

[ad_1]
Giant-scale corpora and cutting-edge {hardware} allow LLMs to generate fashions with extraordinary understanding and generative energy, elevating the bar for language issues. Current developments in instruction-following fashions, corresponding to ChatGPT1 and GPT-3.5, have achieved super progress (text-davinci-003). They could produce skilled and conversational responses when given instructions or directions in regular language. Nonetheless, the closed-source limitation and costly growth prices considerably impede the unfold of instruction-following fashions.
Stanford Alpaca researchers steered modifying an LLM, or LLaMA, into an accessible and scalable instruction-following mannequin. Alpaca makes use of GPT-3.5 to self-instruct and enhance the coaching knowledge to 52K from 175 human-written instruction-output pairs. This controls Alpaca to optimize all 7B parameters in LLaMA, leading to an excellent mannequin that performs equally to GPT-3.5. Regardless of Alpaca’s effectivity, large-scale LLaMA nonetheless requires intensive fine-tuning. That is time-consuming, computationally demanding, multi-modality incompatible, and tough to adapt to different downstream eventualities.
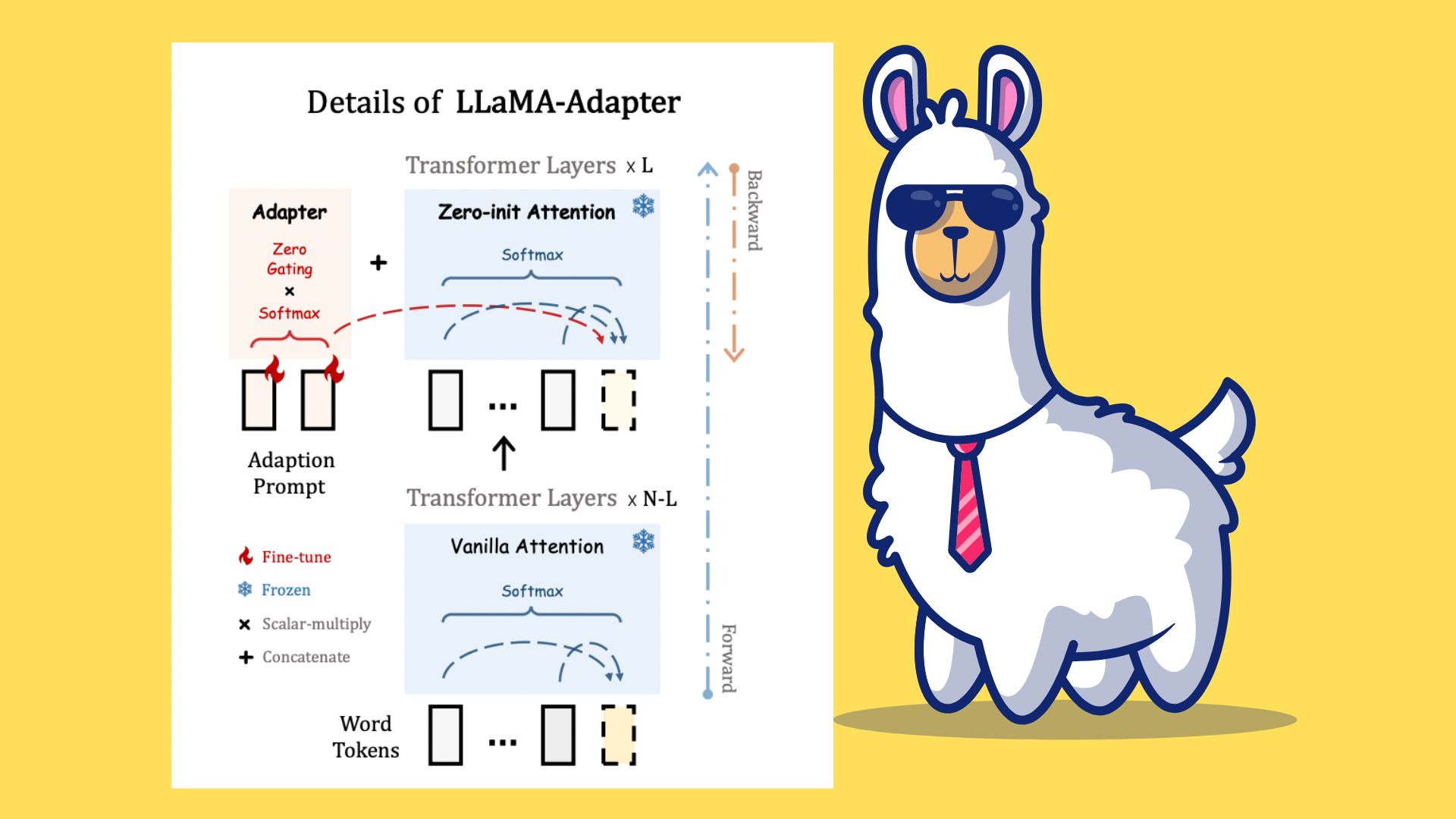
A gaggle of researchers from the Shanghai Synthetic Intelligence Laboratory, CUHK MMLab, and the College of California launched the LLaMA-Adapter. This efficient fine-tuning approach transforms LLaMA right into a succesful instruction-following mannequin. Within the increased transformer layers of LLaMA, the researchers prefix the enter instruction tokens with a set of learnable adaptation prompts. These directions are adaptively injected into LLaMA by these prompts.
The staff modified the default consideration mechanisms at inserted layers to zero-init consideration with a trainable gating issue to remove noise from adaptation cues in the course of the early coaching interval. Initialized with zero vectors, the gating can preserve preliminary information in LLaMA and step by step add coaching indicators. This helps the ultimate mannequin higher observe directions and preserve studying stability as it’s fine-tuned.
General, LLaMA-Adapter reveals the next 4 traits:
- 1.2 million parameters: The pre-trained LLaMA is frozen and solely learns the adaption prompts with 1.2M parameters on high as an alternative of updating your complete set of 7B parameters. This, nonetheless, demonstrates comparable instruction after mastery of the 7B Alpaca.
- Wonderful-tuning for an hour. With eight A100 GPUs, the convergence of the LLaMA-Adapter takes lower than an hour, which is thrice faster than Alpaca, due to the light-weight parameters and the zero-init gating.
- Plug with Data. It’s adaptable to put in its acceptable adapters and offers LLaMA numerous skilled information for varied circumstances. Therefore saving a 1.2M adapter inside every context is adequate.
- Multimodal State: LLaMA-Adapter could be expanded to simply accept picture enter and textual instruction for multimodal reasoning. LLaMA-Adapter achieves aggressive efficiency on the ScienceQA benchmark by together with picture tokens in adaptation prompts.
The staff plans to include extra assorted multimodal inputs, corresponding to audio and video, into LLaMA-Adapter. They are going to conduct extra analysis on bigger LLaMA fashions (33B, 65B parameters) and varied benchmarks.
Try the Paper and Github. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t overlook to affix our 17k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
Tanushree Shenwai is a consulting intern at MarktechPost. She is at the moment pursuing her B.Tech from the Indian Institute of Expertise(IIT), Bhubaneswar. She is a Information Science fanatic and has a eager curiosity within the scope of software of synthetic intelligence in varied fields. She is obsessed with exploring the brand new developments in applied sciences and their real-life software.
[ad_2]
Source link
