

[ad_1]
The transformer structure has develop into a go-to selection for representing varied area constructions. The empirical inductive biases of the transformer make it a great candidate for scaling. This paves the best way for the periodic coaching and launch of expanded variations of current, smaller fashions. Though typically a scaled-up model of their smaller counterparts, new cases of such fashions are usually educated from the beginning. Since even the smallest fashions want a major quantity of computational assets to coach, the parameters of smaller pretrained fashions must be used to hurry up the coaching of bigger fashions.
When taking a look at this concern from the attitude of mannequin progress, one technique is to make use of the pretrained parameters of a smaller mannequin to initialize a number of the parameters of the bigger mannequin. Latest analysis has proven that coaching might be accelerated by copying a subset of the pretrained parameters to initialize the brand new parameters after which fine-tuning the whole community. This contrasts earlier works, which typically froze the parameters initialized from the pretrained mannequin and solely educated the brand new (randomly initialized) parameters.
The Laptop Science and Synthetic Intelligence Laboratory (CSAIL) suggests utilizing pre-trained, smaller language fashions to spice up the effectiveness of those coaching approaches at a lowered price and time dedication. Their strategy makes use of machine studying to “develop” a extra advanced mannequin from an easier one to encode the smaller mannequin’s prior information. This permits for the bigger mannequin to be educated extra shortly. The crew doesn’t simply throw away outdated fashions however takes their greatest elements and makes use of them to create one thing new.
In comparison with strategies that contain coaching a brand new mannequin from scratch, their strategy reduces the computational effort and time wanted to coach a giant mannequin by round 50%. As well as, the MIT methodology produced fashions with the identical or increased efficiency as these produced by different strategies that make use of smaller fashions to expedite the coaching of bigger fashions.
Time financial savings in coaching massive fashions may positively influence analysis effectivity, price, and environmental sustainability by slicing down on carbon emissions produced in the course of the coaching course of. This might additionally permit smaller analysis teams to entry and collaborate with these huge fashions, which may pave the best way for quite a few new developments.
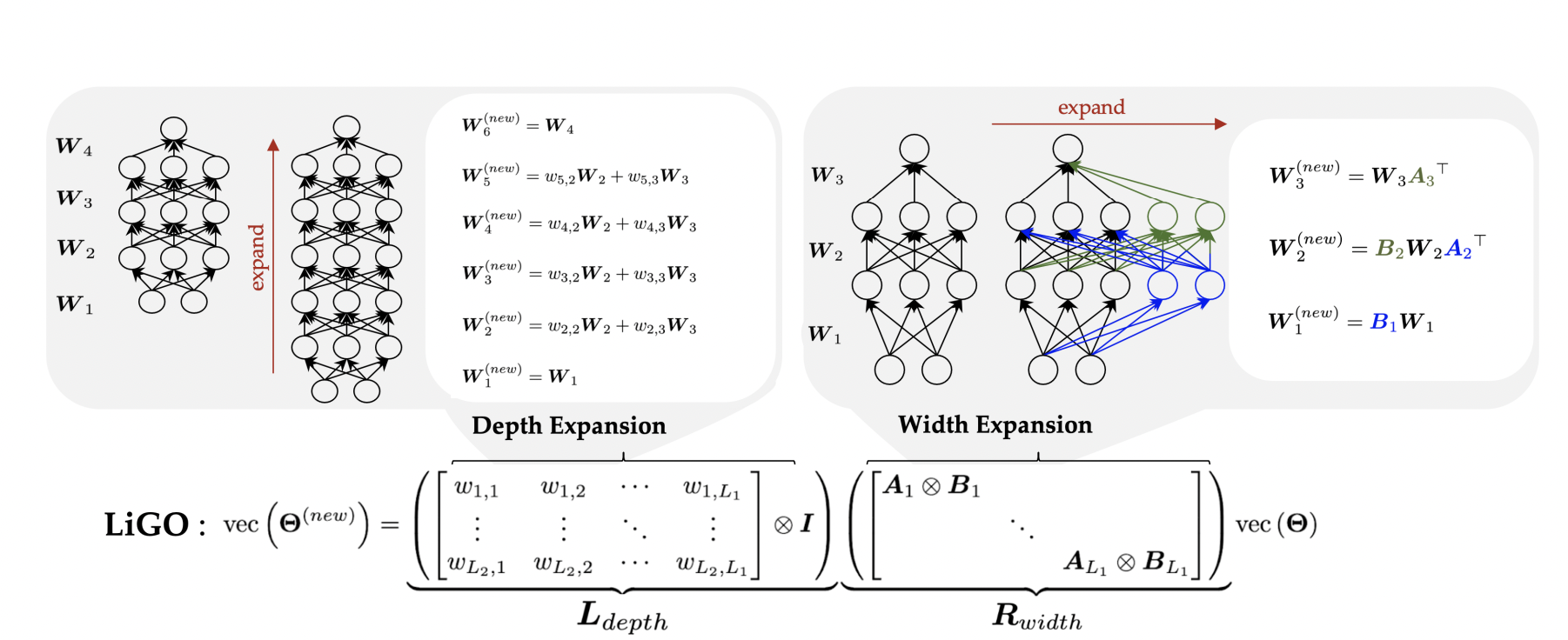
The proposed technique is known as Realized Linear Development Operator (LiGO), which expands a community’s breadth and depth primarily based on a smaller community’s traits and empirical proof. Researchers make the most of ML to find a linear mapping of the simplified mannequin’s parameters. As a mathematical process, this linear map takes as enter the parameters of the smaller mannequin and produces as output the parameters of the bigger mannequin.
Researchers could want to create a mannequin with a billion parameters, however the smaller mannequin could also be relatively huge (perhaps it has 100 million parameters). To make the linear map extra manageable for a machine-learning system, the LiGO methodology segments it.
LiGO is superior to various methods as a result of it grows in each width and depth on the similar time. Additionally they spotlight that inputting the smaller mannequin and its specs permits customers to regulate the bigger mannequin’s width and depth to their liking.
Their resolution outpaced all baselines, together with coaching a brand-new mannequin from the beginning and model-growth approaches. Their technique reduces the computational prices of coaching imaginative and prescient and language fashions by round 50%, with many circumstances seeing a efficiency enchancment. The crew additionally found LiGO was potential even with out a smaller, pretrained mannequin to hurry up transformer coaching. They hope to make use of LiGO on much more advanced fashions sooner or later.
Take a look at the Paper, Project, and Reference. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t overlook to affix our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
Tanushree Shenwai is a consulting intern at MarktechPost. She is at present pursuing her B.Tech from the Indian Institute of Know-how(IIT), Bhubaneswar. She is a Information Science fanatic and has a eager curiosity within the scope of utility of synthetic intelligence in varied fields. She is obsessed with exploring the brand new developments in applied sciences and their real-life utility.
[ad_2]
Source link
