


[ad_1]

An indication of the RvS coverage we study with simply supervised studying and a depth-two MLP. It makes use of no TD studying, benefit reweighting, or Transformers!
Offline reinforcement studying (RL) is conventionally approached utilizing value-based strategies primarily based on temporal distinction (TD) studying. Nonetheless, many latest algorithms reframe RL as a supervised studying downside. These algorithms study conditional insurance policies by conditioning on objective states (Lynch et al., 2019; Ghosh et al., 2021), reward-to-go (Kumar et al., 2019; Chen et al., 2021), or language descriptions of the duty (Lynch and Sermanet, 2021).
We discover the simplicity of those strategies fairly interesting. If supervised studying is sufficient to resolve RL issues, then offline RL might change into broadly accessible and (comparatively) simple to implement. Whereas TD studying should delicately stability an actor coverage with an ensemble of critics, these supervised studying strategies prepare only one (conditional) coverage, and nothing else!
So, how can we use these strategies to successfully resolve offline RL issues? Prior work places ahead a lot of intelligent ideas and methods, however these methods are generally contradictory, making it difficult for practitioners to determine how you can efficiently apply these strategies. For instance, RCPs (Kumar et al., 2019) require rigorously reweighting the coaching information, GCSL (Ghosh et al., 2021) requires iterative, on-line information assortment, and Determination Transformer (Chen et al., 2021) makes use of a Transformer sequence mannequin because the coverage community.
Which, if any, of those hypotheses are right? Do we have to reweight our coaching information primarily based on estimated benefits? Are Transformers essential to get a high-performing coverage? Are there different crucial design choices which were not noted of prior work?
Our work goals to reply these questions by making an attempt to determine the important parts of offline RL by way of supervised studying. We run experiments throughout 4 suites, 26 environments, and eight algorithms. When the mud settles, we get aggressive efficiency in each atmosphere suite we think about using remarkably easy parts. The video above reveals the complicated habits we study utilizing simply supervised studying with a depth-two MLP – no TD studying, information reweighting, or Transformers!
Let’s start with an outline of the algorithm we examine. Whereas numerous prior work (Kumar et al., 2019; Ghosh et al., 2021; and Chen et al., 2021) share the identical core algorithm, it lacks a standard identify. To fill this hole, we suggest the time period RL by way of Supervised Studying (RvS). We aren’t proposing any new algorithm however somewhat exhibiting how prior work could be considered from a unifying framework; see Determine 1.
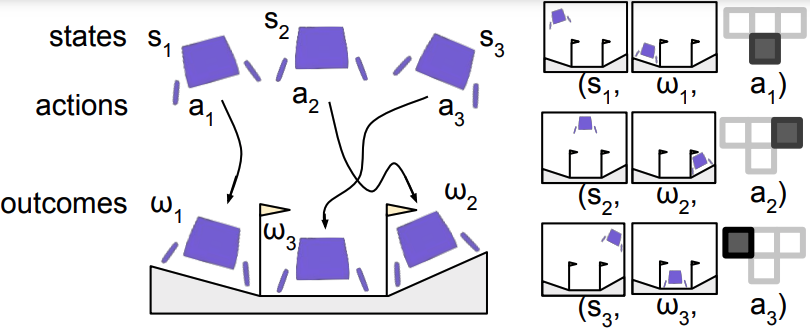
Determine 1. (Left) A replay buffer of expertise (Proper) Hindsight relabelled coaching information
RL by way of Supervised Studying takes as enter a replay buffer of expertise together with states, actions, and outcomes. The outcomes could be an arbitrary perform of the trajectory, together with a objective state, reward-to-go, or language description. Then, RvS performs hindsight relabeling to generate a dataset of state, motion, and consequence triplets. The instinct is that the actions which are noticed present supervision for the outcomes which are reached. With this coaching dataset, RvS performs supervised studying by maximizing the chance of the actions given the states and outcomes. This yields a conditional coverage that may situation on arbitrary outcomes at take a look at time.
In our experiments, we give attention to the next three key questions.
- Which design choices are crucial for RL by way of supervised studying?
- How properly does RL by way of supervised studying truly work? We will do RL by way of supervised studying, however would utilizing a unique offline RL algorithm carry out higher?
- What sort of consequence variable ought to we situation on? (And does it even matter?)
