


[ad_1]
Find out how to facilitate spatial information of fashions is a serious analysis difficulty in vision-language studying. This dilemma results in two required capabilities: referencing and grounding. Whereas grounding requires the mannequin to localize the area in step with the supplied semantic description, referring asks that the mannequin totally perceive the semantics of particular equipped areas. In essence, aligning geographical info and semantics is the information wanted for each referencing and grounding. Regardless of this, referencing and grounding are sometimes taught individually in present texts. People, however, can easily mix referring/grounding capacities with on a regular basis dialogue and Reasoning, and so they can study from one exercise and generalize the shared information to the opposite work with out issue.
On this analysis, they examine three key points in mild of the aforementioned disparity. (i) How would possibly referencing and grounding be mixed right into a single framework, and the way will they complement each other? (ii) How do you depict the various areas individuals usually use to consult with issues, comparable to factors, bins, scribbles, and freeform shapes? (iii) How can referencing and grounding, important for sensible functions, turn out to be open-vocabulary, instruction-following, and strong? Researchers from Columbia College and Apple AI/ML current Ferret, a brand-new refer-and-ground Multimodal Massive Language Mannequin (MLLM), to handle these three points. They first selected MLLM as Ferret’s basis due to its robust vision-language international understanding capability. As proven in Determine 1, Ferret initially encodes the coordinates of areas in plain language numerical type to unify referencing and grounding.
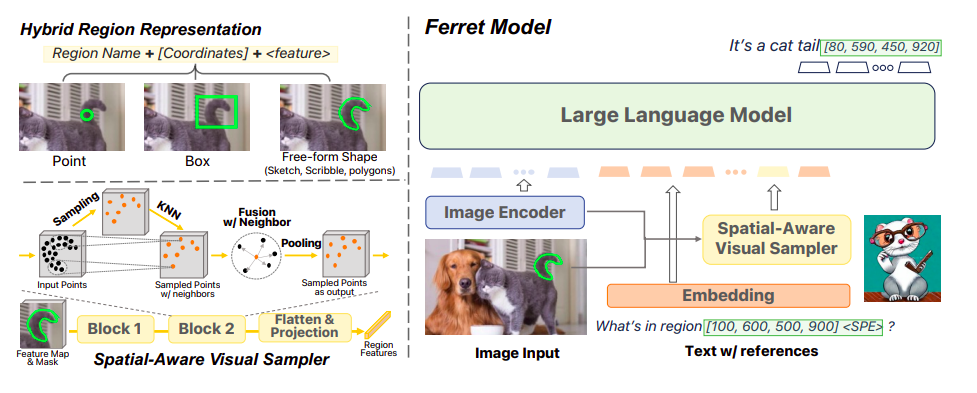
Determine 3: A basic image of the structure for the urged Ferret mannequin. The urged hybrid area illustration and spatially conscious visible sampler are proven on the left. The general mannequin structure (proper). The picture encoder is the one parameter that can’t be educated.
Nevertheless, it’s impractical to characterize a wide range of regional varieties, comparable to strokes, scribbles, or intricate polygons, with a single level or a field of coordinates. These varieties are vital for extra correct and all-encompassing human-model interplay. To handle this difficulty, in addition they recommend a spatial-aware visible sampler to amass the optical traits for areas in any type, accounting for the variable sparsity in these shapes. The visible areas within the enter are then represented in Ferret utilizing a hybrid area illustration made up of discrete coordinates and steady visible traits. With the methods talked about above, Ferret can deal with enter that mixes free-form textual content and referenced areas, and it could possibly floor the desired gadgets in its output by robotically creating the coordinates for every groundable object and textual content.
So far as they know, Ferret is the primary software to deal with inputs from MLLMs with free-formed areas. They collect GRIT, a Floor-and-Refer Instruction-Tuning dataset of 1.1M samples, to create the refer-and-ground capabilities in Ferret open-vocabulary, instruction-following, and resilience. GRIT has varied layers of spatial information, together with descriptions of areas, connections, objects, and sophisticated Reasoning. It comprises knowledge that mixes location and textual content in each the enter and the output, in addition to location-in textout (referring) and text-in location-out (grounding). With the assistance of fastidiously crafted templates, many of the dataset is remodeled from present imaginative and prescient(-language) duties like object identification and phrase grounding to instruction-following.
To help in coaching an instruction-following, open-vocabulary refer-and-ground generalist, 34K refer-and-ground instruction-tuning chats are additionally gathered utilizing ChatGPT/GPT-4. In addition they do spatially conscious damaging knowledge mining, which reinforces mannequin robustness. The ferret possesses excessive open-vocabulary spatial consciousness and localization skill. It performs higher when measured towards conventional referencing and grounding actions. Greater than that, they assume refer-and-ground capabilities must be integrated into each day human discussions, for instance, when people consult with one thing unfamiliar and inquire about its perform. To evaluate this new ability, they current the Ferret-Bench, which covers three new varieties of duties: Referring Description, Referring Reasoning, and Grounding in Dialog. They evaluate Ferret to the best MLLMs already in use and discover that it could possibly outperform them by a median of 20.4%. Ferret additionally has the exceptional skill to scale back object hallucinations.
They’ve made three totally different contributions total. (i) They recommend Ferret, which permits fine-grained and open-vocabulary reference and grounding in MLLM. Ferret employs a hybrid area illustration outfitted with a novel spatial-aware visible sampler. (ii) they create GRIT, a big ground-and-refer instruction tuning dataset for mannequin coaching. It additionally consists of further spatial damaging examples to strengthen the mannequin’s resilience. To judge duties concurrently needing referring/grounding, semantics, information, and Reasoning, they create the Ferret-Bench (iii). Their mannequin performs higher than others in varied actions and has much less object hallucination.
Take a look at the Paper and Github. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t neglect to hitch our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
We’re additionally on WhatsApp. Join our AI Channel on Whatsapp..
Aneesh Tickoo is a consulting intern at MarktechPost. He’s presently pursuing his undergraduate diploma in Knowledge Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is captivated with constructing options round it. He loves to attach with individuals and collaborate on attention-grabbing initiatives.
[ad_2]
Source link
