


[ad_1]
The fast development of huge language fashions (LLMs) has considerably impacted varied domains, providing unprecedented capabilities in processing and producing human language. Regardless of their outstanding achievements, the substantial computational prices of coaching these gargantuan fashions have raised monetary and environmental sustainability issues. On this context, exploring Combination of Specialists (MoE) fashions emerges as a pivotal growth to reinforce coaching effectivity with out compromising mannequin efficiency.
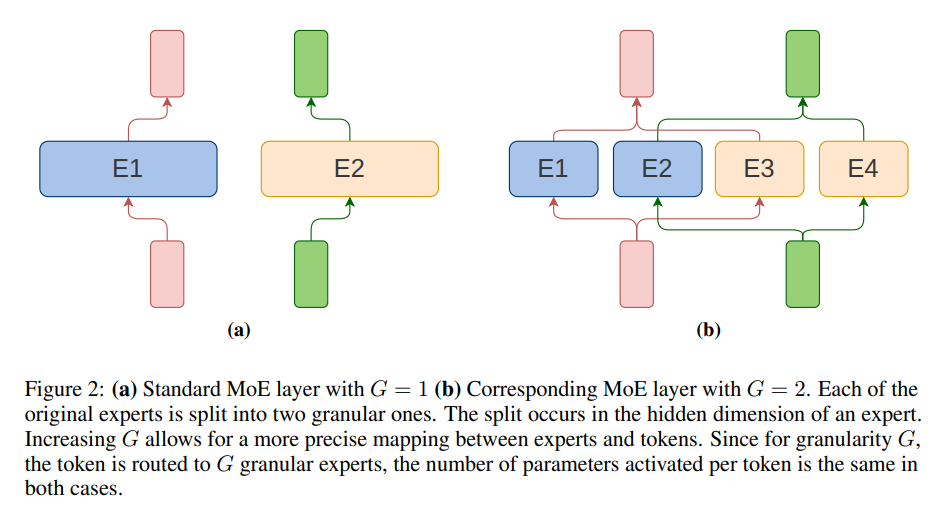
MoE fashions introduce a paradigm shift by using a dynamic allocation of duties to specialised subsets throughout the mannequin, referred to as specialists. This modern strategy optimizes computational assets by activating solely related elements of the mannequin for particular duties. Researchers from the College of Warsaw, IDEAS NCBR, IPPT PAN, TradeLink, and Nomagic explored the scaling properties of MoE fashions. Their research introduces granularity as a important hyperparameter, enabling exact management over the scale of the specialists and thereby refining the mannequin’s computational effectivity.
The analysis delves into formulating new scaling legal guidelines for MoE fashions, contemplating a complete vary of variables, together with mannequin dimension, the variety of coaching tokens, and granularity. This analytical framework supplies insights into optimizing coaching configurations for max effectivity for a given computational funds. The research’s findings problem typical knowledge, notably the follow of equating the scale of MoE specialists with the feed-forward layer dimension, revealing that such configurations are seldom optimum.
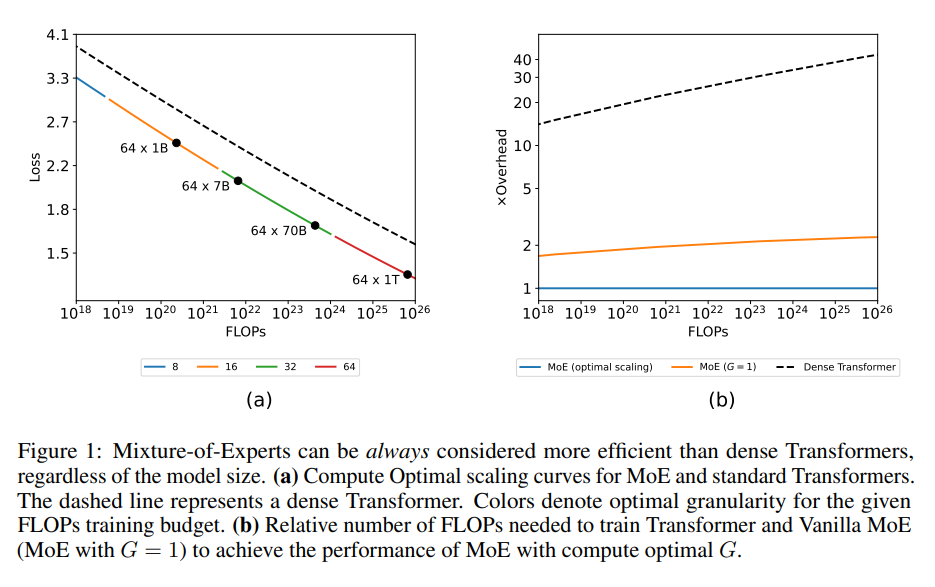
The researchers reveal that MoE fashions, when fine-tuned with applicable granularity settings, persistently outshine dense transformer fashions throughout various computational budgets. This effectivity hole between MoE and thick fashions widens with the rise in mannequin dimension and computational allocation, highlighting the numerous potential of MoE fashions within the evolution of LLM coaching methodologies.
Vital takeaways from this groundbreaking research embrace the next:
- By adjusting this novel hyperparameter, researchers can fine-tune the scale of the specialists inside MoE fashions, considerably enhancing computational effectivity.
- The event of scaling legal guidelines incorporating granularity and different important variables affords a strategic framework for optimizing MoE fashions. This strategy ensures superior efficiency and effectivity in comparison with conventional dense transformer fashions.
- The research supplies proof that matching the scale of MoE specialists with the feed-forward layer dimension is just not optimum, advocating for a extra nuanced strategy to configuring MoE fashions.
- The findings reveal that MoE fashions, when optimally configured, can outperform dense fashions in effectivity and scalability, notably at bigger mannequin sizes and computational budgets. This effectivity benefit underscores MoE fashions’ transformative potential in decreasing the monetary and environmental prices related to coaching LLMs.
In abstract, this analysis marks a major stride towards extra environment friendly and sustainable coaching methodologies for big language fashions. By harnessing the capabilities of MoE fashions and the strategic adjustment of granularity, the research contributes to the theoretical understanding of mannequin scaling. It supplies sensible tips for optimizing computational effectivity in LLM growth. The implications of those findings are profound and promising, shaping the longer term panorama of synthetic intelligence analysis and growth.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and Google News. Be a part of our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our newsletter..
Don’t Overlook to hitch our Telegram Channel
Hey, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m at the moment pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m captivated with know-how and wish to create new merchandise that make a distinction.
[ad_2]
Source link