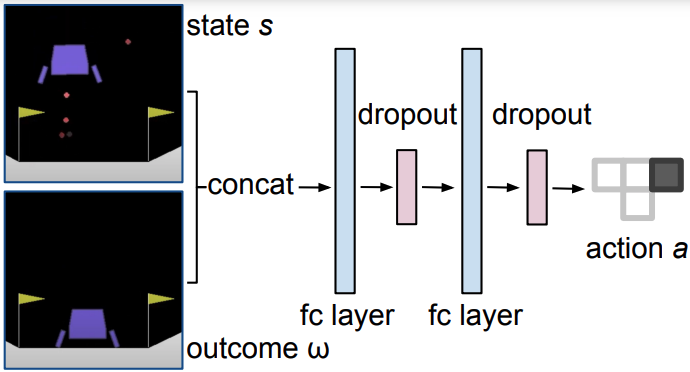
Determine 2. Our RvS structure. A depth-two MLP suffices in each atmosphere suite we think about.
We get good efficiency utilizing only a depth-two multi-layer perceptron. In reality, that is aggressive with all beforehand revealed architectures we’re conscious of, together with a Transformer sequence mannequin. We simply concatenate the state and consequence earlier than passing them by two fully-connected layers (see Determine 2). The keys that we determine are having a community with massive capability – we use width 1024 – in addition to dropout in some environments. We discover that this works properly with out reweighting the coaching information or performing any further regularization.
After figuring out these key design choices, we examine the general efficiency of RvS compared to earlier strategies. This weblog put up will overview outcomes from two of the suites we think about within the paper.

The primary suite is D4RL Health club, which accommodates the usual MuJoCo halfcheetah, hopper, and walker robots. The problem in D4RL Health club is to study locomotion insurance policies from offline datasets of various high quality. For instance, one offline dataset accommodates rollouts from a completely random coverage. One other dataset accommodates rollouts from a “medium” coverage skilled partway to convergence, whereas one other dataset is a combination of rollouts from medium and knowledgeable insurance policies.
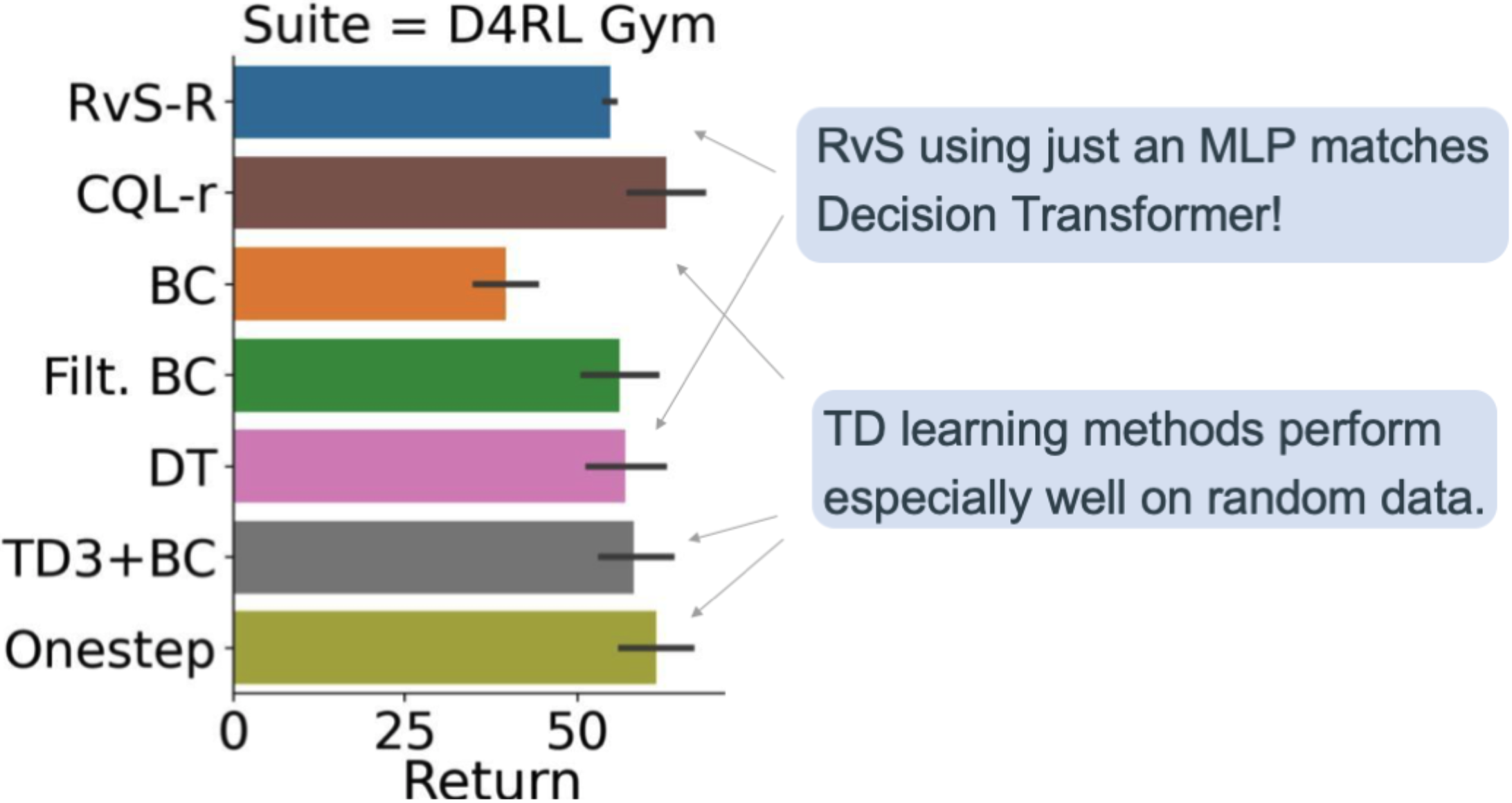
Determine 3. General efficiency in D4RL Health club.
