


[ad_1]
The evolution of synthetic intelligence via the event of Massive Language Fashions (LLMs) has marked a big milestone within the quest to reflect human-like talents in producing textual content, reasoning, and decision-making. Nonetheless, aligning these fashions with human ethics and values has remained advanced. Conventional strategies, resembling Reinforcement Studying from Human Suggestions (RLHF), have made strides in integrating human preferences by fine-tuning LLMs post-training. These strategies, nevertheless, typically depend on simplifying the multifaceted nature of human preferences into scalar rewards, a course of that will not seize the whole thing of human values and moral issues.
Researchers from Microsoft Analysis have launched an strategy generally known as Direct Nash Optimization (DNO), a novel technique geared toward refining LLMs by specializing in normal preferences relatively than solely on reward maximization. The strategy emerges as a response to the restrictions of conventional RLHF methods, which, regardless of their advances, wrestle to completely embody advanced human preferences throughout the full coaching of LLMs. DNO introduces a paradigm shift by using a batched on-policy algorithm alongside a regression-based studying goal.
DNO is rooted within the commentary that current strategies may not absolutely harness the potential of LLMs to know and generate content material that aligns with nuanced human values. DNO affords a complete framework for post-training LLMs by straight optimising normal preferences. This strategy is characterised by its simplicity and scalability, attributed to the strategy’s modern use of batched on-policy updates and regression-based aims. These options enable DNO to supply a extra refined alignment of LLMs with human values, as demonstrated in in depth empirical evaluations.
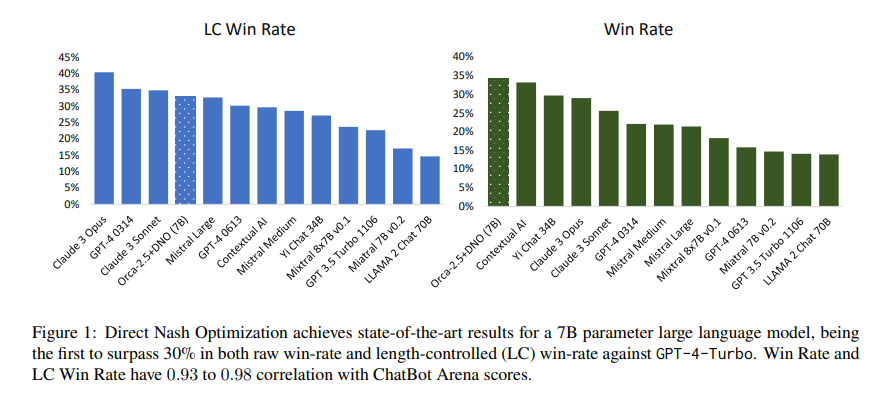
One in all DNO’s standout achievements is its implementation with the 7B parameter Orca-2.5 mannequin, which confirmed an unprecedented 33% win charge towards GPT-4-Turbo in AlpacaEval 2.0. This represents a big leap from the mannequin’s preliminary 7% win charge, showcasing an absolute acquire of 26% via the appliance of DNO. This outstanding efficiency positions DNO as a number one technique for post-training LLMs. It highlights its potential to surpass conventional fashions and methodologies in aligning LLMs extra intently with human preferences and moral requirements.
Analysis Snapshot

In conclusion, the DNO technique emerges as a pivotal development in refining LLMs, addressing the numerous problem of aligning these fashions with human moral requirements and complicated preferences. By shifting focus from conventional reward maximization to optimizing normal preferences, DNO overcomes the restrictions of earlier RLHF methods and units a brand new benchmark for post-training LLMs. The outstanding success demonstrated by the Orca-2.5 mannequin’s spectacular efficiency acquire in AlpacaEval 2.0 underscores its potential to revolutionize the sector.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our newsletter..
Don’t Neglect to affix our 40k+ ML SubReddit
Howdy, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m presently pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m keen about expertise and need to create new merchandise that make a distinction.
[ad_2]
Source link
