


[ad_1]
By producing high-quality and different outcomes, text-to-image diffusion fashions educated on large-scale knowledge have significantly dominated generative duties. In a just lately developed pattern, typical image-to-image transformation duties like picture alteration, enhancement, or super-resolution are guided by the generated outcomes with exterior picture circumstances utilizing diffusion earlier than pre-trained text-to-image generative fashions. The diffusion prior launched by pre-trained fashions is confirmed to considerably improve the visible high quality of the conditional image manufacturing outputs amongst varied transformation procedures. Diffusion fashions, alternatively, significantly depend on an iterative refining course of that regularly necessitates many iterations, which may take time to finish successfully.
Their dependency on the variety of repetitions grows additional for high-resolution image synthesis. As an illustration, even with subtle sampling methods, wonderful visible high quality in state-of-the-art text-to-image latent diffusion fashions usually wants 20–200 pattern steps. The sluggish sampling interval severely restricts the above-mentioned conditional diffusion fashions’ sensible applicability. Most up-to-date makes an attempt to hurry up diffusion sampling use distillation methods. These methods significantly pace up sampling, ending it in 4–8 steps whereas little affecting generative efficiency. Latest analysis demonstrates that these methods may be used to condense large-scale text-to-image diffusion fashions which have already been educated.
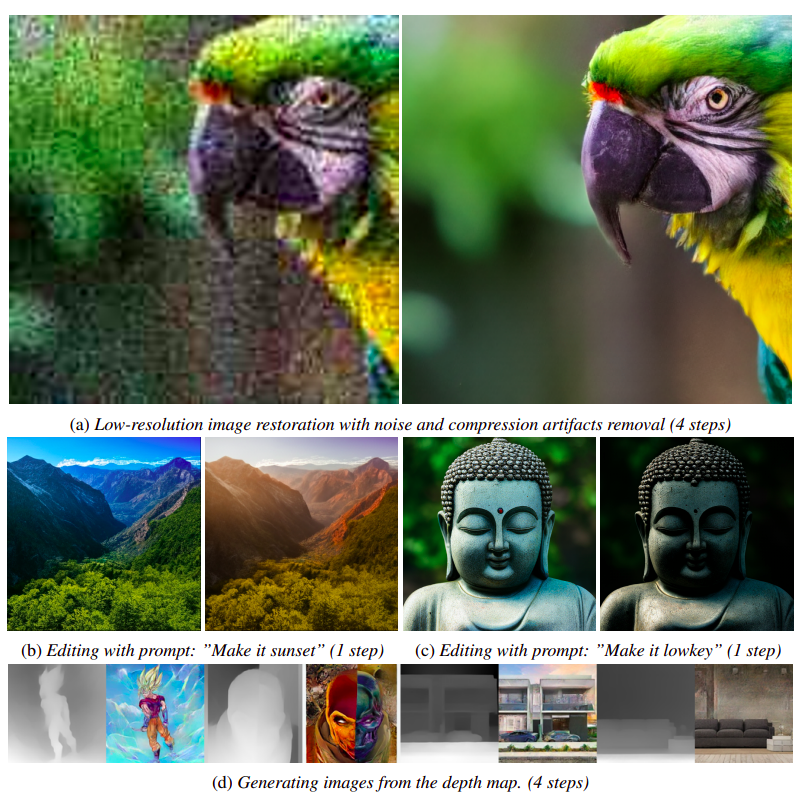
They supply the output of our distilled mannequin in quite a lot of conditional duties, illustrating the capability of our instructed method to duplicate diffusion priors in a condensed sampling interval.
Based mostly on these distillation strategies, a two-stage distillation course of—both distillation-first or conditional finetuning-first—will be utilized to distil conditional diffusion fashions. When given the identical sampling interval, these two methods present outcomes which might be sometimes superior to these of the undistilled conditional diffusion mannequin. Nonetheless, they’ve differing advantages relating to cross-task flexibility and studying problem. On this work, they current a contemporary distillation methodology for extracting a conditional diffusion mannequin from an unconditional diffusion mannequin that has already been educated. Their method encompasses a single stage, starting with the unconditional pretraining and ending with the distilled conditional diffusion mannequin, versus the standard two-stage distillation method.
Determine 1 illustrates how their distilled mannequin can forecast high-quality ends in simply one-fourth of the sampling steps by taking cues from the given visible settings. Their method is extra sensible since this streamlined studying eliminates the necessity for the unique text-to-image knowledge, which was needed in earlier distillation processes. In addition they keep away from compromising the diffusion prior within the pre-trained mannequin, a typical mistake when utilizing the finetuning-first methodology in its first stage. When given the identical pattern time, in depth experimental knowledge exhibit that their distilled mannequin performs higher than earlier distillation methods in each visible high quality and quantitative efficiency.
A area that wants additional analysis is parameter-efficient distillation methods for conditional technology. They present that their method gives a novel distillation mechanism that’s parameter-efficient. By including a couple of extra learnable parameters, it may possibly convert and pace up an unconditional diffusion mannequin for conditional duties. Their formulation, particularly, allows integration with a number of already-in-use parameter-efficient tuning methods, corresponding to T2I-Adapter and ControlNet. Utilizing each the newly added learnable parameters of the conditional adaptor and the frozen parameters of the unique diffusion mannequin, their distillation method learns to breed diffusion priors for dependent duties with minimal iterative revisions. This new paradigm has significantly elevated the usefulness of a number of conditional duties.
Try the Paper. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t overlook to hitch our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
We’re additionally on WhatsApp. Join our AI Channel on Whatsapp..
Aneesh Tickoo is a consulting intern at MarktechPost. He’s presently pursuing his undergraduate diploma in Knowledge Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on tasks aimed toward harnessing the facility of machine studying. His analysis curiosity is picture processing and is enthusiastic about constructing options round it. He loves to attach with folks and collaborate on fascinating tasks.
[ad_2]
Source link