Determine 3 reveals our leads to D4RL Health club. RvS-R is our implementation of RvS conditioned on rewards (illustrated in Determine 2). On common throughout all 12 duties within the suite, we see that RvS-R, which makes use of only a depth-two MLP, is aggressive with Determination Transformer (DT; Chen et al., 2021). We additionally see that RvS-R is aggressive with the strategies that use temporal distinction (TD) studying, together with CQL-R (Kumar et al., 2020), TD3+BC (Fujimoto et al., 2021), and Onestep (Brandfonbrener et al., 2021). Nonetheless, the TD studying strategies have an edge as a result of they carry out particularly properly on the random datasets. This means that one may favor TD studying over RvS when coping with low-quality information.

The second suite is D4RL AntMaze. This suite requires a quadruped to navigate to a goal location in mazes of various measurement. The problem of AntMaze is that many trajectories comprise solely items of the complete path from the begin to the objective location. Studying from these trajectories requires stitching collectively these items to get the complete, profitable path.
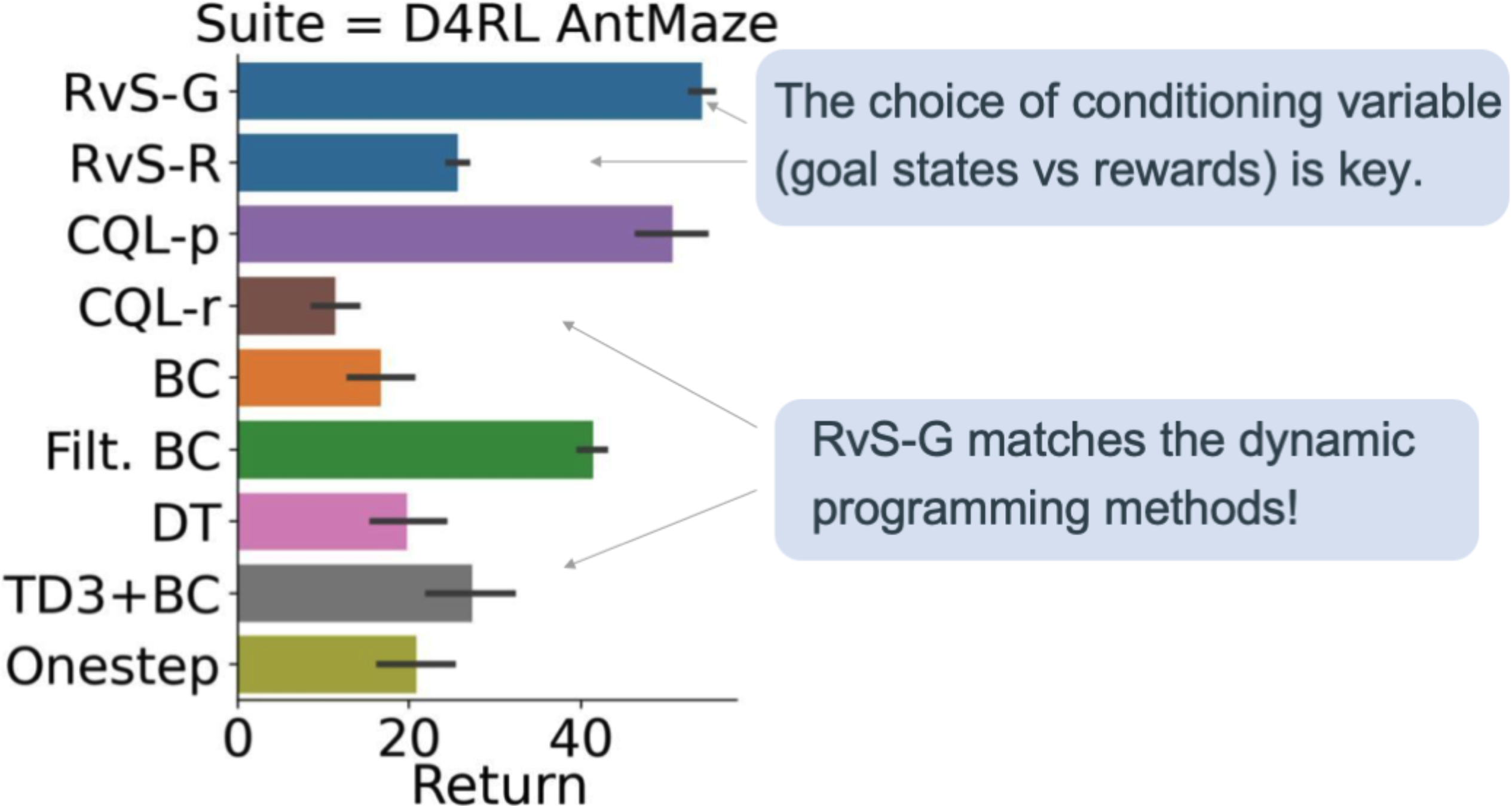
Determine 4. General efficiency in D4RL AntMaze.
Our AntMaze leads to Determine 4 spotlight the significance of the conditioning variable. Whereas conditioning RvS on rewards (RvS-R) was your best option of the conditioning variable in D4RL Health club, we discover that in D4RL AntMaze, it’s significantly better to situation RvS on $(x, y)$ objective coordinates (RvS-G). Once we do that, we see that RvS-G compares favorably to TD studying! This was stunning to us as a result of TD studying explicitly performs dynamic programming utilizing the Bellman equation.
Why does goal-conditioning carry out higher than reward conditioning on this setting? Recall that AntMaze is designed so that straightforward imitation will not be sufficient: optimum strategies should sew collectively components of suboptimal trajectories to determine how you can attain the objective. In precept, TD studying can resolve this with temporal compositionality. With the Bellman equation, TD studying can mix a path from A to