


[ad_1]

Picture from Adobe Firefly
I not too long ago began an AI-focused instructional publication, that already has over 160,000 subscribers. TheSequence is a no-BS (which means no hype, no information, and many others) ML-oriented publication that takes 5 minutes to learn. The objective is to maintain you updated with machine studying tasks, analysis papers, and ideas. Please give it a strive by subscribing beneath:
Latest developments in giant language fashions (LLMs) have revolutionized the sector, equipping them with new capabilities like pure dialogue, mathematical reasoning, and program synthesis. Nevertheless, LLMs nonetheless face inherent limitations. Their potential to retailer data is constrained by mounted weights, and their computation capabilities are restricted to a static graph and slender context. Moreover, because the world evolves, LLMs want retraining to replace their data and reasoning skills. To beat these limitations, researchers have began empowering LLMs with instruments. By granting entry to intensive and dynamic data bases and enabling complicated computational duties, LLMs can leverage search applied sciences, databases, and computational instruments. Main LLM suppliers have begun integrating plugins that permit LLMs to invoke exterior instruments by way of APIs. This transition from a restricted set of hand-coded instruments to accessing an unlimited array of cloud APIs has the potential to rework LLMs into the first interface for computing infrastructure and the online. Duties akin to reserving holidays or internet hosting conferences might be so simple as conversing with an LLM that has entry to flight, automobile rental, lodge, catering, and leisure net APIs.
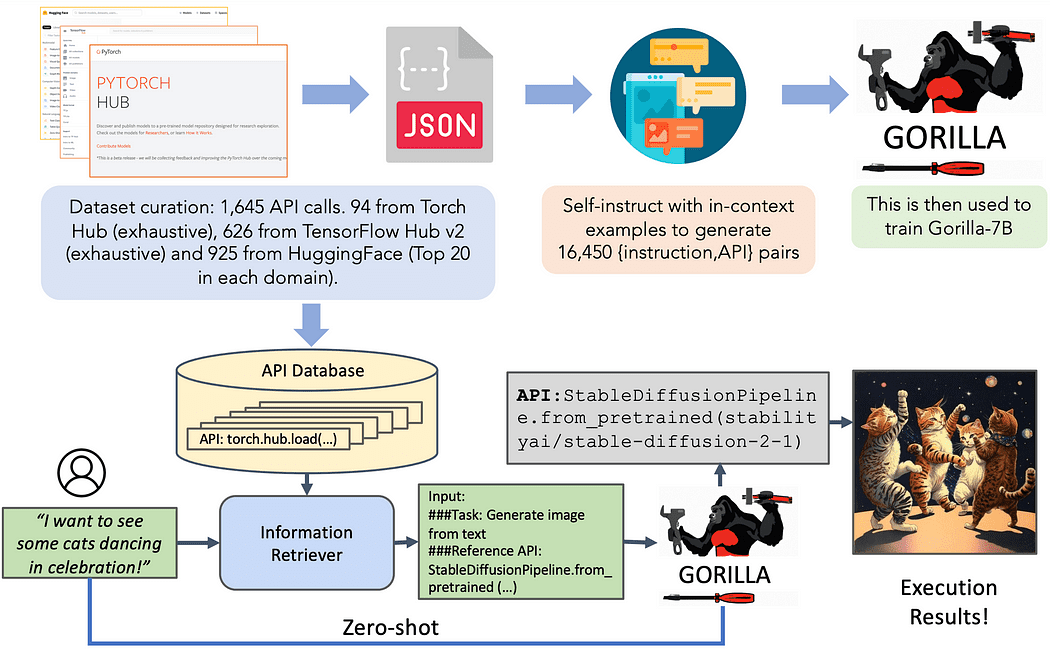
Just lately, researchers from UC Berkeley and Microsoft unveiled Gorilla, a LLaMA-7B mannequin designed particularly for API calls. Gorilla depends on self-instruct fine-tuning and retrieval methods to allow LLMs to pick precisely from a big and evolving set of instruments expressed by way of their APIs and documentation. The authors assemble a big corpus of APIs, known as APIBench, by scraping machine studying APIs from main mannequin hubs akin to TorchHub, TensorHub, and HuggingFace. Utilizing self-instruct, they generate pairs of directions and corresponding APIs. The fine-tuning course of includes changing the info to a user-agent chat-style dialog format and performing normal instruction finetuning on the bottom LLaMA-7B mannequin.

