

[ad_1]
A information graph (KG) is a graph-based database that shops info as nodes and edges. However, a multilayer perceptron (MLP) is a kind of neural community utilized in machine studying. MLPs are composed of interconnected nodes organized in a number of layers. Every node obtains enter from the earlier layer and sends output to the following layer.
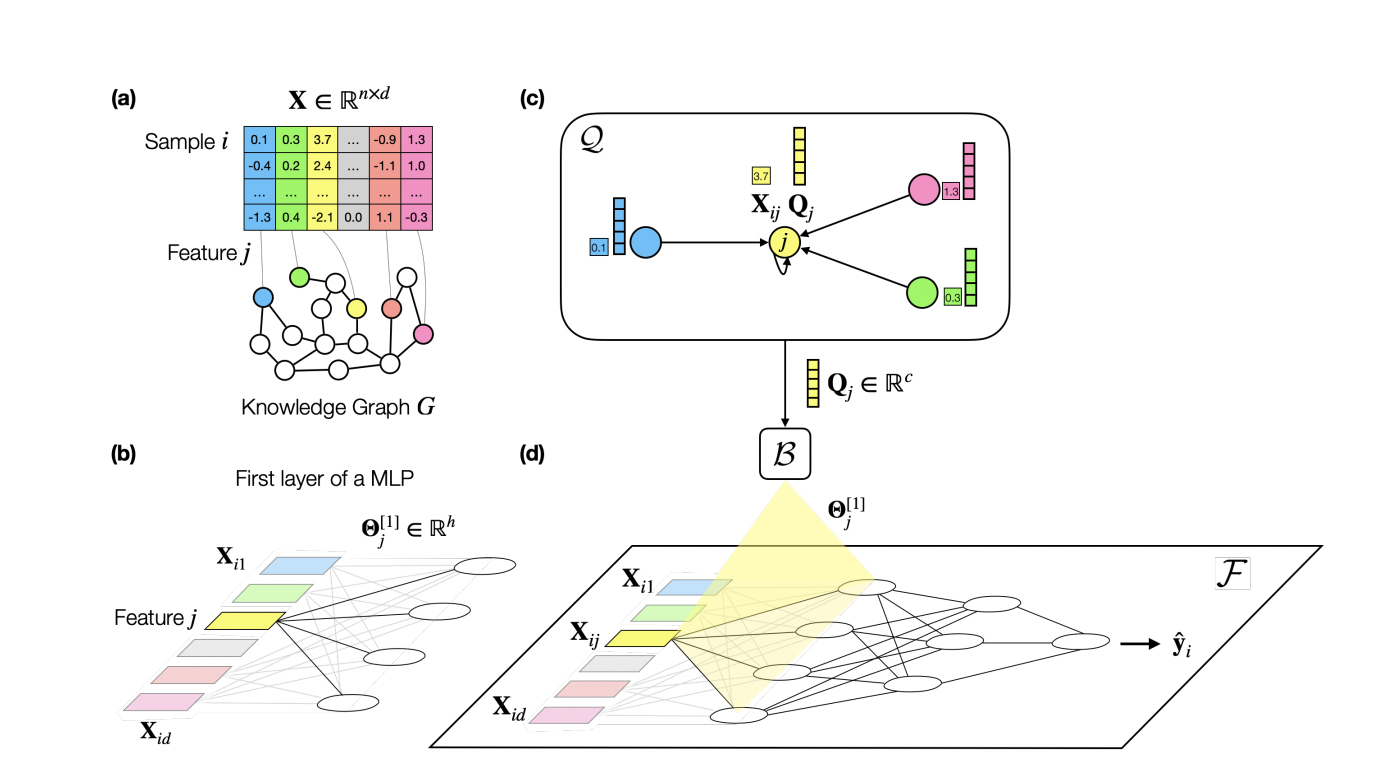
Researchers from Stanford College have launched a brand new machine studying mannequin known as PLATO, which leverages a KG to supply auxiliary area info. PLATO regularizes an MLP by introducing an inductive bias that ensures comparable nodes within the KG have equal weight vectors within the MLP’s first layer. This technique addresses the problem of machine studying fashions needing assist with tabular datasets that includes many dimensions in comparison with samples.
PLATO addresses the underexplored situation of tabular datasets with high-dimensional options and restricted samples, contrasting with current tabular deep-learning strategies designed for settings with extra items than options. It distinguishes itself from different deep tabular fashions, corresponding to NODE and tabular transformers, and conventional approaches like PCA and LASSO by introducing a KG for regularization. Not like graph regularization strategies, PLATO incorporates characteristic and non-feature nodes within the KG. It infers weights for an MLP mannequin, using the graph as a previous for predictions on a definite tabular dataset.
Machine studying fashions usually excel in data-rich environments however need assistance with tabular datasets the place the variety of options significantly surpasses the variety of samples. This discrepancy is particularly prevalent in scientific datasets, limiting mannequin efficiency. Present tabular deep studying approaches primarily give attention to situations with extra examples than options, whereas conventional statistical strategies dominate within the low-data regime with extra options than samples. Addressing this, PLATO, a framework using an auxiliary KG to regularize an MLP, permits deep studying for tabular information with options > samples and achieves superior efficiency on datasets with high-dimensional options and restricted fashions.
Using an auxiliary KG, PLATO associates every enter characteristic with a KG node and infers weight vectors for the primary layer of an MLP primarily based on node similarity. The method employs a number of rounds of message passing, refining characteristic embeddings. In an ablation examine, PLATO demonstrates constant efficiency throughout shallow node embedding strategies (TransE, DistMult, ComplEx) within the KG. This revolutionary technique provides potential enhancements for deep studying fashions in data-scarce tabular settings.
PLATO, a technique for tabular information with high-dimensional options and restricted samples, surpasses 13 cutting-edge baselines by as much as 10.19% throughout six datasets. Efficiency analysis entails a random search with 500 configurations per mannequin, reporting the imply and normal deviation of Pearson correlation between predicted and precise values. The outcomes affirm PLATO’s effectiveness, leveraging an auxiliary KG to attain sturdy efficiency within the difficult low-data regime. Comparative evaluation in opposition to various baselines underscores PLATO’s superiority, establishing its efficacy in enhancing tabular dataset predictions.

In conclusion, the analysis carried out might be summarized in under factors:
- PLATO is a deep-learning framework for tabular information.
- Every enter characteristic resembles a node in an auxiliary KG.
- PLATO regulates an MLP and achieves sturdy efficiency on tabular information with high-dimensional options and restricted samples.
- The framework infers weight vectors primarily based on KG node similarity, capturing the inductive bias that comparable enter options ought to share comparable weight vectors.
- PLATO outperforms 13 baselines by as much as 10.19% on six datasets.
- Using auxiliary KGs is proven to enhance efficiency in low-data regimes.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to affix our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
Good day, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m presently pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m captivated with know-how and wish to create new merchandise that make a distinction.
[ad_2]
Source link
