

[ad_1]
Current achievements in supervised duties of deep studying might be attributed to the provision of enormous quantities of labeled coaching information. But it takes a whole lot of effort and cash to gather correct labels. In lots of sensible contexts, solely a small fraction of the coaching information have labels hooked up. Semi-supervised studying (SSL) goals to spice up mannequin efficiency utilizing labeled and unlabeled enter. Many efficient SSL approaches, when utilized to deep studying, undertake unsupervised consistency regularisation to make use of unlabeled information.
State-of-the-art consistency-based algorithms sometimes introduce a number of configurable hyper-parameters, regardless that they attain glorious efficiency. For optimum algorithm efficiency, it’s common apply to tune these hyper-parameters to optimum values. Sadly, hyper-parameter looking is commonly unreliable in lots of real-world SSL eventualities, equivalent to medical picture processing, hyper-spectral picture classification, community visitors recognition, and doc recognition. It’s because the annotated information are scarce, resulting in excessive variance when cross-validation is adopted. Having algorithm efficiency delicate to hyper-parameter values makes this difficulty much more urgent. Furthermore, the computational price could develop into unmanageable for cutting-edge deep studying algorithms because the search area grows exponentially in regards to the variety of hyper-parameters.
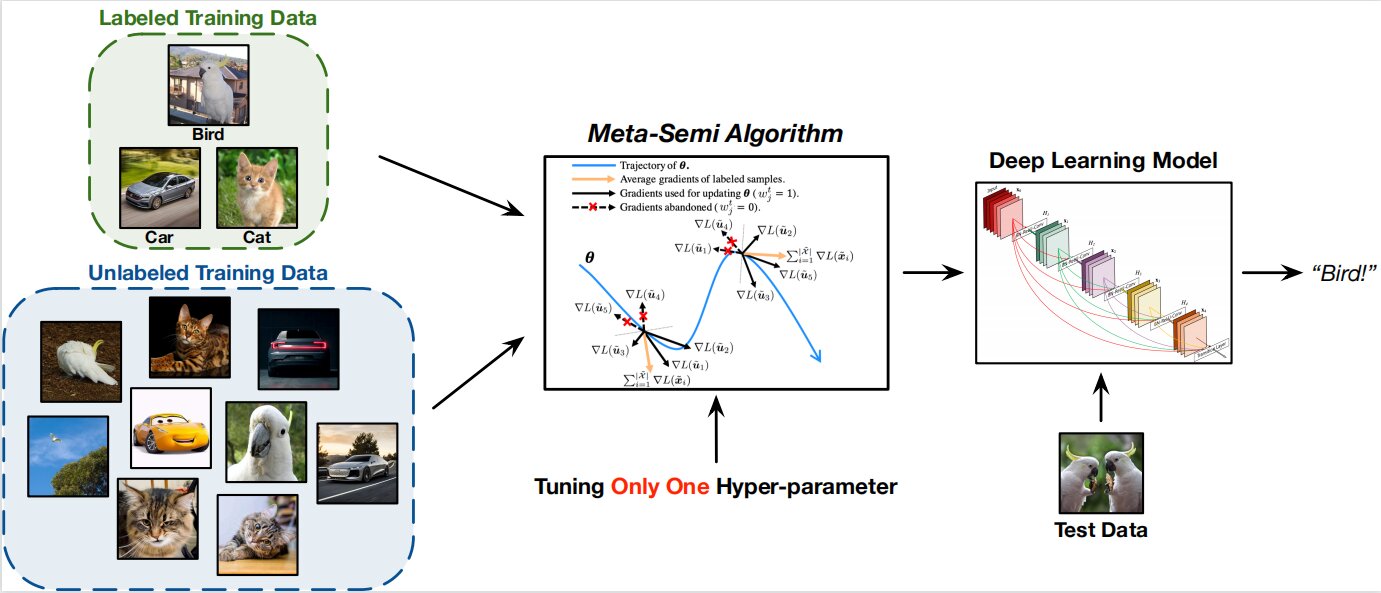
Researchers from Tsinghua College launched a meta-learning-based SSL algorithm known as Meta-Semi to leverage the labeled information extra. Meta-Semi achieves excellent efficiency in lots of eventualities by adjusting only one extra hyper-parameter.
The workforce was impressed by the conclusion that the community could also be skilled efficiently utilizing the appropriately “pseudo-labeled” unannotated examples. Particularly, throughout the on-line coaching section, they produce pseudo-soft labels for the unlabeled information based mostly on the community predictions. Subsequent, they take away the samples with unreliable or incorrect pseudo labels and use the remaining information to coach the mannequin. This work reveals that the distribution of appropriately “pseudo-labeled” information must be akin to that of the labeled information. If the community is skilled with the previous, the ultimate loss on the latter also needs to be minimized.
They outlined the meta-reweighting goal to reduce the ultimate loss on the labeled information by choosing essentially the most acceptable weights (weights all through the paper at all times seek advice from the coefficients used to reweight every unlabeled pattern moderately than referring to the parameters of neural networks). The researchers encountered computing difficulties when tackling this downside utilizing optimization algorithms.
For that reason, they counsel an approximation formulation from which a closed-form answer might be derived. Theoretically, they reveal that every coaching iteration solely wants a single meta gradient step to realize the approximate options.
In conclusion, they counsel a dynamic weighting method to reweight beforehand pseudo-labeled samples with 0-1 weights. The outcomes present that this method finally reaches the stationary level of the supervised loss perform. In well-liked picture classification benchmarks (CIFAR-10, CIFAR-100, SVHN, and STL-10), the proposed method has been proven to carry out higher than state-of-the-art deep networks. For the tough CIFAR-100 and STL-10 SSL duties, Meta-Semi will get a lot greater efficiency than state-of-the-art SSL algorithms like ICT and MixMatch and obtains considerably higher efficiency than them on CIFAR-10. Furthermore, Meta-Semi is a helpful addition to consistency-based approaches; incorporating consistency regularisation into the algorithm additional boosts efficiency.
In line with the researchers, Meta-Semi requires a little bit extra time to coach is a downside. They plan to look into this difficulty sooner or later.
Try the Paper and Reference Article. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t overlook to hitch our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
Tanushree Shenwai is a consulting intern at MarktechPost. She is presently pursuing her B.Tech from the Indian Institute of Expertise(IIT), Bhubaneswar. She is a Knowledge Science fanatic and has a eager curiosity within the scope of software of synthetic intelligence in varied fields. She is keen about exploring the brand new developments in applied sciences and their real-life software.
[ad_2]
Source link
