

[ad_1]
The aim of text-to-speech (TTS) is to generate high-quality, various speech that appears like actual individuals spoke it. Prosodies, speaker identities (similar to gender, accent, and timbre), talking and singing types, and extra all contribute to the richness of human speech. TTS methods have improved drastically in intelligibility and naturalness as neural networks and deep studying have progressed; some methods (similar to NaturalSpeech) have even reached human-level voice high quality on single-speaker recording-studio benchmarking datasets.
Resulting from an absence of range within the knowledge, earlier speaker-limited recording-studio datasets have been inadequate to seize the wide range of speaker identities, prosodies, and types in human speech. Nonetheless, utilizing few-shot or zero-shot applied sciences, TTS fashions will be educated on a big corpus to be taught these variations after which use these educated fashions to generalize to the infinite unseen situations. Quantizing the continual speech waveform into discrete tokens and modeling these tokens with autoregressive language fashions is widespread in immediately’s large-scale TTS methods.
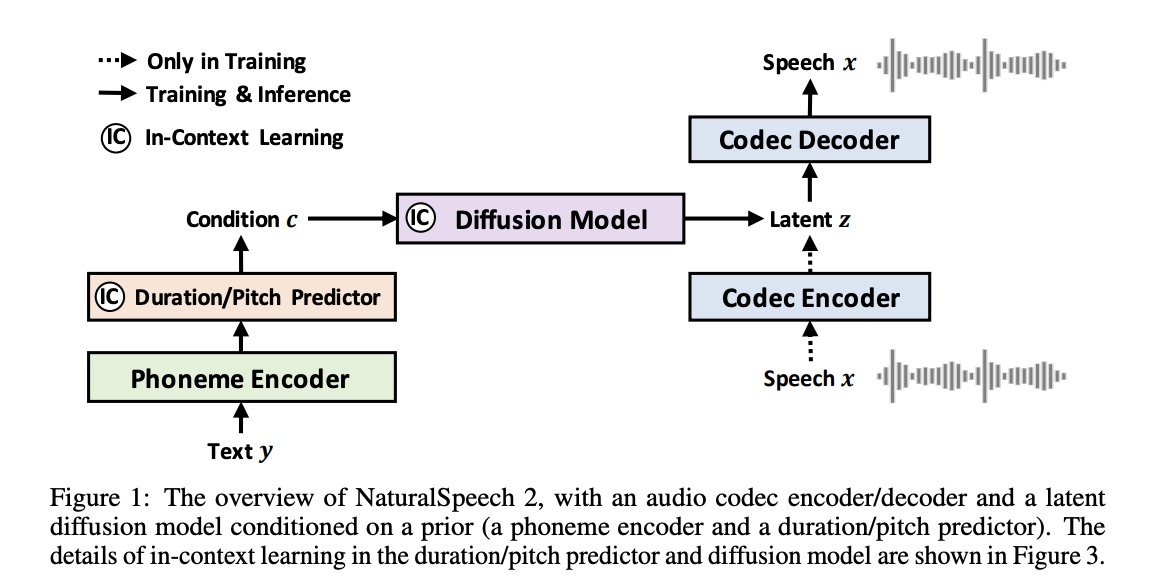
New analysis by Microsoft introduces NaturalSpeech 2, a TTS system that makes use of latent diffusion fashions to supply expressive prosody, good resilience, and, most crucially, robust zero-shot capability for voice synthesis. The researchers started by coaching a neural audio codec that makes use of a codec encoder to rework a speech waveform right into a collection of latent vectors and a codec decoder to revive the unique waveform. After acquiring earlier vectors from a phoneme encoder, a period predictor, and a pitch predictor, they use a diffusion mannequin to assemble these latent vectors.
The next are examples of design choices which can be mentioned of their paper:
- In prior works, speech is usually quantized with quite a few residual quantizers to ensure the standard of the neural codec’s speech reconstruction. This burdens the acoustic mannequin (autoregressive language mannequin) closely as a result of the resultant discrete token sequence is sort of lengthy. As a substitute of utilizing tokens, the group used steady vectors. Due to this fact, they make use of steady vectors as an alternative of discrete tokens, which shorten the sequence and supply extra knowledge for correct speech reconstruction on the granular degree.
- Changing autoregressive fashions with diffusion ones.
- Studying in context by speech prompting mechanisms. The group developed speech prompting mechanisms to advertise in-context studying within the diffusion mannequin and pitch/period predictors, bettering the zero-shot capability by encouraging the diffusion fashions to stick to the traits of the speech immediate.
- NaturalSpeech 2 is extra dependable and secure than its autoregressive predecessors because it requires solely a single acoustic mannequin (the diffusion mannequin) as an alternative of two-stage token prediction. In different phrases, it will probably use its period/pitch prediction and non-autoregressive technology to use to types aside from speech (similar to a singing voice).
To reveal the efficacy of those architectures, the researchers educated NaturalSpeech 2 with 400M mannequin parameters and 44K hours of speech knowledge. They then used it to create speech in zero-shot situations (with just a few seconds of speech immediate) with varied speaker identities, prosody, and types (e.g., singing). The findings present that NaturalSpeech 2 outperforms prior highly effective TTS methods in experiments and generates pure speech in zero-shot circumstances. It achieves extra related prosody with the speech immediate and ground-truth speech. It additionally achieves comparable or higher naturalness (relating to CMOS) than the ground-truth speech on LibriTTS and VCTK take a look at units. The experimental outcomes additionally present that it will probably generate singing voices in a novel timbre with a brief singing immediate or, curiously, with solely a speech immediate, unlocking the actually zero-shot singing synthesis.
Sooner or later, the group plans to research efficient strategies, similar to consistency fashions, to speed up the diffusion mannequin and examine widespread talking and singing voice coaching to allow stronger blended talking/singing capabilities.
Take a look at the Paper and Project Page. Don’t neglect to hitch our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra. When you have any questions relating to the above article or if we missed something, be happy to e-mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Tanushree Shenwai is a consulting intern at MarktechPost. She is at the moment pursuing her B.Tech from the Indian Institute of Expertise(IIT), Bhubaneswar. She is a Knowledge Science fanatic and has a eager curiosity within the scope of utility of synthetic intelligence in varied fields. She is enthusiastic about exploring the brand new developments in applied sciences and their real-life utility.
[ad_2]
Source link