B with a path from B to C, yielding a path from A to C. RvS-R, together with different habits cloning strategies, doesn’t profit from this temporal compositionality. We hypothesize that RvS-G, however, advantages from spatial compositionality. It’s because, in AntMaze, the coverage wanted to succeed in one objective is much like the coverage wanted to succeed in a close-by objective. We see correspondingly that RvS-G beats RvS-R.
After all, conditioning RvS-G on $(x, y)$ coordinates represents a type of prior information concerning the activity. However this additionally highlights an necessary consideration for RvS strategies: the selection of conditioning data is critically necessary, and it could rely considerably on the duty.
General, we discover that in a various set of environments, RvS works properly while not having any fancy algorithmic methods (comparable to information reweighting) or fancy architectures (comparable to Transformers). Certainly, our easy RvS setup can match, and even outperform, strategies that make the most of (conservative) TD studying. The keys for RvS that we determine are mannequin capability, regularization, and the conditioning variable.
In our work, we handcraft the conditioning variable, comparable to $(x, y)$ coordinates in AntMaze. Past the usual offline RL setup, this introduces an extra assumption, specifically, that now we have some prior details about the construction of the duty. We predict an thrilling course for future work could be to take away this assumption by automating the training of the objective area.
We packaged our open-source code in order that it will probably routinely deal with all of the dependencies for you. After downloading the code, you’ll be able to run these 5 instructions to breed our experiments:
docker construct -t rvs:newest .
docker run -it --rm -v $(pwd):/rvs rvs:newest bash
cd rvs
pip set up -e .
bash experiments/launch_gym_rvs_r.sh
This put up is predicated on the paper:
RvS: What is Essential for Offline RL via Supervised Learning?
Scott Emmons, Benjamin Eysenbach, Ilya Kostrikov, Sergey Levine
Worldwide Convention on Studying Representations (ICLR), 2022
[Paper] [Code]
[ad_2]
Source link
