

[ad_1]
Lately, synthetic intelligence (AI) fashions have proven exceptional enchancment. The open-source motion has made it easy for programmers to mix totally different open-source fashions to create novel purposes.
Steady diffusion permits for the automated technology of photorealistic and different kinds of photographs from textual content enter. Since these fashions are usually massive and computationally intensive, all computations required ta are forwarded to (GPU) servers when constructing net purposes that make the most of them. On high of that, most workloads want a particular GPU household on which standard deep-learning frameworks will be run.
The Machine Studying Compilation (MLC) group presents a challenge as an effort to change the present scenario and enhance biodiversity within the surroundings. They believed quite a few advantages could possibly be realized by shifting computation to the consumer, corresponding to decrease service supplier prices and better-individualized experiences and safety.
In accordance with the group, the ML fashions ought to have the ability to transport to a location with out the mandatory GPU-accelerated Python frameworks. AI frameworks usually rely closely on {hardware} distributors’ optimized computed libraries. Subsequently backup is necessary to start out over. To maximise returns, distinctive variants have to be generated primarily based on the specifics of every consumer’s infrastructure.
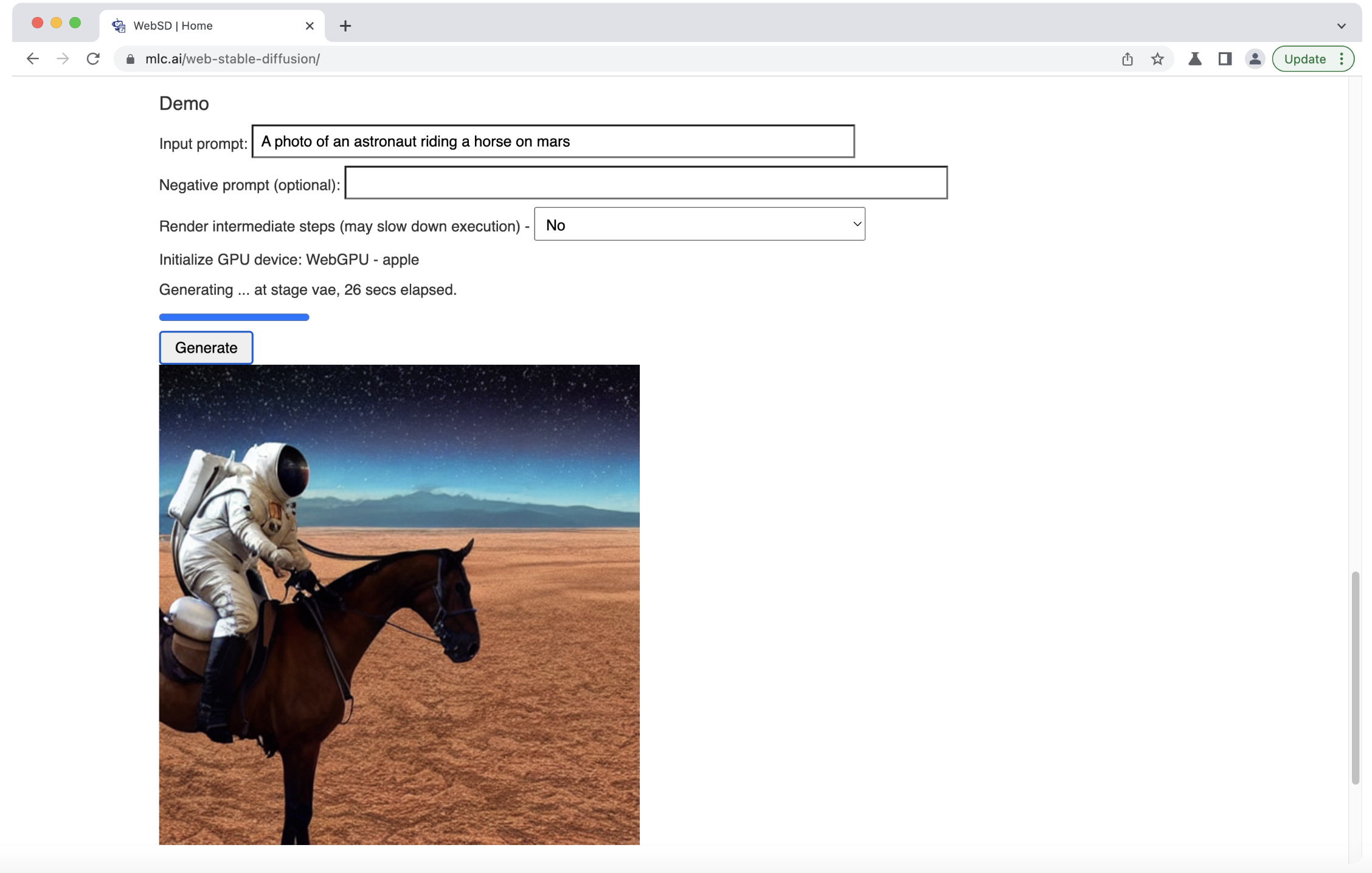
The proposed net secure diffusion immediately places the common diffusion mannequin within the browser and runs immediately by means of the consumer GPU on the consumer’s laptop computer. Every little thing is dealt with regionally throughout the browser and by no means touches a server. In accordance with the group, that is the primary browser-based secure diffusion on this planet.
Right here, machine studying compilation know-how performs a central position (MLC). PyTorch, Hugging Face diffusers and tokenizers, rust, wasm, and WebGPU are a few of the open-source applied sciences upon which the proposed resolution rests. Apache TVM Unity, an enchanting work-in-progress inside Apache TVM, is the muse on which the primary stream is constructed.
The group has used the Hugging Face diffuser library’s Runway secure diffusion v1-5 fashions.
Key mannequin parts are captured in an IRModule in TVM utilizing TorchDynamo and Torch FX. The IRModule of the TVM can generate executable code for every perform, permitting them to be deployed in any surroundings that may run a minimum of the TVM minimal runtime (javascript being one in every of them).
They use TensorIR and MetaSchedule to create scripts that robotically generate environment friendly code. These transformations are tuned regionally to generate optimized GPU shaders using the system’s native GPU runtimes. They supply a repository for these changes, permitting future builds to be produced with out fine-tuning.
They assemble static reminiscence planning optimizations to optimize reminiscence reuse throughout a number of layers. The TVM net runtime makes use of Emscripten and typescript to facilitate producing module deployment.
As well as, they use the wasm port of the cuddling face rust tokenizers library.
Aside from the ultimate step, which creates a 400-loc JavaScript app to tie every little thing collectively, your entire workflow is completed in Python. Introducing new fashions is an thrilling byproduct of one of these participatory growth.
The open-source group is what makes all of this attainable. Specifically, the group depends on TVM Unity, the latest and fascinating addition to the TVM challenge, which supplies such Python-first interactive MLC growth experiences, permitting them to assemble extra optimizations in Python and progressively launch the app on the net. TVM Unity additionally facilitates the fast composition of novel ecosystem options.
Take a look at the Tool and Github Link. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t overlook to hitch our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
Tanushree Shenwai is a consulting intern at MarktechPost. She is at present pursuing her B.Tech from the Indian Institute of Expertise(IIT), Bhubaneswar. She is a Knowledge Science fanatic and has a eager curiosity within the scope of utility of synthetic intelligence in numerous fields. She is enthusiastic about exploring the brand new developments in applied sciences and their real-life utility.
[ad_2]
Source link
