


[ad_1]
It’s official: NVIDIA delivered the world’s quickest platform in industry-standard exams for inference on generative AI.
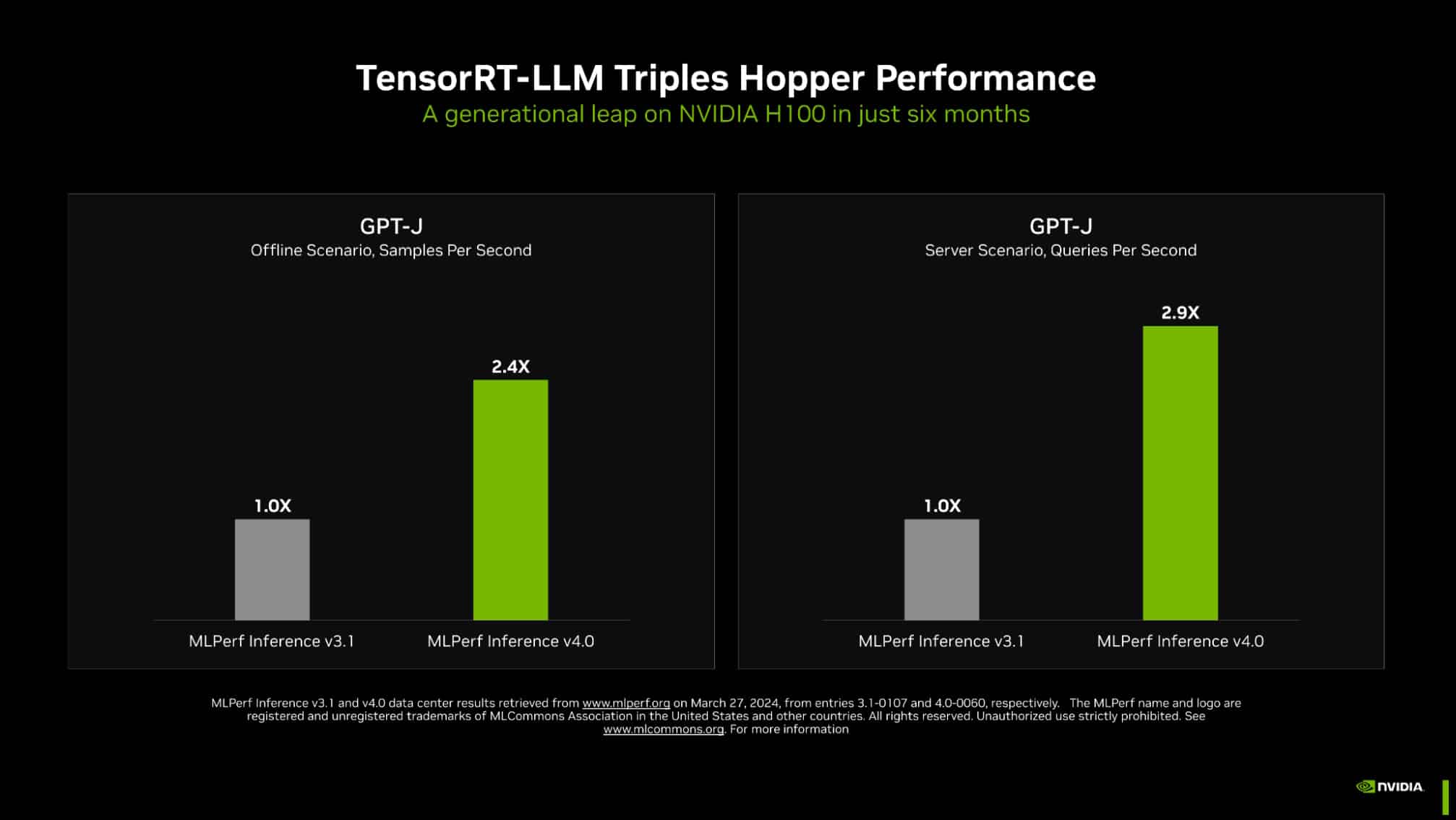
Within the newest MLPerf benchmarks, NVIDIA TensorRT-LLM — software program that speeds and simplifies the advanced job of inference on large language models — boosted the efficiency of NVIDIA Hopper architecture GPUs on the GPT-J LLM practically 3x over their outcomes simply six months in the past.
The dramatic speedup demonstrates the ability of NVIDIA’s full-stack platform of chips, techniques and software program to deal with the demanding necessities of operating generative AI.
