

[ad_1]
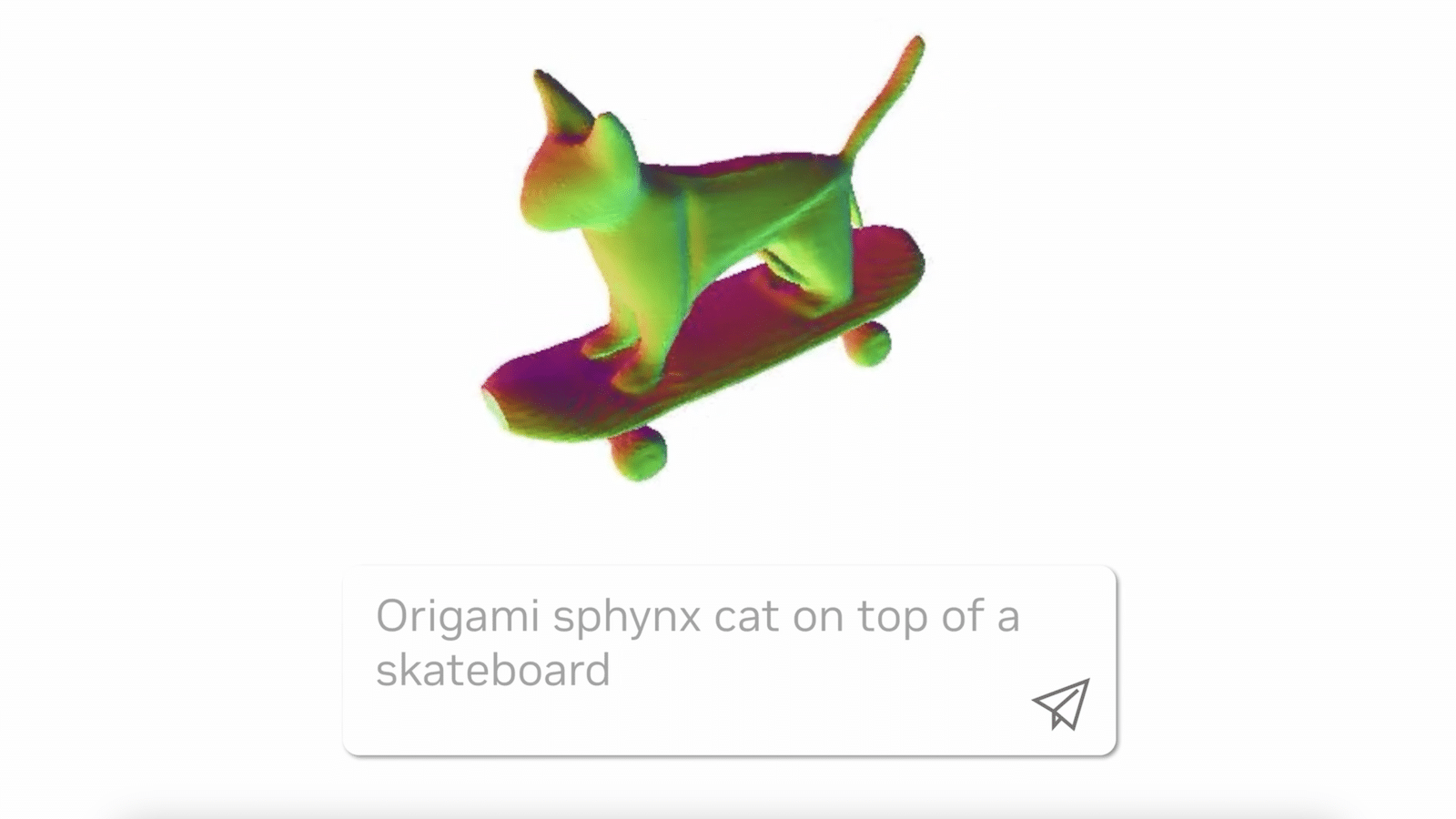
NVIDIA researchers have pumped a double shot of acceleration into their newest text-to-3D generative AI mannequin, dubbed LATTE3D.
Like a digital 3D printer, LATTE3D turns textual content prompts into 3D representations of objects and animals inside a second.
Crafted in a preferred format used for traditional rendering functions, the generated shapes may be simply served up in digital environments for creating video video games, advert campaigns, design initiatives or digital coaching grounds for robotics.
“A yr in the past, it took an hour for AI fashions to generate 3D visuals of this high quality — and the present cutting-edge is now round 10 to 12 seconds,” mentioned Sanja Fidler, vice chairman of AI analysis at NVIDIA, whose Toronto-based AI lab group developed LATTE3D. “We will now produce outcomes an order of magnitude quicker, placing near-real-time text-to-3D technology inside attain for creators throughout industries.”
This development signifies that LATTE3D can produce 3D shapes close to immediately when operating inference on a single GPU, such because the NVIDIA RTX A6000, which was used for the NVIDIA Analysis demo.
Ideate, Generate, Iterate: Shortening the Cycle
As an alternative of beginning a design from scratch or combing by a 3D asset library, a creator may use LATTE3D to generate detailed objects as shortly as concepts pop into their head.
The mannequin generates a couple of completely different 3D form choices based mostly on every textual content immediate, giving a creator choices. Chosen objects may be optimized for larger high quality inside a couple of minutes. Then, customers can export the form into graphics software program functions or platforms resembling NVIDIA Omniverse, which permits Universal Scene Description (OpenUSD)-based 3D workflows and functions.

Whereas the researchers educated LATTE3D on two particular datasets — animals and on a regular basis objects — builders may use the identical mannequin structure to coach the AI on different knowledge sorts.
If educated on a dataset of 3D crops, for instance, a model of LATTE3D may assist a panorama designer shortly fill out a backyard rendering with bushes, flowering bushes and succulents whereas brainstorming with a consumer. If educated on family objects, the mannequin may generate objects to fill in 3D simulations of properties, which builders may use to coach private assistant robots earlier than they’re examined and deployed in the actual world.
LATTE3D was educated utilizing NVIDIA A100 Tensor Core GPUs. Along with 3D shapes, the mannequin was educated on various textual content prompts generated utilizing ChatGPT to enhance the mannequin’s means to deal with the assorted phrases a consumer may give you to explain a selected 3D object — for instance, understanding that prompts that includes varied canine species ought to all generate doglike shapes.

NVIDIA Research includes a whole bunch of scientists and engineers worldwide, with groups centered on matters together with AI, laptop graphics, laptop imaginative and prescient, self-driving automobiles and robotics.
Researchers shared work at NVIDIA GTC this week that advances the cutting-edge for coaching diffusion fashions. Learn extra on the NVIDIA Technical Blog, and see the complete listing of NVIDIA Research sessions at GTC, operating in San Jose, Calif., and on-line by March 21.
For the most recent NVIDIA AI information, watch the replay of NVIDIA founder and CEO Jensen Huang’s keynote deal with at GTC:
[ad_2]
Source link
