


[ad_1]
Giant Language Fashions (LLMs) have just lately prolonged their attain past conventional pure language processing, demonstrating vital potential in duties requiring multimodal data. Their integration with video notion talents is especially noteworthy, a pivotal transfer in synthetic intelligence. This analysis takes a large leap in exploring LLMs’ capabilities in video grounding (VG), a vital activity in video evaluation that entails pinpointing particular video segments primarily based on textual descriptions.
The core problem in VG lies within the precision of temporal boundary localization. The duty calls for precisely figuring out the beginning and finish occasions of video segments primarily based on given textual queries. Whereas LLMs have proven promise in varied domains, their effectiveness in precisely performing VG duties nonetheless must be explored. This hole in analysis is what the research seeks to deal with, delving into the capabilities of LLMs on this nuanced activity.
Conventional strategies in VG have diversified, from reinforcement studying strategies that modify temporal home windows to dense regression networks that estimate distances from video frames to the goal section. These strategies, nevertheless, rely closely on specialised coaching datasets tailor-made for VG, limiting their applicability in additional generalized contexts. The novelty of this analysis lies in its departure from these standard approaches, proposing a extra versatile and complete analysis technique.
The researcher from Tsinghua College launched ‘LLM4VG’, a benchmark particularly designed to judge the efficiency of LLMs in VG duties. This benchmark considers two major methods: the primary entails video LLMs educated immediately on text-video datasets (VidLLMs), and the second combines standard LLMs with pretrained visible fashions. These graphical fashions convert video content material into textual descriptions, bridging the visual-textual data hole. This twin method permits for an intensive evaluation of LLMs’ capabilities in understanding and processing video content material.
A deeper dive into the methodology reveals the intricacies of the method. Within the first technique, VidLLMs immediately course of video content material and VG activity directions, outputting predictions primarily based on their coaching on text-video pairs. The second technique is extra complicated, involving LLMs and visible description fashions. These fashions generate textual descriptions of video content material built-in with VG activity directions by fastidiously designed prompts. These prompts are tailor-made to successfully mix the instruction of VG with the given visible description, thus enabling the LLMs to course of and perceive the video content material in regards to the activity.

The efficiency analysis of those methods introduced forth some notable outcomes. It was noticed that VidLLMs, regardless of their direct coaching on video content material, nonetheless lag considerably in reaching passable VG efficiency. This discovering underscores the need of incorporating extra time-related video duties of their coaching for a efficiency enhance. Conversely, combining LLMs with visible fashions confirmed preliminary talents in VG duties. This technique outperformed VidLLMs, suggesting a promising route for future analysis. Nonetheless, the efficiency was primarily constrained by the constraints within the visible fashions and the design of the prompts. The research signifies that extra refined graphical fashions, able to producing detailed and correct video descriptions, might considerably improve LLMs’ VG efficiency.
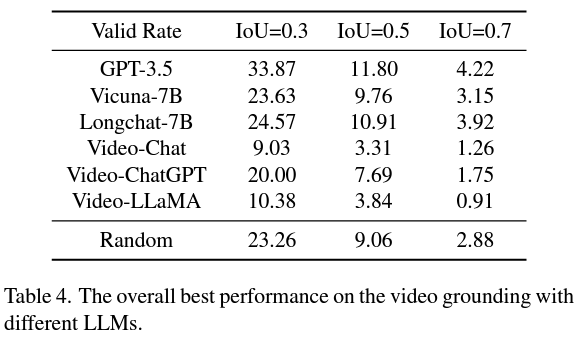
In conclusion, the analysis presents a groundbreaking analysis of LLMs within the context of VG duties, emphasizing the necessity for extra refined approaches in mannequin coaching and immediate design. Whereas present VidLLMs want extra temporal understanding, integrating LLMs with visible fashions opens up new prospects, marking an essential step ahead within the area. The findings of this research not solely make clear the present state of LLMs in VG duties but in addition pave the best way for future developments, probably revolutionizing how video content material is analyzed and understood.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to affix our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a give attention to Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical information with sensible purposes. His present endeavor is his thesis on “Bettering Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.
[ad_2]
Source link
