


[ad_1]
Transformers initially supposed for language modeling have recently been investigated as a doable structure for vision-related duties. With state-of-the-art efficiency in purposes together with object identification, image classification, and video classification, Imaginative and prescient Transformers have demonstrated wonderful accuracy throughout quite a lot of visible recognition points. The excessive processing price of imaginative and prescient Transformers is one in all their primary disadvantages. Imaginative and prescient Transformers generally demand orders of magnitude extra processing than customary convolutional networks (CNNs), as much as a whole bunch of GFlops per image. The huge quantity of knowledge concerned in video processing additional will increase these bills. The potential of this in any other case attention-grabbing expertise is hindered by the excessive computing necessities that stop imaginative and prescient Transformers from getting used on units with little assets or that require low latency.
One of many first methods to leverage the temporal redundancy between succeeding inputs to decrease the price of imaginative and prescient Transformers when used with video knowledge is offered on this work by researchers from the College of Wisconsin–Madison. Consider a imaginative and prescient Transformer that’s utilized to a video sequence frame-by-frame or clip-by-clip. This Transformer is perhaps an easy frame-wise mannequin (similar to an object detector) or a transitional stage in a spatiotemporal mannequin (such because the preliminary factorized mannequin). They view Transformers as being utilized to a number of completely different inputs (frames or clips) throughout time, versus language processing, the place one Transformer enter represents a full sequence. Pure motion pictures have a excessive diploma of temporal redundancy and little variations between frames. Deep networks, similar to Transformers, are continuously calculated “from scratch” on every body regardless of this.
This methodology is inefficient because it throws away any probably helpful knowledge from earlier conclusions. Their primary perception is that they could make higher use of redundant sequences by recycling intermediate calculations from earlier time steps. Clever inference. The inference price for imaginative and prescient Transformers (and deep networks generally) is usually set by the design. The assets which can be available, nevertheless, may change over time in real-world purposes (as an illustration, due to competing processes or adjustments within the energy provide). In consequence, fashions that permit for real-time modification of computational price are required. Adaptivity is among the primary design targets on this examine, and the strategy is created to offer real-time management over the compute price. For an illustration of how they alter the computed finances throughout a movie, see Determine 1 (decrease part).
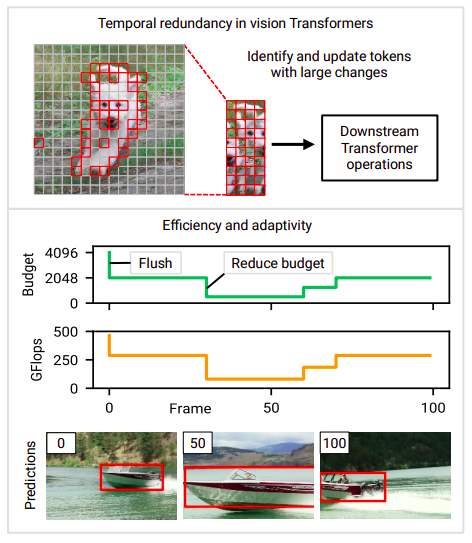
Earlier research have appeared on the CNNs’ temporal redundancy and adaptivity. Nonetheless, as a result of to important architectural variations between Transformers and CNNs, these approaches are usually incompatible with the imaginative and prescient of Transformers. Transformers, particularly, introduces a novel primitive—self-attention—which deviates from a number of CNN-based methodologies. Imaginative and prescient Transformers present a terrific risk regardless of this impediment. It’s difficult to switch sparsity positive aspects in CNNs—particularly, the sparsity acquired by bearing in mind temporal redundancy—into tangible speedups. To do that, both giant constraints have to be positioned on the sparsity construction, or particular compute kernels have to be used. In distinction, it’s less complicated to switch sparsity into shorter runtime utilizing standard operators due to the character of Transformer operations, which is centered on manipulating token vectors. Transformers with occasions.
To be able to facilitate efficient, adaptive inference, they recommend Eventful Transformers, a novel form of Transformer that makes use of the temporal redundancy between inputs. The phrase “Eventful” was coined to explain sensors known as occasion cameras, which create sparse outputs in response to scene adjustments. Eventful Transformers selectively replace the token representations and self-attention maps on every time step as a way to monitor token-level adjustments over time. Gating modules are blocks in an Eventful Transformer that permit for runtime management of the amount of up to date tokens. Their strategy works with quite a lot of video processing purposes and could also be used to pre-built fashions (usually with out retraining). Their analysis reveals that Eventful Transformers, created from present state-of-the-art fashions, significantly decrease computing prices whereas principally sustaining the accuracy of the unique mannequin.
Their supply code, which accommodates PyTorch modules for creating Eventful Transformers, is made accessible to the general public. Limitations Wisionlab’s venture web page is positioned at wisionlab.com/venture/eventful-transformers. On the CPU and GPU, they present speedups in wall time. Their strategy, primarily based on customary PyTorch operators, is probably not one of the best from a technical perspective. They’re positive that the speedup ratios is perhaps additional elevated with extra work to lower overhead (similar to constructing a fused CUDA kernel for his or her gating logic). Moreover, their strategy ends in sure unavoidable reminiscence overheads. Unsurprisingly, protecting sure tensors in reminiscence is important for reusing computation from earlier time steps.
Take a look at the Paper. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t overlook to hitch our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at present pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Expertise(IIT), Bhilai. He spends most of his time engaged on initiatives aimed toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is obsessed with constructing options round it. He loves to attach with individuals and collaborate on attention-grabbing initiatives.
[ad_2]
Source link
