiscence use throughout offloading, achieves this.
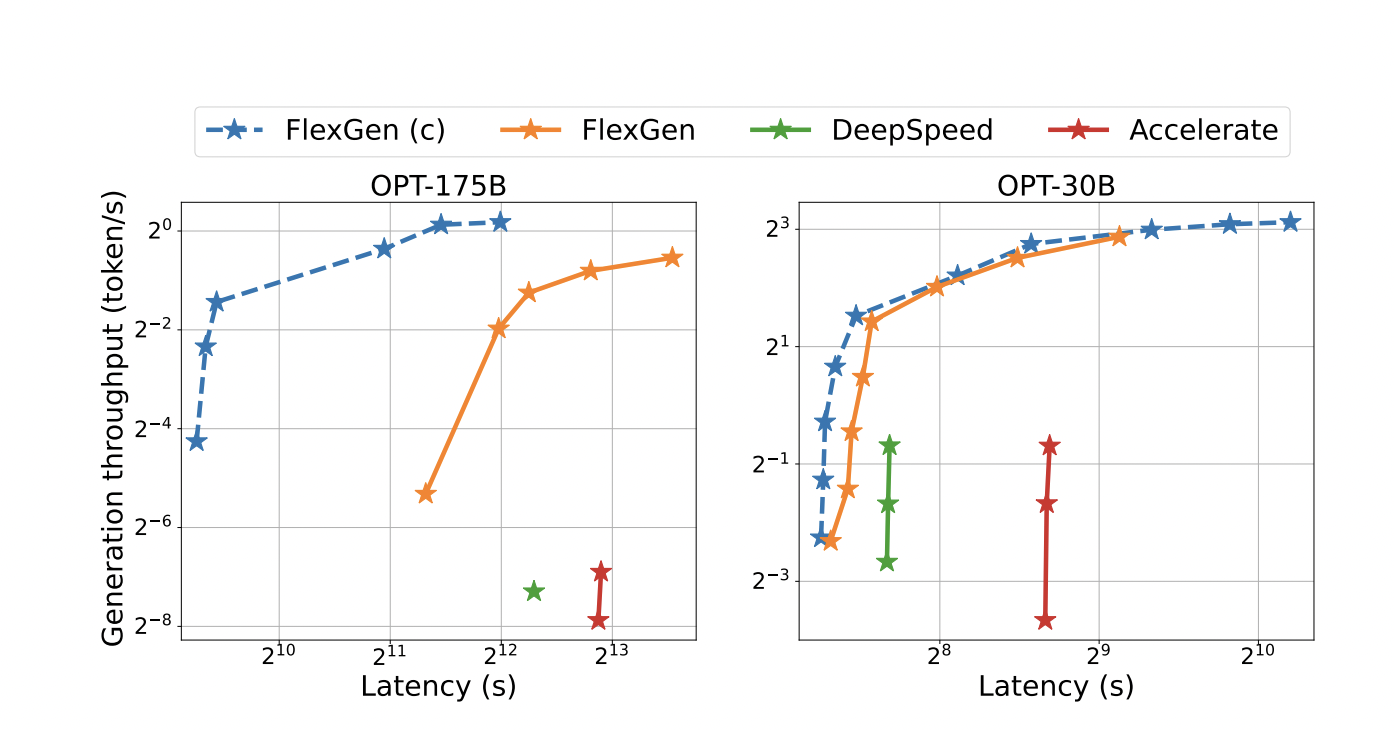
- They reveal the effectivity of FlexGen by operating OPT-175B on NVIDIA T4 (16GB) GPUs. FlexGen typically permits a much bigger batch dimension than the 2 cutting-edge offloading-based inference algorithms, DeepSpeed Zero-Inference and Hugging Face Speed up. FlexGen can accomplish considerably larger throughputs because of this.
Take a look at the Paper and Github. All Credit score For This Analysis Goes To the Researchers on This Undertaking. Additionally, don’t overlook to hitch our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
Aneesh Tickoo is a consulting intern at MarktechPost. He’s presently pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on initiatives aimed toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is enthusiastic about constructing options round it. He loves to attach with individuals and collaborate on attention-grabbing initiatives.
[ad_2]
Source link
