


[ad_1]
Language modeling is used to find out the likelihood of the phrase’s sequence. This modeling has numerous purposes i.e. recognition of speech, filtering of spam, and so forth. [1].
Pure language processing (NLP) is the convergence of artificial intelligence (AI) and linguistics. It’s used to make the computer systems perceive the phrases or statements which are written in human languages. NLP has been developed for making the work and communication with the pc straightforward and satisfying. As all the pc customers can’t be well-known by the precise languages of machines so NLP works higher with the customers who can not have time for studying the brand new languages of machines. We are able to outline language as a algorithm or symbols. Symbols are mixed to convey the data. They’re tyrannized by the algorithm. NLP is classed into two parts which are pure language understanding and pure language technology which evolves the duties for understanding and producing the textual content. The classifications of NLP are proven in Determine 1 [2].
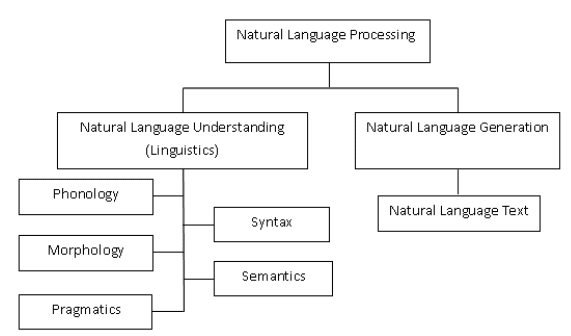
Determine 1 Classifications of NLP
Language modelings are labeled as follows:
Statistical language modelings: On this modeling, there’s the event of probabilistic fashions. This probabilistic mannequin predicts the subsequent phrase in a sequence. For instance N-gram language modeling. This modeling can be utilized for disambiguating the enter. They can be utilized for choosing a possible resolution. This modeling will depend on the speculation of likelihood. Likelihood is to foretell how seemingly one thing will happen.
Neural language modelings: Neural language modeling provides higher outcomes than the classical strategies each for the standalone fashions and when the fashions are integrated into the bigger fashions on the difficult duties i.e. speech recognitions and machine translations. One technique of performing neural language modeling is by phrase embedding [1].
N-gram is a sequence of the N-words within the modeling of NLP. Take into account an instance of the assertion for modeling. “I like studying historical past books and watching documentaries”. In a single-gram or unigram, there’s a one-word sequence. As for the above assertion, in a single gram it may be “I”, “love”, “historical past”, “books”, “and”, “watching”, “documentaries”. In two-gram or the bi-gram, there’s the two-word sequence i.e. “I like”, “love studying”, or “historical past books”. Within the three-gram or the tri-gram, there are the three phrases sequences i.e. “I like studying”, “historical past books,” or “and watching documentaries” [3]. The illustration of the N-gram modeling i.e. for N=1,2,3 is given beneath in Determine 2 [5].
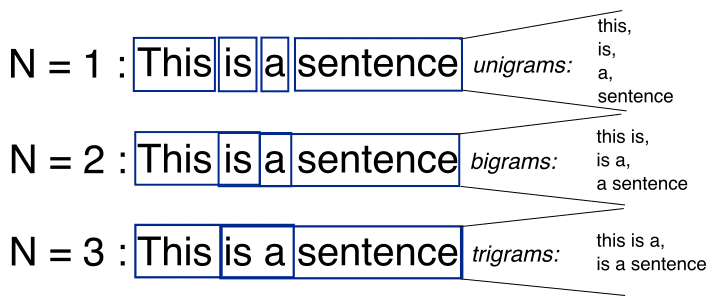
Determine 2 Uni-gram, Bi-gram, and Tri-gram Mannequin
For N-1 phrases, the N-gram modeling predicts most occurred phrases that may observe the sequences. The mannequin is the probabilistic language mannequin which is skilled on the gathering of the textual content. This mannequin is helpful in purposes i.e. speech recognition, and machine translations. A easy mannequin has some limitations that may be improved by smoothing, interpolations, and again off. So, the N-gram language mannequin is about discovering likelihood distributions over the sequences of the phrase. Take into account the sentences i.e. “There was heavy rain” and “There was heavy flood”. By utilizing expertise, it may be mentioned that the primary assertion is sweet. The N-gram language mannequin tells that the “heavy rain” happens extra steadily than the “heavy flood”. So, the primary assertion is extra more likely to happen and it is going to be then chosen by this mannequin. Within the one-gram mannequin, the mannequin normally depends on that which phrase happens usually with out pondering the earlier phrases. In 2-gram, solely the earlier phrase is taken into account for predicting the present phrase. In 3-gram, two earlier phrases are thought-about. Within the N-gram language mannequin the next possibilities are calculated:
P (“There was heavy rain”) = P (“There”, “was”, “heavy”, “rain”) = P (“There”) P (“was” |“There”) P (“heavy”| “There was”) P (“rain” |“There was heavy”).
As it’s not sensible to calculate the conditional likelihood however through the use of the “Markov Assumptions”, that is approximated to the bi-gram mannequin as [4]:
P (“There was heavy rain”) ~ P (“There”) P (“was” |“'There”) P (“heavy” |“was”) P (“rain” |“heavy”)
In speech recognition, the enter might be noisy. This noise could make a flawed speech to the textual content conversion. The N-gram language mannequin corrects the noise through the use of likelihood information. Likewise, this mannequin is utilized in machine translations for producing extra pure statements in goal and specified languages. For spelling error corrections, the dictionary is ineffective generally. As an example, “in about fifteen minutes” ‘minuets’ is a sound phrase in response to the dictionary however it’s incorrect within the phrase. The N-gram language mannequin can rectify such a error.
The N-gram language mannequin is mostly on the phrase ranges. It’s also used on the character ranges for doing the stemming i.e. for separating the basis phrases from a suffix. By wanting on the N-gram mannequin, the languages might be labeled or differentiated between the US and UK spellings. Many purposes get profit from the N-gram mannequin together with tagging of a part of the speech, pure language generations, phrase similarities, and sentiments extraction. [4].
The N-gram language mannequin has additionally some limitations. There’s a drawback with the out of vocabulary phrases. These phrases are throughout the testing however not within the coaching. One resolution is to make use of the mounted vocabulary after which convert out vocabulary phrases within the coaching to pseudowords. When applied within the sentiment evaluation, the bi-gram mannequin outperformed the uni-gram mannequin however the variety of the options is then doubled. So, the scaling of the N-gram mannequin to the bigger information units or transferring to the higher-order wants higher function choice approaches. The N-gram mannequin captures the long-distance context poorly. It has been proven after each 6-grams, the achieve of efficiency is proscribed.
References
- (N-Gram Language Modelling with NLTK, 30 Could, 2021)
- (Diksha Khurana, Aditya Koli, Kiran Khatter, Sukhdev Singh, August 2017)
- (Mohdsanadzakirizvi, August 8, 2019)
- (N-Gram Mannequin, March 29)
- (N-Gram)
Neeraj Agarwal is a founding father of Algoscale, an information consulting firm overlaying information engineering, utilized AI, information science, and product engineering. He has over 9 years of expertise within the area and has helped a variety of organizations from start-ups to Fortune 100 corporations ingest and retailer monumental quantities of uncooked information so as to translate it into actionable insights for higher decision-making and quicker enterprise worth.
[ad_2]
Source link
