

[ad_1]
Lately, methods specializing in studying content material options—particularly, options holding the knowledge that lets us determine and discriminate objects—have dominated self-supervised studying in imaginative and prescient. Most methods think about figuring out broad traits that carry out nicely in duties like merchandise categorization or exercise detection in movies. Studying localized options that excel at regional duties like segmentation and detection is a comparatively latest idea. Nevertheless, these methods think about comprehending the content material of images and movies slightly than with the ability to be taught traits about pixels, akin to movement in movies or textures.
On this analysis, authors from Meta AI, PSL Analysis College, and New York College think about concurrently studying content material traits with generic self-supervised studying and movement options using self-supervised optical circulate estimates from motion pictures as a pretext drawback. When two photos—for instance, successive frames in a film or pictures from a stereo pair—transfer or have a dense pixel connection, it’s captured by optical circulate. In laptop imaginative and prescient, estimating is a primary drawback whose decision is crucial to operations like visible odometry, depth estimation, or object monitoring. In accordance with conventional strategies, estimating optical circulate is an optimization challenge that goals to match pixels with a smoothness requirement.
The problem of categorizing real-world information as a substitute of artificial information limits approaches primarily based on neural networks and supervised studying. Self-supervised methods now compete with supervised methods by permitting studying from substantial quantities of real-world video information. The vast majority of present approaches, nevertheless, solely take note of movement slightly than the (semantic) content material of the video. This challenge is resolved by concurrently studying movement and content material components in photos utilizing a multi-task method. Latest strategies determine spatial relationships between video frames. The target is to comply with the motion of objects to gather content material information that optical circulate estimates can not.
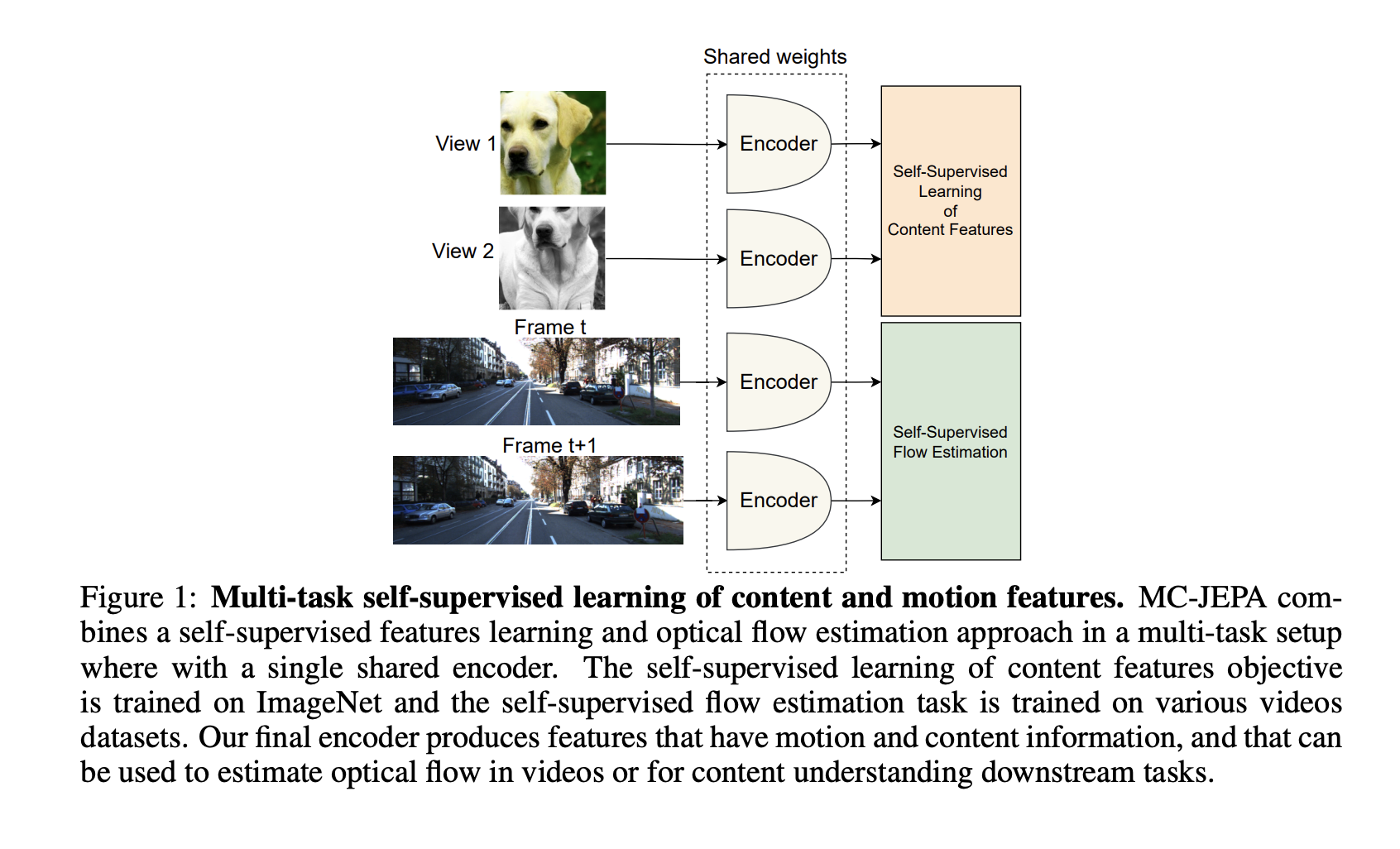
These strategies are object-level movement estimation strategies. With comparatively weak generalization to different visible downstream duties, they purchase extremely specialised traits for the monitoring job. The low high quality of the visible traits realized is bolstered by the truth that they’re often educated on tiny video datasets that want extra range than bigger image datasets like ImageNet. Studying a number of actions concurrently is a extra dependable approach for creating visible representations. To unravel this drawback, they provide MC-JEPA (Movement-Content material Joint-Embedding Predictive Structure). Utilizing a typical encoder, this joint-embedding-predictive architecture-based system learns optical circulate estimates and content material traits in a multi-task atmosphere.
The next is a abstract of their contributions:
• They provide a way primarily based on PWC-Web that’s augmented with quite a few further components, akin to a backward consistency loss and a variance-covariance regularisation time period, for studying self-supervised optical circulate from artificial and actual video information.
• They use M-JEPA with VICReg, a self-supervised studying approach educated on ImageNet, in a multi-task configuration to optimize their estimated circulate and supply content material traits that switch nicely to a number of downstream duties. The title of their final method is MC-JEPA.
• They examined MC-JEPA on quite a lot of optical circulate benchmarks, together with KITTI 2015 and Sintel, in addition to picture and video segmentation duties on Cityscapes or DAVIS, they usually discovered {that a} single encoder carried out nicely on every of those duties. They anticipate that MC-JEPA can be a precursor to self-supervised studying methodologies primarily based on joint embedding and multi-task studying that may be educated on any visible information, together with pictures and movies, and carry out nicely throughout varied duties, from movement prediction to content material understanding.
Take a look at the Paper. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t neglect to affix our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at present pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is obsessed with constructing options round it. He loves to attach with folks and collaborate on attention-grabbing initiatives.
[ad_2]
Source link
