

[ad_1]
The exceptional development of generative AI has sparked fascinating developments in image manufacturing, with strategies like DALL-E, Imagen, and Secure Diffusion creating glorious pictures from textual cues. This achievement may unfold past 2D knowledge. A text-to-image generator could also be used to create high-quality 3D fashions, as demonstrated these days by DreamFusion. Regardless of the generator’s lack of 3D coaching, there may be sufficient knowledge to reconstruct a 3D form. This text illustrates how one might get extra out of a text-to-image generator and get articulated fashions of a number of 3D merchandise varieties.
That’s, as an alternative of making an attempt to create a single 3D asset (DreamFusion), they need to create a statistical mannequin of a whole class of articulated 3D objects (reminiscent of cows, sheep, and horses) that can be utilized to create an animatable 3D asset that can be utilized in AR/VR, gaming, and content material creation from a single picture, whether or not it’s actual or created digitally. They deal with this challenge by coaching a community that may predict an articulated 3D mannequin of an merchandise from a single {photograph} of the factor. To introduce such reconstruction networks, prior efforts have relied on actual knowledge. Nevertheless, they suggest using artificial knowledge produced utilizing a 2D diffusion mannequin, reminiscent of Secure Diffusion.
Researchers from the Visible Geometry Group on the College of Oxford suggest Farm3D, which is an addition to 3D turbines like DreamFusion, RealFusion, and Make-a-video-3D that create a single 3D asset, static or dynamic, by way of test-time optimization, beginning with textual content or a picture, and taking hours. This offers a number of advantages. The 2D image generator, within the first place, has a propensity to generate correct and pristine examples of the thing class, implicitly curating the coaching knowledge and streamlining studying. Additional clarifying understanding is supplied by the 2D generator’s implicit provision of digital views of every given object occasion by distillation. Thirdly, it will increase the strategy’s adaptability by eliminating the requirement to collect (and possibly censor) actual knowledge.
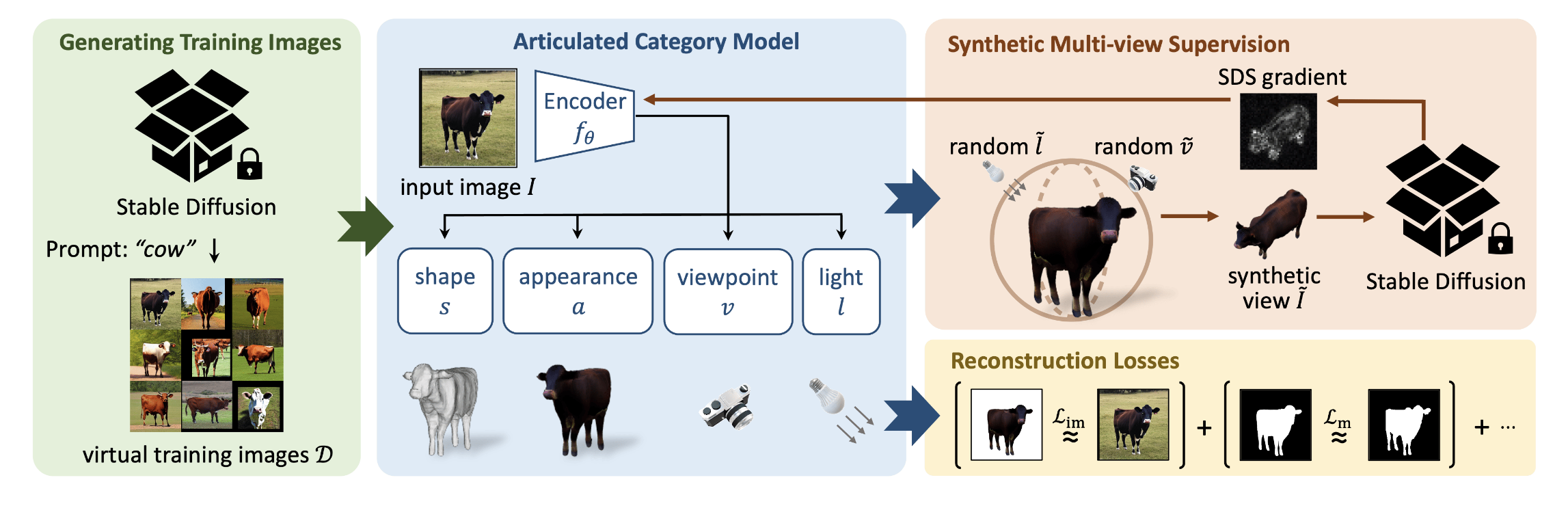
At check time, their community executes reconstruction from a single image in a feed-forward method in a matter of seconds, producing an articulated 3D mannequin that may be manipulated (e.g., animated, relighted) as an alternative of a hard and fast 3D or 4D artefact. Their methodology is appropriate for synthesis and evaluation as a result of the reconstruction community generalizes to precise photos whereas coaching solely on digital enter. Functions might be made to review and preserve animal behaviours. Farm3D relies on two vital technical improvements. To be taught articulated 3D fashions, they first exhibit how Secure Diffusion could also be induced to provide a big coaching set of typically clear photos of an object class utilizing fast engineering.
They exhibit how MagicPony, a cutting-edge method for monocular reconstruction of articulated objects, may be bootstrapped utilizing these photos. Second, they present that, as an alternative of becoming a single radiance area mannequin, the Rating Distillation Sampling (SDS) loss may be prolonged to realize artificial multi-view supervision to coach a photo-geometric autoencoder, of their case MagicPony. To create new synthetic views of the identical object, the photo-geometric autoencoder divides the thing into varied points contributing to picture formation (reminiscent of the thing’s articulated form, look, digital camera viewpoint, and illumination).
To get a gradient replace and a back-propagation to the learnable parameters of the autoencoder, these artificial views are fed into the SDS loss. They supply Farm3D with a qualitative analysis primarily based on its 3D manufacturing and restore capability. They will consider Farm3D quantitatively on analytical duties like semantic key level switch since it’s able to reconstruction along with creation. Despite the fact that the mannequin doesn’t make the most of any actual pictures for coaching and therefore saves time-consuming knowledge gathering and curation, they present equal and even higher efficiency to numerous baselines.
Try the Paper and Project. Don’t neglect to affix our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra. You probably have any questions concerning the above article or if we missed something, be at liberty to electronic mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at the moment pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Expertise(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is obsessed with constructing options round it. He loves to attach with folks and collaborate on fascinating initiatives.
[ad_2]
Source link
