


[ad_1]
People are all the time interacting with their environment. They transfer a couple of area, contact issues, sit on chairs, or sleep on beds. These interactions element how the scene is ready up and the place the objects are. A mime is a performer who makes use of their comprehension of such relationships to create a wealthy, imaginative, 3D surroundings with nothing greater than their physique actions. Can they educate a pc to imitate human actions and make the suitable 3D scene? Quite a few fields, together with structure, gaming, digital actuality, and the synthesis of artificial information, would possibly profit from this method. For example, there are substantial datasets of 3D human movement, comparable to AMASS, however these datasets seldom embody particulars on the 3D setting during which they had been collected.
May they create plausible 3D sceneries for all of the motions utilizing AMASS? If that’s the case, they may make coaching information with real looking human-scene interplay utilizing AMASS. They developed a novel method known as MIME (Mining Interplay and Motion to deduce 3D Environments), which creates plausible inside 3D scenes based mostly on 3D human movement to answer such inquiries. What makes it doable? The elemental assumptions are as follows: (1) Human movement throughout area denotes the absence of things, basically defining areas of the image devoid of furnishings. Moreover, this limits the sort and placement of 3D objects when in contact with the scene; for example, a sitting individual should be seated on a chair, couch, mattress, and so forth.
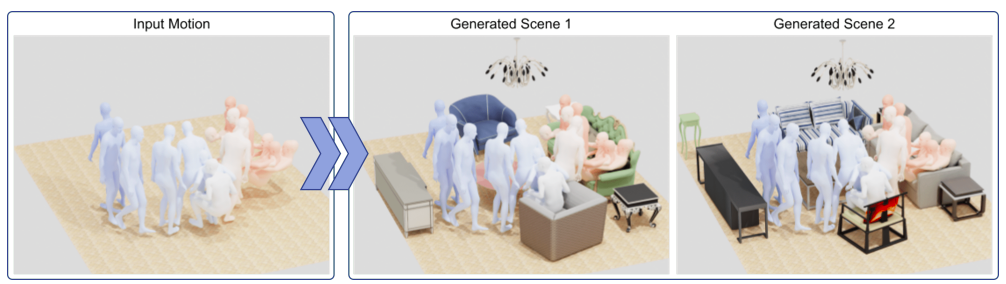
Researchers from the Max Planck Institute for Clever Methods in Germany and Adobe created MIME, a transformer-based auto-regressive 3D scene technology method, to offer these intuitions some tangible kind. Given an empty ground plan and a human movement sequence, MIME predicts the furnishings that can come into contact with the human. Moreover, it foresees plausible objects that don’t come into contact with folks however slot in with different objects and cling to the free-space restrictions introduced on by the motions of individuals. They partition the movement into contact and non-contact snippets to situation the 3D scene creation for human movement. They estimate potential contact poses utilizing POSA. The non-contact postures undertaking the foot vertices onto the bottom aircraft to determine the room’s free area, which they file as 2D ground maps.
The contact vertices predicted by POSA create 3D bounding packing containers that replicate the contact postures and related 3D human physique fashions. The objects that fulfill the contact and free-space standards are anticipated autoregressively use this information as enter to the transformer; see Fig. 1. They expanded the large-scale artificial scene dataset 3D-FRONT to create a brand new dataset named 3D-FRONT HUMAN to coach MIME. They mechanically add folks to the 3D situations, together with non-contact folks (a collection of strolling motions and folks standing) and phone folks (folks sitting, touching, and mendacity). To do that, they use static contact poses from RenderPeople scans and movement sequences from AMASS.
MIME creates a sensible 3D scene format for the enter movement at inference time, represented as 3D bounding packing containers. They select 3D fashions from the 3D-FUTURE assortment based mostly on this association; then, they fine-tune their 3D placement based mostly on geometric restrictions between the human positions and the scene. Their technique produces a 3D set that helps human contact and movement whereas putting convincing objects in free area, not like pure 3D scene creation methods like ATISS. Their strategy permits the event of things not in touch with the individual, anticipating the entire scene as a substitute of particular person objects, in distinction to Pose2Room, a latest pose-conditioned generative mannequin. They present that their strategy works with none changes on real movement sequences which have been recorded, like PROX-D.
In conclusion, they contribute the next:
• A brand-new motion-conditioned generative mannequin for 3D room scenes that auto-regressively creates issues that come into contact with folks whereas avoiding occupying motion-defined vacant area.
• A brand-new 3D scene dataset made up of interacting folks and folks in free area was created by filling 3D FRONT with movement information from AMASS and static contact/standing poses from RenderPeople.
The code is out there on GitHub together with a video demo. In addition they have a video clarification of their strategy.
Verify Out The Paper, Github, and Project. Don’t overlook to affix our 24k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra. When you have any questions concerning the above article or if we missed something, be happy to e-mail us at Asif@marktechpost.com
Featured Instruments From AI Tools Club
🚀 Check Out 100’s AI Tools in AI Tools Club
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at present pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Expertise(IIT), Bhilai. He spends most of his time engaged on tasks aimed toward harnessing the facility of machine studying. His analysis curiosity is picture processing and is enthusiastic about constructing options round it. He loves to attach with folks and collaborate on fascinating tasks.
[ad_2]
Source link
