


[ad_1]
In recent times, there was a speedy improvement in text-based visible content material era. Educated with large-scale image-text pairs, present Textual content-to-Picture (T2I) diffusion fashions have demonstrated a formidable capacity to generate high-quality photos primarily based on user-provided textual content prompts. Success in picture era has additionally been prolonged to video era. Some strategies leverage T2I fashions to generate movies in a one-shot or zero-shot method, whereas movies generated from these fashions are nonetheless inconsistent or lack selection. Scaling up video knowledge, Textual content-to-Video (T2V) diffusion fashions can create constant movies with textual content prompts. Nonetheless, these fashions generate movies missing management over the generated content material.
A latest research proposes a T2V diffusion mannequin that enables for depth maps as management. Nonetheless, a large-scale dataset is required to realize consistency and prime quality, which is resource-unfriendly. Moreover, it’s nonetheless difficult for T2V diffusion fashions to generate movies of consistency, arbitrary size, and variety.
Video-ControlNet, a controllable T2V mannequin, has been launched to handle these points. Video-ControlNet gives the next benefits: improved consistency via using movement priors and management maps, the flexibility to generate movies of arbitrary size by using a first-frame conditioning technique, area generalization by transferring information from photos to movies, and useful resource effectivity with quicker convergence utilizing a restricted batch dimension.
Video-ControlNet’s structure is reported beneath.
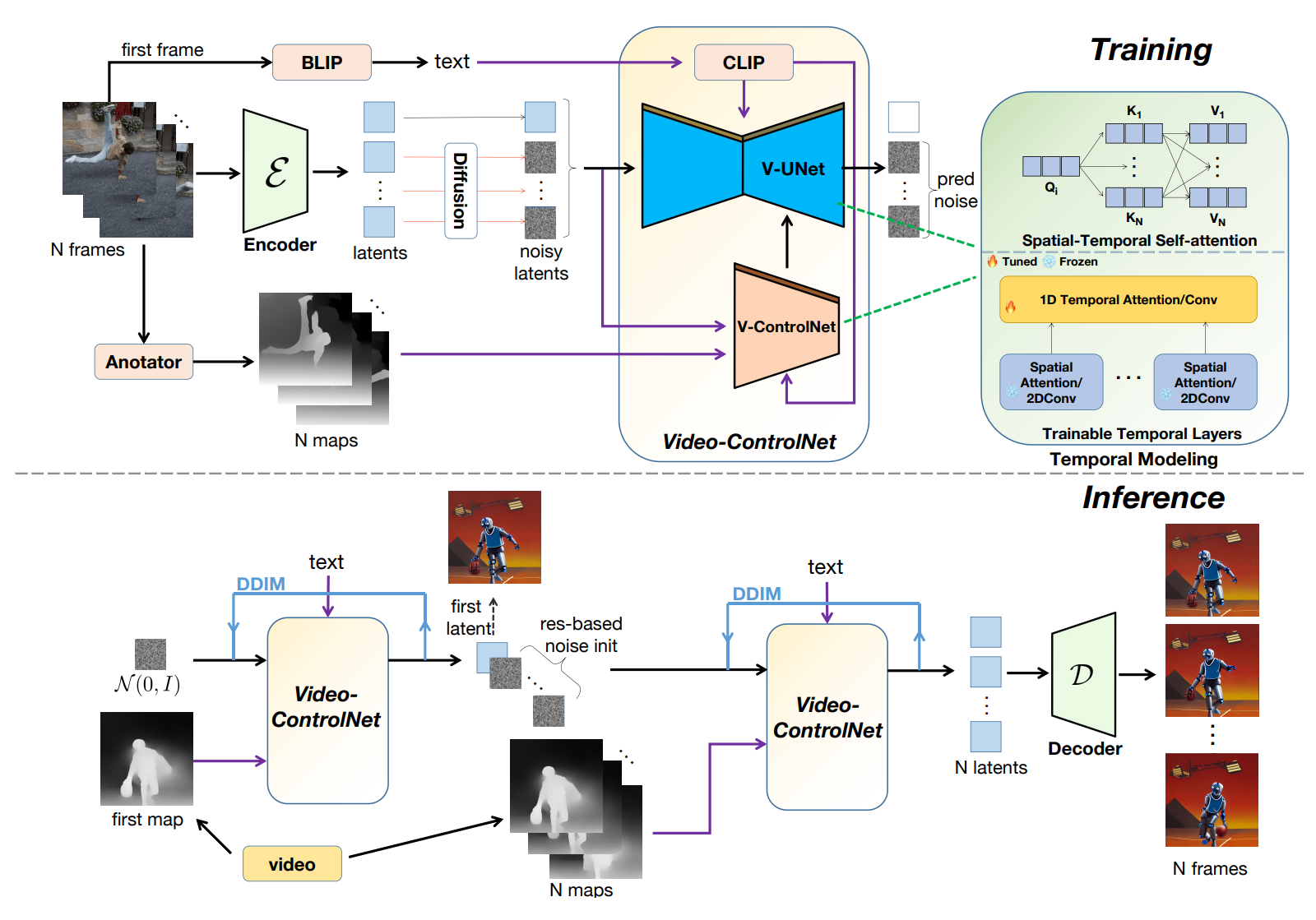