Picture Credit score: UC Berkeley
API calls typically include constraints, including complexity to the LLM’s comprehension and categorization of the calls. For instance, a immediate could require invoking a picture classification mannequin with particular parameter measurement and accuracy constraints. These challenges spotlight the necessity for LLMs to know not solely the practical description of an API name but additionally purpose in regards to the embedded constraints.
The tech-focused dataset at hand encompasses three distinct domains: Torch Hub, Tensor Hub, and HuggingFace. Every area contributes a wealth of knowledge, shedding gentle on the various nature of the dataset. Torch Hub, as an illustration, provides 95 APIs, offering a stable basis. Compared, Tensor Hub takes it a step additional with an in depth assortment of 696 APIs. Lastly, HuggingFace leads the pack with a whopping 925 APIs, making it essentially the most complete area.
To amplify the worth and value of the dataset, a further endeavor has been undertaken. Every API within the dataset is accompanied by a set of 10 meticulously crafted and uniquely tailor-made directions. These directions function indispensable guides for each coaching and analysis functions. This initiative ensures that each API goes past mere illustration, enabling extra strong utilization and evaluation.
Gorilla introduces the notion of retriever-aware coaching, the place the instruction-tuned dataset contains a further area with retrieved API documentation for reference. This method goals to show the LLM to parse and reply questions based mostly on the offered documentation. The authors exhibit that this system permits the LLM to adapt to adjustments in API documentation, improves efficiency, and reduces hallucination errors.
Throughout inference, customers present prompts in pure language. Gorilla can function in two modes: zero-shot and retrieval. In zero-shot mode, the immediate is immediately fed to the Gorilla LLM mannequin, which returns the beneficial API name to perform the duty or objective. In retrieval mode, the retriever (both BM25 or GPT-Index) retrieves essentially the most up-to-date API documentation from the API Database. This documentation is concatenated with the person immediate, together with a message indicating the reference to the API documentation. The concatenated enter is then handed to Gorilla, which outputs the API to be invoked. Immediate tuning will not be carried out past the concatenation step on this system.
Picture Credit score: UC Berkeley
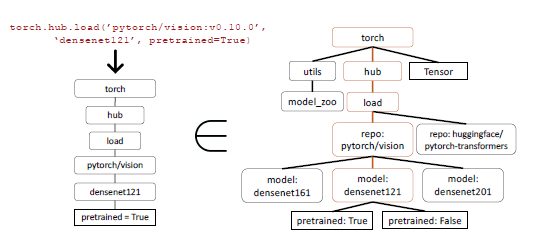
Inductive program synthesis has achieved success in numerous domains by synthesizing packages that meet particular take a look at instances. Nevertheless, in relation to evaluating API calls, relying solely on take a look at instances falls quick because it turns into difficult to confirm the semantic correctness of the code. Let’s contemplate the instance of picture classification, the place there are greater than 40 totally different fashions out there for the duty. Even when we slender it right down to a particular household, akin to Densenet, there are 4 potential configurations. Consequently, a number of right solutions exist, making it troublesome to find out if the API getting used is functionally equal to the reference API by way of unit checks. To judge the efficiency of the mannequin, a comparability of their practical equivalence is made utilizing the collected dataset. To establish the API known as by the LLM within the dataset, an AST (Summary Syntax Tree) tree-matching technique is employed. By checking if the AST of a candidate API name is a sub-tree of the reference API name, it turns into potential to hint which API is being utilized.
Figuring out and defining hallucinations poses a big problem. The AST matching course of is leveraged to establish hallucinations immediately. On this context, a hallucination refers to an API name that’s not a sub-tree of any API within the database, basically invoking a completely imagined device. It’s vital to notice that this definition of hallucination differs from invoking an API incorrectly, which is outlined as an error.
AST sub-tree matching performs a vital position in figuring out the particular API being known as inside the dataset. Since API calls can have a number of arguments, every of those arguments must be matched. Moreover, contemplating that Python permits for default arguments, it’s important to outline which arguments to match for every API within the database.
Picture Credit score: UC Berkeley
Along with the paper, the researchers open sourced a version of Gorilla. The discharge features a pocket book with many examples. Moreover, the next video clearly reveals among the magic of Gorillas.
Gorilla is among the most attention-grabbing approaches within the tool-augmented LLM area. Hopefully, we’ll see the mannequin distributed in among the major ML hubs within the area.
Jesus Rodriguez is at present a CTO at Intotheblock. He’s a expertise professional, govt investor and startup advisor. Jesus based Tellago, an award profitable software program improvement agency targeted serving to firms change into nice software program organizations by leveraging new enterprise software program traits.
Original. Reposted with permission.
[ad_2]
Source link
