


[ad_1]
Language fashions typically want extra publicity to fruitful errors throughout coaching, hindering their skill to anticipate penalties past the subsequent token. LMs should enhance their capability for complicated decision-making, planning, and reasoning. Transformer-based fashions wrestle with planning as a consequence of error snowballing and problem in lookahead duties. Whereas some efforts have built-in symbolic search algorithms to deal with these points, they merely complement language fashions throughout inference. But, enabling language fashions to seek for coaching might facilitate self-improvement, fostering extra adaptable methods to sort out challenges like error compounding and look-ahead duties.
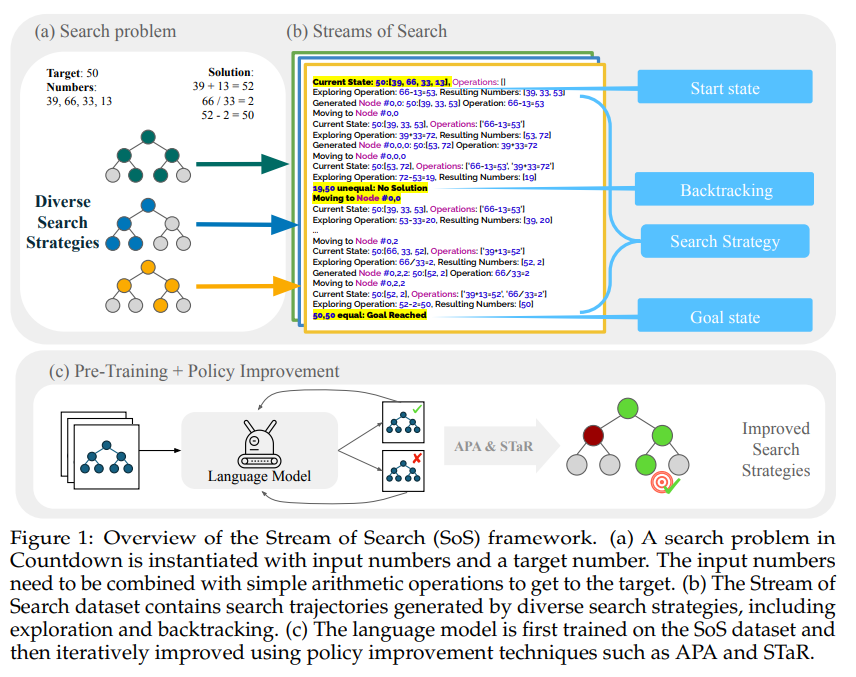
Researchers from Stanford College, MIT, and Harvey Mudd have devised a way to show language fashions how you can search and backtrack by representing the search course of as a serialized string, Stream of Search (SoS). They proposed a unified language for search, demonstrated via the sport of Countdown. Pretraining a transformer-based language mannequin on streams of search elevated accuracy by 25%, whereas additional finetuning with coverage enchancment strategies led to fixing 36% of beforehand unsolved issues. This showcases that language fashions can study to unravel issues by way of search, self-improve, and uncover new methods autonomously.
Latest research combine language fashions into search and planning programs, using them to generate and assess potential actions or states. These strategies make the most of symbolic search algorithms like BFS or DFS for exploration technique. Nonetheless, LMs primarily serve for inference, needing improved reasoning skill. Conversely, in-context demonstrations illustrate search procedures utilizing language, enabling the LM to conduct tree searches accordingly. But, these strategies are restricted by the demonstrated procedures. Course of supervision includes coaching an exterior verifier mannequin to offer detailed suggestions for LM coaching, outperforming consequence supervision however requiring in depth labeled information.
The issue area is a Markov Resolution Course of (MDP), with states, actions, transition, and reward features defining the search course of. The search includes exploring a tree from the preliminary to the purpose state via sequences of states and actions. A vocabulary of primitive operations guides totally different search algorithms, together with present state, purpose state, state queue, state enlargement, exploration alternative, pruning, backtracking, purpose examine, and heuristic. For the “Countdown” job, an artificial dataset with various search methods is created, measuring accuracy based mostly on the mannequin’s skill to generate right answer trajectories and assessing alignment between totally different search methods via correctness and state overlap metrics.
Researchers discover the effectiveness of coaching LMs on optimum options or suboptimal search trajectories for fixing Countdown issues. Utilizing a GPT-Neo mannequin, researchers prepare on datasets representing each eventualities. Outcomes point out that fashions educated on suboptimal search trajectories outperform these educated on optimum options. Furthermore, they examine self-improvement methods utilizing reinforcement studying (RL), equivalent to skilled iteration and Benefit-Induced Coverage Alignment (APA). These methods improve the mannequin’s skill to unravel beforehand unsolved and tough issues, demonstrating improved effectivity and accuracy in navigating the search area. Moreover, insights into the fashions’ search methods reveal versatile utilization of assorted strategies, probably resulting in the invention of heuristics.
In conclusion, the SoS framework introduces a way for language fashions to study problem-solving via simulated search processes in language. Addressing criticisms of language fashions for planning, SoS permits fashions to backtrack and discover various paths, fostering adaptability and overcoming errors. In contrast to symbolic search strategies, SoS fashions study inside “world fashions” for search, probably enhancing generalization. Whereas the research targeted on the Countdown sport, SoS reveals promise for tackling complicated real-world duties. Future analysis might improve SoS by incorporating formalizable operations and exploring area transferability. Finally, SoS demonstrates the potential for LMs to excel in problem-solving via various search methods and iterative refinement.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our newsletter..
Don’t Overlook to hitch our 40k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is enthusiastic about making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.
[ad_2]
Source link
