


[ad_1]
Dramatic positive aspects in {hardware} efficiency have spawned generative AI, and a wealthy pipeline of concepts for future speedups that can drive machine studying to new heights, Invoice Dally, NVIDIA’s chief scientist and senior vp of analysis, stated at present in a keynote.
Dally described a basket of methods within the works — some already displaying spectacular outcomes — in a chat at Sizzling Chips, an annual occasion for processor and programs architects.
“The progress in AI has been huge, it’s been enabled by {hardware} and it’s nonetheless gated by deep studying {hardware},” stated Dally, one of many world’s foremost pc scientists and former chair of Stanford College’s pc science division.
He confirmed, for instance, how ChatGPT, the big language mannequin (LLM) utilized by hundreds of thousands, may recommend an overview for his discuss. Such capabilities owe their prescience largely to positive aspects from GPUs in AI inference efficiency over the past decade, he stated.
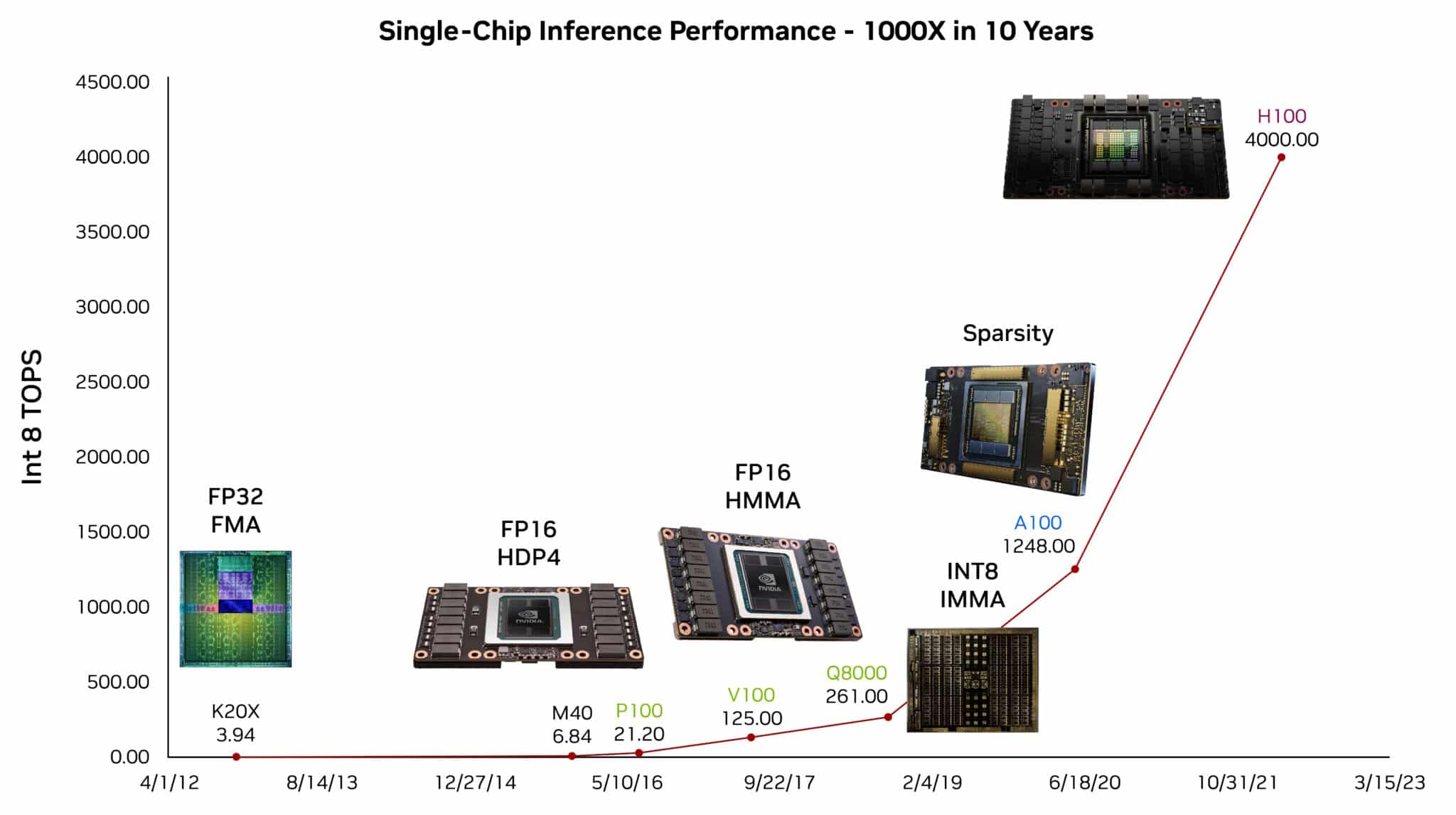
Analysis Delivers 100 TOPS/Watt
Researchers are readying the subsequent wave of advances. Dally described a test chip that demonstrated almost 100 tera operations per watt on an LLM.
