


[ad_1]
Generative fashions have gotten the de-facto answer for a lot of difficult duties in pc science. They characterize one of the crucial promising methods to research and synthesize visible information. Secure Diffusion is the best-known generative mannequin for producing lovely and practical photos from a fancy enter immediate. The structure relies on Diffusion Fashions (DMs), which have proven phenomenal generative energy for photos and movies. The fast developments in diffusion and generative modeling are fueling a revolution in 2D content material creation. The mantra is kind of easy: “In case you can describe it, you’ll be able to visualize it.” or higher, “if you happen to can describe it, the mannequin can paint it for you.” It’s certainly unbelievable what generative fashions are able to.
Whereas 2D content material was proven to be a stress check for DMs, 3D content material poses a number of challenges attributable to however not restricted to the extra dimension. Producing 3D content material, corresponding to avatars, with the identical high quality as 2D content material is a tough job given the reminiscence and processing prices, which will be prohibitive for producing the wealthy particulars required for high-quality avatars.
With know-how pushing using digital avatars in motion pictures, video games, metaverse, and the 3D business, permitting anybody to create a digital avatar will be helpful. That’s the motivation driving the event of this work.
The authors suggest the Roll-out diffusion community (Rodin) to handle the difficulty of making a digital avatar. An outline of the mannequin is given within the determine beneath.
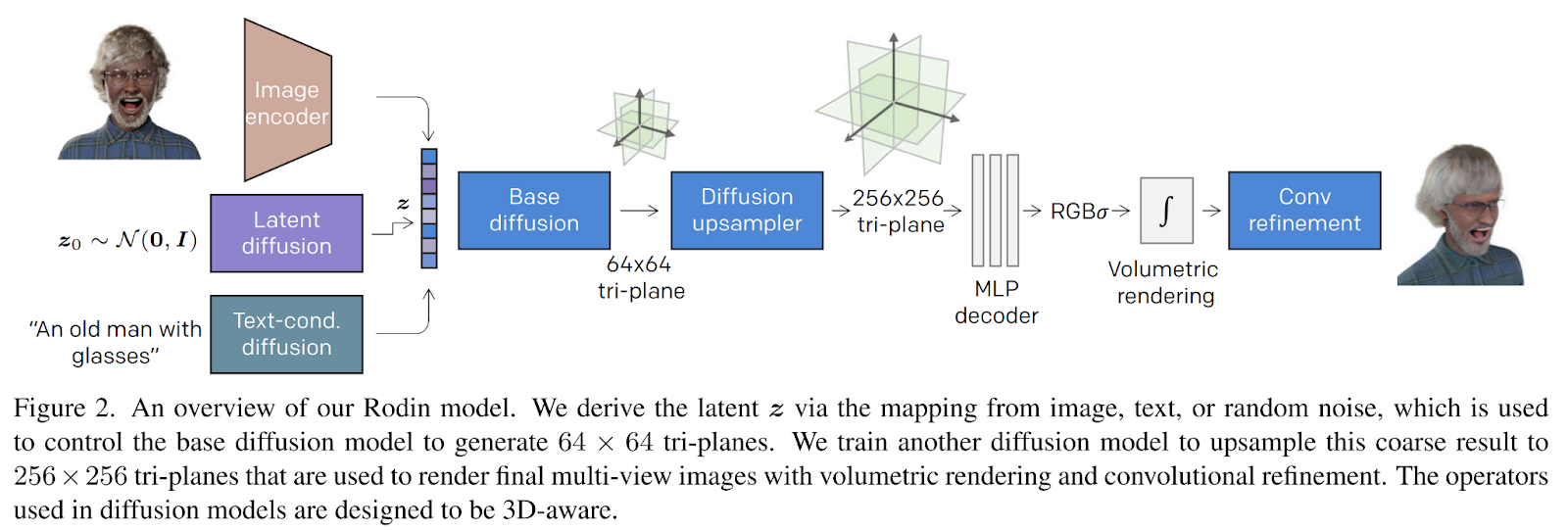
The enter to the mannequin will be a picture, random noise, or a textual content description of the specified avatar. The latent vector z is subsequently derived from the given enter and employed within the diffusion. The diffusion course of consists of a number of noise-denoise steps. Firstly random noise is added to the beginning state or picture and denoised to acquire a a lot sharper picture.
The distinction right here lies within the 3D nature of the specified content material. The diffusion course of runs as traditional, however as a substitute of focusing on a 2D picture, the diffusion mannequin generates the coarse geometry of the avatar, adopted by a diffusion upsampler for element synthesis.
Computational and reminiscence effectivity is without doubt one of the targets of this work. To realize this, the authors exploited the tri-plane (three axes) illustration of a neural radiance subject, which, in comparison with voxel grids, provides a significantly smaller reminiscence footprint with out sacrificing the expressivity.
One other diffusion mannequin is then educated to upsample the produced tri-plane illustration to match the specified decision. Lastly, a light-weight MLP decoder consisting of 4 absolutely related layers is exploited to generate an RGB volumetric picture.
Some outcomes are reported beneath.

In contrast with the talked about state-of-the-art approaches, Rodin offers the sharpest digital avatars. For the mannequin, no artifacts are seen within the shared samples, opposite to the opposite methods.
This was the abstract of Rodin, a novel framework to simply generate 3D digital avatars from varied enter sources. In case you are , you could find extra info within the hyperlinks beneath.
Take a look at the Paper. All Credit score For This Analysis Goes To Researchers on This Mission. Additionally, don’t neglect to hitch our Reddit page and discord channel, the place we share the newest AI analysis information, cool AI initiatives, and extra.
Daniele Lorenzi obtained his M.Sc. in ICT for Web and Multimedia Engineering in 2021 from the College of Padua, Italy. He’s a Ph.D. candidate on the Institute of Info Expertise (ITEC) on the Alpen-Adria-Universität (AAU) Klagenfurt. He’s presently working within the Christian Doppler Laboratory ATHENA and his analysis pursuits embrace adaptive video streaming, immersive media, machine studying, and QoS/QoE analysis.
[ad_2]
Source link
