


[ad_1]
Effectivity of Massive Language Fashions (LLMs) is a focus for researchers in AI. A groundbreaking research by Qualcomm AI Analysis introduces a technique often called GPTVQ, which leverages vector quantization (VQ) to boost the size-accuracy trade-off in neural community quantization considerably. This method offers with the challenges of intensive parameter counts in LLMs. These parameters improve computational prices and require fixed information transfers, usually hampered by the fashions’ autoregressive nature.
GPTVQ distinguishes itself by adopting a non-uniform and vector quantization technique, enabling a extra versatile illustration of mannequin weights than conventional strategies. This method updates unquantized weights whereas interleaving column quantization, using the Hessian’s info from the per-layer output reconstruction MSE. The method begins with initializing quantization codebooks. We obtained outcomes that surpassed expectations by utilizing an exceptionally environment friendly data-aware model of the EM algorithm. We have been adopted by codebook updates and additional compression via integer quantization and Singular Worth Decomposition (SVD)-based compression.
The analysis group from Qualcomm AI Analysis carried out in depth experiments to validate the effectiveness of GPTVQ, demonstrating its potential to determine new benchmarks for the dimensions vs. accuracy trade-offs throughout numerous LLMs, together with Llama-v2 and Mistral fashions. Notably, the research showcased that GPTVQ may course of a Llamav2-70B mannequin inside 3 to 11 hours on a single H100, illustrating its practicality for real-world purposes.
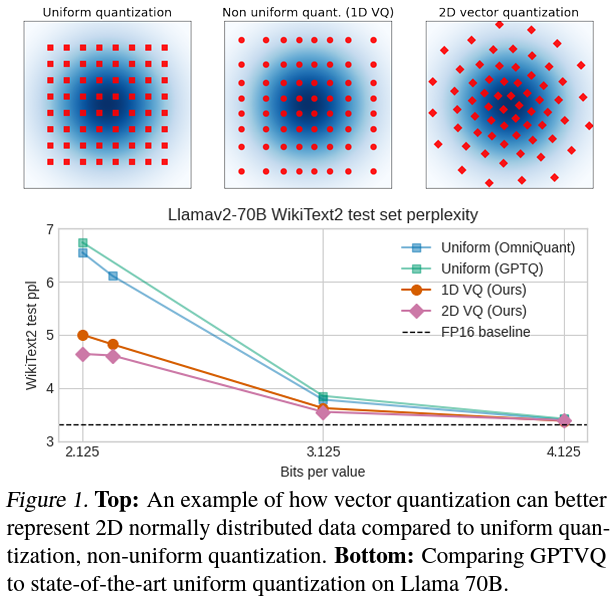
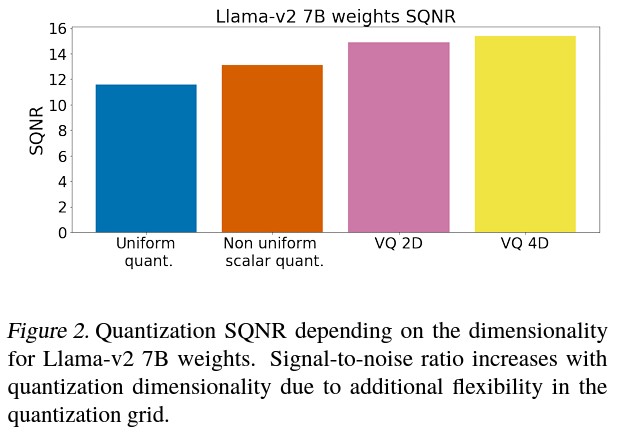
Efficiency evaluations revealed that GPTVQ considerably outperforms current state-of-the-art strategies relating to mannequin measurement and accuracy trade-offs. As an example, making use of GPTVQ to Llamav2-7B fashions resulted in a outstanding enchancment, with the quantization Sign-to-Quantization Noise Ratio (SQNR) growing because the dimensionality of the quantization grid expanded. This demonstrates the tactic’s superior potential to keep up excessive ranges of accuracy even when considerably lowering the mannequin measurement. Particularly, GPTVQ decreased perplexity to five.93 on Llamav2-7B fashions underneath sure quantization settings, highlighting its efficacy.
Furthermore, the tactic’s effectivity extends past computational financial savings, together with enhanced latency advantages. The analysis illustrated that vector quantized LLMs may enhance latency on a cellular CPU in comparison with a conventional 4-bit integer format. This discovering means that GPTVQ reduces the computational and storage calls for of deploying LLMs and affords potential for real-time purposes with important latency.
This research by Qualcomm AI Analysis marks a big development within the quest for extra environment friendly and scalable LLMs. GPTVQ opens new avenues for deploying superior AI fashions throughout numerous platforms and purposes by addressing the twin challenges of sustaining mannequin accuracy whereas lowering the dimensions and computational prices. Its success in leveraging vector quantization presents a promising route for future analysis within the discipline, probably resulting in broader accessibility and utility of LLMs in areas starting from pure language processing to real-time decision-making techniques.
In abstract, the introduction of GPTVQ represents a leap ahead in optimizing LLMs, providing a viable answer to the urgent challenges of mannequin effectivity. As AI continues integrating into numerous facets of know-how and day by day life, improvements like GPTVQ are pivotal in guaranteeing these highly effective instruments stay accessible and efficient, paving the best way for the subsequent era of AI purposes.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and Google News. Be part of our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our newsletter..
Don’t Overlook to hitch our Telegram Channel
You may additionally like our FREE AI Courses….
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a deal with Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical information with sensible purposes. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.
[ad_2]
Source link