The experiment confirmed an energy-efficient solution to additional speed up the transformer models utilized in generative AI. It utilized four-bit arithmetic, one among a number of simplified numeric approaches that promise future positive aspects.

Wanting additional out, Dally mentioned methods to hurry calculations and save power utilizing logarithmic math, an strategy NVIDIA detailed in a 2021 patent.
Tailoring {Hardware} for AI
He explored a half dozen different methods for tailoring {hardware} to particular AI duties, typically by defining new information varieties or operations.
Dally described methods to simplify neural networks, pruning synapses and neurons in an strategy referred to as structural sparsity, first adopted in NVIDIA A100 Tensor Core GPUs.
“We’re not completed with sparsity,” he stated. “We have to do one thing with activations and may have larger sparsity in weights as properly.”
Researchers must design {hardware} and software program in tandem, making cautious choices on the place to spend valuable power, he stated. Reminiscence and communications circuits, for example, want to attenuate information actions.
“It’s a enjoyable time to be a pc engineer as a result of we’re enabling this enormous revolution in AI, and we haven’t even totally realized but how massive a revolution it is going to be,” Dally stated.
Extra Versatile Networks
In a separate discuss, Kevin Deierling, NVIDIA’s vp of networking, described the distinctive flexibility of NVIDIA BlueField DPUs and NVIDIA Spectrum networking switches for allocating sources based mostly on altering community site visitors or consumer guidelines.
The chips’ potential to dynamically shift {hardware} acceleration pipelines in seconds allows load balancing with most throughput and offers core networks a brand new stage of adaptability. That’s particularly helpful for defending in opposition to cybersecurity threats.
“Immediately with generative AI workloads and cybersecurity, every part is dynamic, issues are altering consistently,” Deierling stated. “So we’re transferring to runtime programmability and sources we will change on the fly,”
As well as, NVIDIA and Rice College researchers are creating methods customers can benefit from the runtime flexibility utilizing the favored P4 programming language.
Grace Leads Server CPUs
A chat by Arm on its Neoverse V2 cores included an replace on the efficiency of the NVIDIA Grace CPU Superchip, the primary processor implementing them.
Exams present that, on the identical energy, Grace programs ship as much as 2x extra throughput than present x86 servers throughout quite a lot of CPU workloads. As well as, Arm’s SystemReady Program certifies that Grace programs will run present Arm working programs, containers and purposes with no modification.
