


[ad_1]
Delving into the intricacies of synthetic intelligence, significantly inside the dynamic reasoning area, uncovers the pivotal position of Giant Language Fashions (LLMs) in navigating environments that aren’t simply advanced however ever-changing. Whereas efficient in predictable settings, conventional static reasoning fashions falter when confronted with the unpredictability inherent in real-world eventualities equivalent to market fluctuations or strategic video games. This hole underscores the need for fashions that may adapt in actual time and anticipate the strikes of others in a aggressive panorama.
The latest examine spearheaded by Microsoft Analysis Asia and East China Regular College researchers introduces a groundbreaking methodology, “Ok-Stage Reasoning,” that propels LLMs into this dynamic area with unprecedented sophistication. This technique, rooted in sport concept, is a testomony to the collaborative effort bridging academia and business, heralding a brand new period of AI analysis emphasizing adaptability and strategic foresight. By integrating the idea of k-level considering, the place every degree represents a deeper anticipation of rivals’ strikes primarily based on historic knowledge, this strategy empowers LLMs to navigate the complexities of decision-making in an interactive atmosphere.
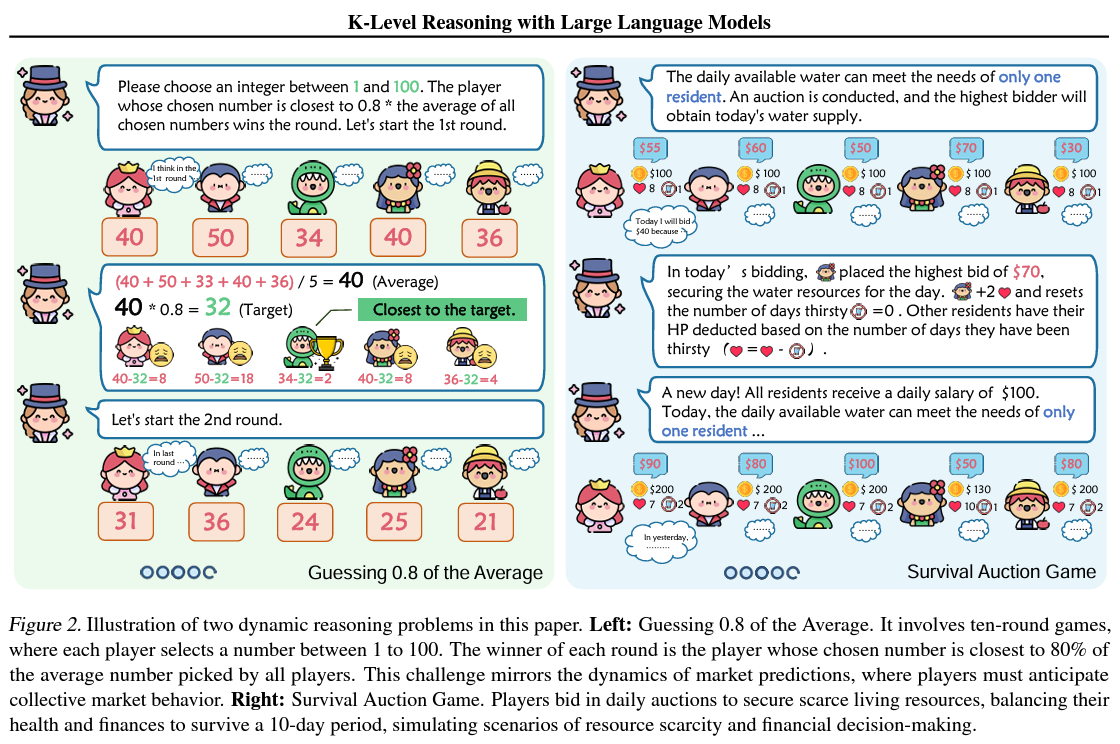
“Ok-Stage Reasoning” is theoretical and backed by in depth empirical proof showcasing its superiority in dynamic reasoning duties. Via meticulously designed pilot challenges, together with the “Guessing 0.8 of the Common” and “Survival Public sale Recreation,” the tactic was examined in opposition to typical reasoning approaches. The outcomes have been telling: within the “Guessing 0.8 of the Common” sport, the Ok-Stage Reasoning strategy achieved a win fee of 0.82 in opposition to direct strategies, a transparent indicator of its strategic depth. Equally, the “Survival Public sale Recreation” not solely outperformed different fashions but in addition demonstrated a outstanding adaptability, with an adaptation index considerably decrease than conventional strategies, indicating a smoother and simpler adjustment to dynamic circumstances.
This analysis marks a major milestone in AI, showcasing the potential of LLMs to transcend static reasoning and thrive in dynamic, unpredictable settings. The collaborative endeavor between Microsoft Analysis Asia and East China Regular College has not solely pushed the boundaries of what’s attainable with LLMs but in addition laid the groundwork for future explorations into AI’s position in strategic decision-making. With its sturdy empirical backing, the “Ok-Stage Reasoning” methodology presents a glimpse right into a future the place AI can adeptly navigate the complexities of the actual world, adapting and evolving within the face of uncertainty.
In conclusion, the appearance of “Ok-Stage Reasoning” signifies a leap ahead within the quest to equip LLMs with the dynamic reasoning capabilities essential for real-world purposes. This analysis enhances the strategic depth of decision-making in interactive environments, paving the best way for adaptable and clever AI techniques and marking a pivotal shift in AI analysis.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and Google News. Be part of our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our newsletter..
Don’t Overlook to affix our Telegram Channel
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a deal with Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical information with sensible purposes. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.
[ad_2]
Source link