Main corporations are using TensorRT-LLM to optimize their fashions. And NVIDIA NIM — a set of inference microservices that features inferencing engines like TensorRT-LLM — makes it simpler than ever for companies to deploy NVIDIA’s inference platform.
Elevating the Bar in Generative AI
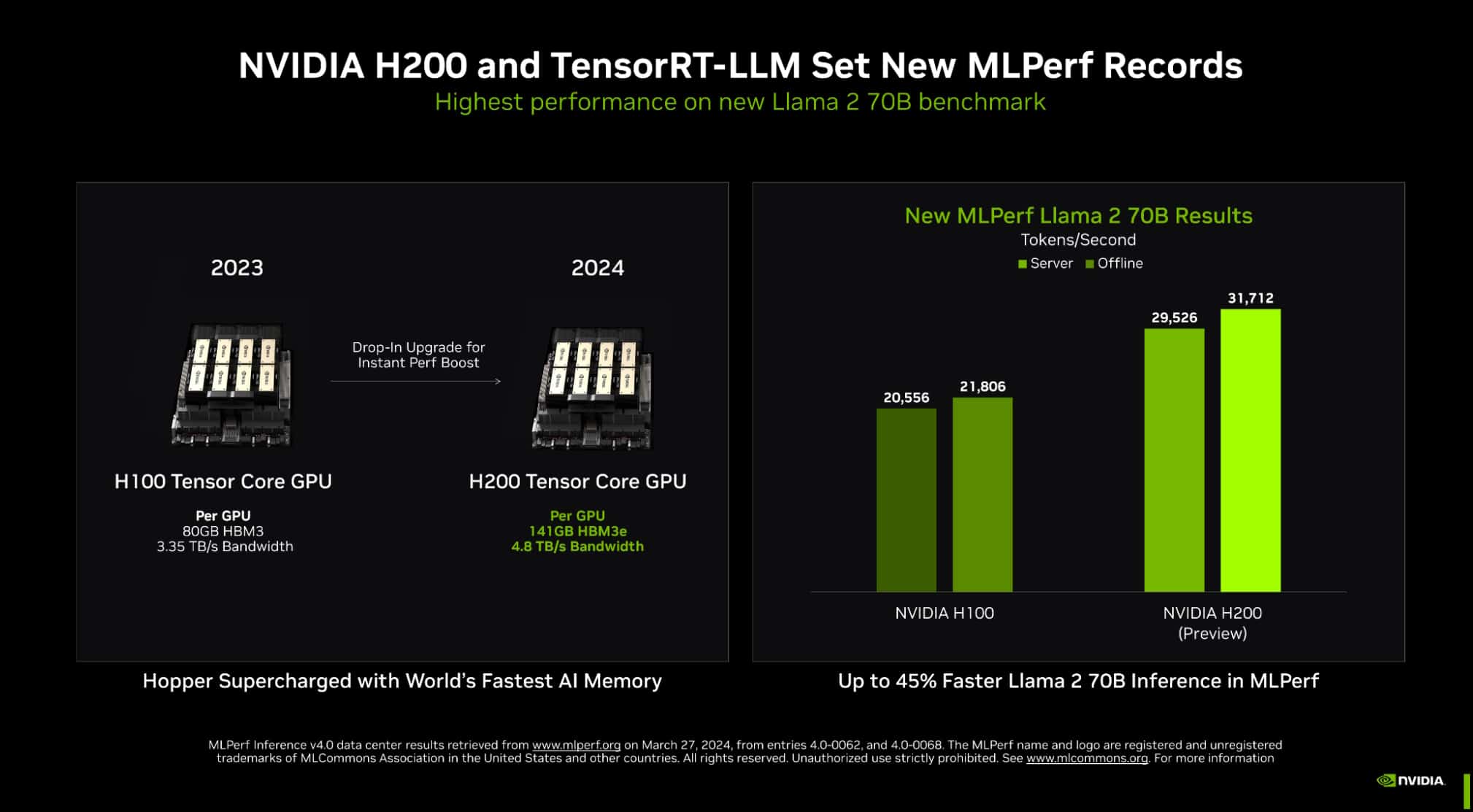
TensorRT-LLM operating on NVIDIA H200 Tensor Core GPUs — the most recent, memory-enhanced Hopper GPUs — delivered the quickest efficiency operating inference in MLPerf’s greatest take a look at of generative AI to this point.
The brand new benchmark makes use of the most important model of Llama 2, a state-of-the-art giant language mannequin packing 70 billion parameters. The mannequin is greater than 10x bigger than the GPT-J LLM first used within the September benchmarks.
The memory-enhanced H200 GPUs, of their MLPerf debut, used TensorRT-LLM to supply as much as 31,000 tokens/second, a document on MLPerf’s Llama 2 benchmark.