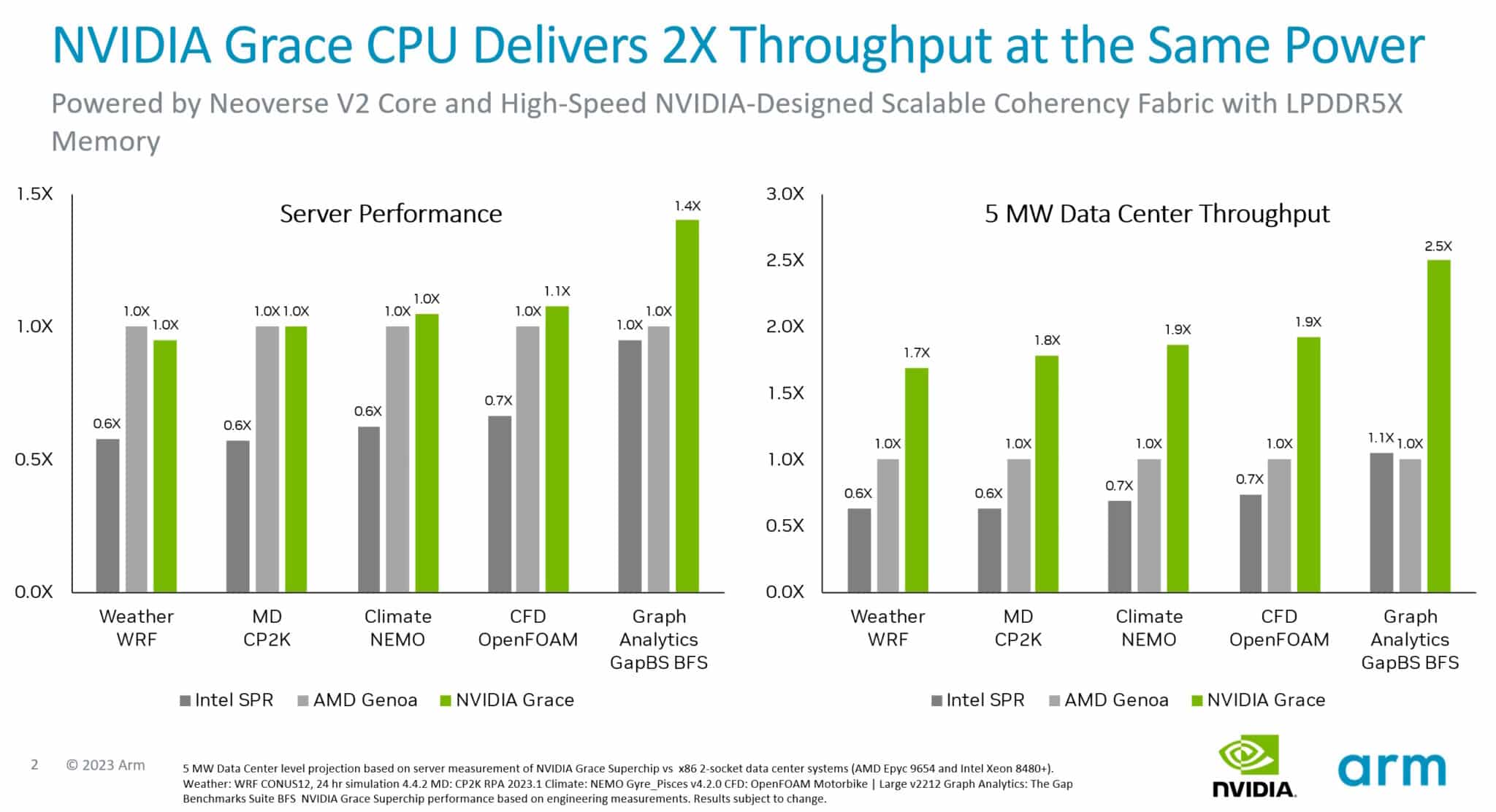
Grace makes use of an ultra-fast material to attach 72 Arm Neoverse V2 cores in a single die, then a model of NVLink connects two of these dies in a package deal, delivering 900 GB/s of bandwidth. It’s the primary information heart CPU to make use of server-class LPDDR5X reminiscence, delivering 50% extra reminiscence bandwidth at related price however one-eighth the ability of typical server reminiscence.
Sizzling Chips kicked off Aug. 27 with a full day of tutorials, together with talks from NVIDIA consultants on AI inference and protocols for chip-to-chip interconnects, and runs by way of at present.
[ad_2]
Source link