The aim is to generate movies primarily based on textual content and reference management maps. Due to this fact, the generative mannequin is developed by reorganizing a pre-trained controllable T2I mannequin, incorporating extra trainable temporal layers, and presenting a spatial-temporal self-attention mechanism that facilitates fine-grained interactions between frames. This method permits for the creation of content-consistent movies, even with out intensive coaching.
To make sure video construction consistency, the authors suggest a pioneering method that includes the movement prior of the supply video into the denoising course of on the noise initialization stage. By leveraging movement prior and management maps, Video-ControlNet is ready to produce movies which are much less flickering and intently resemble movement adjustments within the enter video whereas additionally avoiding error propagation in different motion-based strategies as a result of nature of the multi-step denoising course of.
Moreover, as a substitute of earlier strategies that prepare fashions to instantly generate total movies, an progressive coaching scheme is launched on this work, which produces movies predicated on the preliminary body. With such a simple but efficient technique, it turns into extra manageable to disentangle content material and temporal studying, as the previous is introduced within the first body and the textual content immediate.
The mannequin solely must discover ways to generate subsequent frames, inheriting generative capabilities from the picture area and easing the demand for video knowledge. Throughout inference, the primary body is generated conditioned on the management map of the primary body and a textual content immediate. Then, subsequent frames are generated, conditioned on the primary body, textual content, and subsequent management maps. In the meantime, one other advantage of such a technique is that the mannequin can auto-regressively generate an infinity-long video by treating the final body of the earlier iteration because the preliminary body.
That is the way it works. Allow us to check out the outcomes reported by the authors. A restricted batch of pattern outcomes and comparability with state-of-the-art approaches is proven within the determine beneath.

This was the abstract of Video-ControlNet, a novel diffusion mannequin for T2V era with state-of-the-art high quality and temporal consistency. In case you are , you possibly can be taught extra about this system within the hyperlinks beneath.
Examine Out The Paper. Don’t neglect to hitch our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra. When you’ve got any questions relating to the above article or if we missed something, be happy to e mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Daniele Lorenzi obtained his M.Sc. in ICT for Web and Multimedia Engineering in 2021 from the College of Padua, Italy. He’s a Ph.D. candidate on the Institute of Data Expertise (ITEC) on the Alpen-Adria-Universität (AAU) Klagenfurt. He’s presently working within the Christian Doppler Laboratory ATHENA and his analysis pursuits embrace adaptive video streaming, immersive media, machine studying, and QoS/QoE analysis.
[ad_2]
Source link