The H200 GPU outcomes embody as much as 14% good points from a customized thermal answer. It’s one instance of improvements past normal air cooling that techniques builders are making use of to their NVIDIA MGX designs to take the efficiency of Hopper GPUs to new heights.
Reminiscence Increase for NVIDIA Hopper GPUs
NVIDIA is sampling H200 GPUs to prospects right this moment and delivery within the second quarter. They’ll be out there quickly from practically 20 main system builders and cloud service suppliers.
H200 GPUs pack 141GB of HBM3e operating at 4.8TB/s. That’s 76% extra reminiscence flying 43% sooner in comparison with H100 GPUs. These accelerators plug into the identical boards and techniques and use the identical software program as H100 GPUs.
With HBM3e reminiscence, a single H200 GPU can run a whole Llama 2 70B mannequin with the very best throughput, simplifying and rushing inference.
GH200 Packs Even Extra Reminiscence
Much more reminiscence — as much as 624GB of quick reminiscence, together with 144GB of HBM3e — is packed in NVIDIA GH200 Superchips, which mix on one module a Hopper structure GPU and a power-efficient NVIDIA Grace CPU. NVIDIA accelerators are the primary to make use of HBM3e reminiscence know-how.
With practically 5 TB/second reminiscence bandwidth, GH200 Superchips delivered standout efficiency, together with on memory-intensive MLPerf exams comparable to recommender systems.
Sweeping Each MLPerf Check
On a per-accelerator foundation, Hopper GPUs swept each take a look at of AI inference within the newest spherical of the MLPerf {industry} benchmarks.
The benchmarks cowl right this moment’s hottest AI workloads and situations, together with generative AI, advice techniques, pure language processing, speech and laptop imaginative and prescient. NVIDIA was the one firm to submit outcomes on each workload within the newest spherical and each spherical since MLPerf’s information heart inference benchmarks started in October 2020.
Continued efficiency good points translate into decrease prices for inference, a big and rising a part of the each day work for the hundreds of thousands of NVIDIA GPUs deployed worldwide.
Advancing What’s Potential
Pushing the boundaries of what’s potential, NVIDIA demonstrated three modern strategies in a particular part of the benchmarks known as the open division, created for testing superior AI strategies.
NVIDIA engineers used a way known as structured sparsity — a means of decreasing calculations, first launched with NVIDIA A100 Tensor Core GPUs — to ship as much as 33% speedups on inference with Llama 2.
A second open division take a look at discovered inference speedups of as much as 40% utilizing pruning, a means of simplifying an AI mannequin — on this case, an LLM — to extend inference throughput.
Lastly, an optimization known as DeepCache lowered the mathematics required for inference with the Steady Diffusion XL mannequin, accelerating efficiency by a whopping 74%.
All these outcomes had been run on NVIDIA H100 Tensor Core GPUs.
A Trusted Supply for Customers
MLPerf’s exams are clear and goal, so customers can depend on the outcomes to make knowledgeable shopping for choices.
NVIDIA’s companions take part in MLPerf as a result of they understand it’s a worthwhile instrument for patrons evaluating AI techniques and companies. Companions submitting outcomes on the NVIDIA AI platform on this spherical included ASUS, Cisco, Dell Applied sciences, Fujitsu, GIGABYTE, Google, Hewlett Packard Enterprise, Lenovo, Microsoft Azure, Oracle, QCT, Supermicro, VMware (not too long ago acquired by Broadcom) and Wiwynn.
All of the software program NVIDIA used within the exams is on the market within the MLPerf repository. These optimizations are repeatedly folded into containers out there on NGC, NVIDIA’s software program hub for GPU functions, in addition to NVIDIA AI Enterprise — a safe, supported platform that features NIM inference microservices.
The Subsequent Massive Factor
The use instances, mannequin sizes and datasets for generative AI proceed to develop. That’s why MLPerf continues to evolve, including real-world exams with widespread fashions like Llama 2 70B and Steady Diffusion XL.
Protecting tempo with the explosion in LLM mannequin sizes, NVIDIA founder and CEO Jensen Huang introduced final week at GTC that the NVIDIA Blackwell architecture GPUs will ship new ranges of efficiency required for the multitrillion-parameter AI fashions.
Inference for giant language fashions is troublesome, requiring each experience and the full-stack structure NVIDIA demonstrated on MLPerf with Hopper structure GPUs and TensorRT-LLM. There’s far more to return.
Study extra about MLPerf benchmarks and the technical details of this inference spherical.
[ad_2]
Source link
